最近在公司参与公司运维监控平台的建设,用到一些关于监控的第三方开源工具包,在此记录一下。说到运维监控,本人在公司就曾经历过一段痛苦的日子,在某个重要的日子,由于公司没有完善运维监控平台,为保障系统稳定。公司大部分的开发人员和售后全都扑在了服务器和服务状态的监测上,每天的工作就是手动检查上千台服务器和几千个服务的内存,磁盘,CPU使用情况,大概持续了一周左右。因为这些都是重复性的工作,我还记得当时有人提出用跑脚本的方式直接看结果。没想到我们的上级负责人竟然说:“不许使用脚本,这种重要时候我只相信人,不相信脚本”。此言一出,我真的是无力吐槽,人是会累的,机器不会累,竟然还只信人,不信机器。后来想想其实可以理解,他大概是太过紧张了,那段重要日子对于公司来说确实非常重要,出不得差错。不过在经历过那段黑暗的时间后,让我觉得,系统的运维监控必须要有,靠人力运维是一件高成本,低回报,费力不讨好的活。在未接触运维之前,我总认为开发就是一个项目的重中之重,一个优秀的开发者,一个精良的架构设计能使项目的工作事半功倍。但现在我觉得运维才是重点,因为任何一个项目的开发周期是远远小于它的维护周期的,如何低成本的保障系统长期稳定的运行才是最重要的,也是保证用户体验的重要手段 。特别是对于庞大复杂的系统,运维监控系统必不可少。一个成熟完善的运维系统能有效的监测公司服务器和业务系统的异常情况,并马上做出告警大大减小了问题排查的成本。后面公司也意识到了这一点,并开展了运维平台的建设工作,下面就是在工作中总结的一些关于监控开源工具包的使用,以及一些开源的运维监控组件的介绍。

1. Linux监控命令
(1) . top
top命令是最流行Unix/Linux的性能工具之一。它显示所有正在运行而且处于活动状态的实时进程, 而且会定期更新显示结果;它显示了CPU使用率,内存使用率,交换内存使用大小,调整缓存使用大小,缓冲区使用大小,进程PID, 使用的命令等信息。在终端执行top命令后,结果如下:
1 | [root@localhost ~]# top |
这里信息比较多,各个参数的含义如下:
| 资源概况:top行 | |
|---|---|
| 19:01:24 | 系统当前时间,这里是24小时制 |
| up 17 min | 系统开机以后的运行时间,17分钟 |
| 3 users | 系统用户登录在线数量,当前为3人 |
| load average:0.00, 0.04, 0.12 | load average后面三个数分别是1分钟、5分钟、15分钟的负载情况 |
| 运行任务概况:Tasks行 | |
| 162 total | 系统当前的进程数,总共162个进程 |
| 1 running | 正在运行的进程数,当前为1个 |
| 161 sleeping | 睡眠中的进程数,当前睡眠数为161个 |
| 0 stopped | 停止的进程数,当前为0个 |
| 0 zombie | 僵尸进程,当前为0个 |
| CPU概况:Cpu(s)行 | |
| 5.4%us | 用户空间占用CPU时间百分比。多核情况,这个数值表示占用的平均百分比 |
| 3.3%sy | 内核空间占用CPU时间百分比,多核情况同上 |
| 0.0%ni | 用户进程空间内改变过优先级的进程占用CPU时间百分比 |
| 87.8%id | 空闲时间占用CPU百分比,当前为87.8% |
| 3.1%wa | 等待输入输出的CPU时间百分比 |
| 0.0%hi | CPU服务于硬件中断的CPU时间百分比 |
| 0.3%si | CPU服务于软件中断的CPU时间百分比 |
| 0.0%st | 虚拟机占用百分比 |
| 内存概况:Mem行 | |
| 2940796k total | 内存总量,单位kb |
| 2857996k used | 内存使用大小,单位kb |
| 82800k free | 剩余的内存大小,单位kb |
| 13044k buffers | 用于缓冲的内存大小 |
| 交换区概览:Swap行 | |
| 2097144k total | 交换区总量 |
| 0k used | 使用的交换区大小 |
| 2097144k free | 空闲的交换区大小 |
| 1041468k cached | 用于缓冲的交换区大小 |
| 进程概况 | |
| PID | 进程ID,唯一标识 |
| USER | 进程所属用户 |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb. |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SHR | 共享内存大小,意思是这一块内存空间可能也被其他应用程序使用。单位kb |
| %CPU | 自上一次top刷新该进程占用CPU的时间百分比 |
| %MEM | 进程消耗内存百分比 |
| TIME+ | 自进程开始以来,消耗CPU时间,单位1/100秒 |
| S | 进程状态: D:不可中断的睡眠状态;R:运行; S:睡眠; T:跟踪/停止; Z:僵尸进程 |
(2) . free
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。命令执行的结果如下:
1 | [root@localhost ~]# free -m |
下面是各个参数的含义:
| 参数 | 释义 | 数据说明 |
|---|---|---|
| total | 内存总数,物理内存总数 | 总内存大小:2871 kb |
| used | 已经使用的内存数 | 已使用内存:2797 kb |
| free | 空闲的内存数 | 空闲内存大小:74 kb |
| shared | 共享使用的物理内存大小 | 当前已废弃不用内存:0 kb |
| buffers Buffer | 缓存内存数 | 缓存内存大小:13 kb |
| cached Page | 缓存内存数 | 缓存内存大小:844 kb |
| -buffers/cache | 应用使用内存数 | 公式:Mem行的used – buffers – cached |
| +buffers/cache | 应用可用内存数 | 公式:Mem行的free + buffers + cached |
| Swap | 交换分区,虚拟内存 |
对内存来说,buffers/cached 都是属于被使用,所以它认为free只有74kb。我们通过free命令查看机器空闲内存时,会发现free的值很小。这主要是因为,在Linux系统中有这么一种思想,内存不用白不用,因此它尽可能的cache和buffer一些数据,以方便下次使用。但实际上这些内存也是可以立刻拿来给需要的进程使用的。弄清楚参数意义,才能更好的使用这些命令来帮助我们了解服务器状态,开发出更高质量的应用,以为Mem行free内存很少,是不是需要升级服务器内存等等。看内存够不够用重点是要看(-/+ buffers/cache)的free和used为主。可见-buffers/cache反映的是被程序实实在在吃掉的内存,而+buffers/cache反映的是可以挪用的内存总数。对应用程序来讲是(-/+ buffers/cach).buffers/cached 是等同可用的,因为buffer/cached是为了提高程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。这里还需要理解几个名词的含义
buff/cache
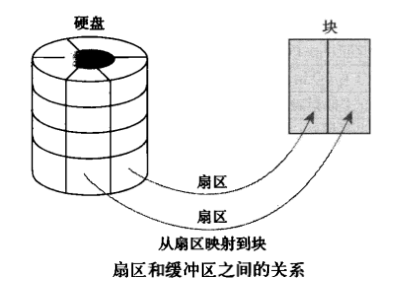
buffer 在操作系统中指 buffer cache, 中文一般翻译为 “缓冲区”。要理解缓冲区,必须明确另外两个概念:”扇区” 和 “块”。扇区是设备的最小寻址单元,也叫 “硬扇区” 或 “设备块”。块是操作系统中文件系统的最小寻址单元,也叫 “文件块” 或 “I/O 块”。每个块包含一个或多个扇区,但大小不能超过一个页面,所以一个页可以容纳一个或多个内存中的块。当一个块被调入内存时,它要存储在一个缓冲区中。buffer cache 只有块的概念而没有文件的概念,它只是把磁盘上的块直接搬到内存中而并不关心文件内容。每个缓冲区与一个块对应,它相当于是磁盘块在内存中的表示:
cache 在操作系统中指 page cache,中文一般翻译为 “页高速缓存”。页高速缓存是内核实现的磁盘缓存。它主要用来减少对磁盘的 I/O 操作。具体地讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问。页高速缓存缓存的是内存页面。缓存中的页来自对普通文件、块设备文件(这个指的就是 buffer cache 呀)和内存映射文件的读写。页高速缓存对普通文件的缓存我们可以这样理解:当内核要读一个文件(比如 /etc/hosts)时,会先检查这个文件的数据是不是已经在页高速缓存中了。如果在,就放弃访问磁盘,从内存中读取。这个行为称为缓存命中。如果数据不在缓存中,就是未命中缓存,此时内核就要调度块 I/O 操作从磁盘去读取数据。然后内核将读来的数据放入页高速缓存中。这种缓存的目标是文件系统可以识别的文件(比如 /etc/hosts)。页高速缓存对块设备文件的缓存就是在前面介绍的 buffer cahce。因为独立的磁盘块通过缓冲区也被存入了页高速缓存(缓冲区最终是由页高速缓存来承载的)。到这里我们应该搞清楚了:无论是缓冲区还是页高速缓存,它们的实现方式都是一样的。缓冲区只不过是一种概念上比较特殊的页高速缓存罢了。那么为什么 free 命令不直接称为 cache 而非要写成 buff/cache? 这是因为缓冲区和页高速缓存的实现并非天生就是统一的。在 linux 内核 2.4 中才将它们统一。更早的内核中有两个独立的磁盘缓存:页高速缓存和缓冲区高速缓存。前者缓存页面,后者缓存缓冲区。当你知道了这些故事之后,输出中列的名称可能已经不再重要了。
Swap
交换分区swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件。所以具体的实现可以是 swap 分区也可以是 swap 文件。当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
现在的机器一般都不太缺内存,如果系统默认还是使用了 swap 是不是会拖累系统的性能?理论上是的,但实际上可能性并不是很大。并且内核提供了一个叫做 swappiness 的参数,用于配置需要将内存中不常用的数据移到 swap 中去的紧迫程度。这个参数的取值范围是 0~100,0 告诉内核尽可能的不要将内存数据移到 swap 中,也即只有在迫不得已的情况下才这么做,而 100 告诉内核只要有可能,尽量的将内存中不常访问的数据移到 swap 中。在 ubuntu 系统中,swappiness 的默认值是 60。如果我们觉着内存充足,可以在 /etc/sysctl.conf 文件中设置 swappiness的值
(3). vmstat
1 | [root@localhost ~]# vmstat 2 |
这表示vmstat每2秒采集数据,一直采集。用来获得有关进程、虚存、页面交换空间及 CPU活动的信息。这些信息反映了系统的负载情况。这里有必要了解一下虚拟内存的运行原理:在系统中运行的每个进程都需要使用到内存,但不是每个进程都需要每时每刻使用系统分配的内存空间。当系统运行所需内存超过实际的物理内存,内核会释放某些进程所占用但未使用的部分或所有物理内存,将这部分资料存储在磁盘上直到进程下一次调用,并将释放出的内存提供给有需要的进程使用。在Linux内存管理中,主要是通过“调页Paging”和“交换Swapping”来完成上述的内存调度。调页算法是将内存中最近不常使用的页面换到磁盘上,把活动页面保留在内存中供进程使用。交换技术是将整个进程,而不是部分页面,全部交换到磁盘上。分页(Page)写入磁盘的过程被称作Page-Out,分页(Page)从磁盘重新回到内存的过程被称作Page-In。当内核需要一个分页时,但发现此分页不在物理内存中(因为已经被Page-Out了),此时就发生了分页错误(Page Fault)。当系统内核发现可运行内存变少时,就会通过Page-Out来释放一部分物理内存。经管Page-Out不是经常发生,但是如果Page-out频繁不断的发生,直到当内核管理分页的时间超过运行程式的时间时,系统效能会急剧下降。这时的系统已经运行非常慢或进入暂停状态,这种状态亦被称作thrashing(颠簸)。下面解释一下各个参数的含义:
| procs | |
|---|---|
| r | 等待执行的任务数(当这个值超过了cpu个数,就会出现cpu瓶颈) |
| b | 等待IO的进程数量 |
| memory | |
| swpd | 虚拟的内存,单位kb |
| free | 空闲内存大小 |
| buff | 已用的buff大小,对块设备的读写进行缓冲 |
| cache | 已用的cache大小,文件系统的cache |
| inact | 非活跃内存大小 |
| active | 活跃的内存大小 |
| swap | |
| si | 每秒从交换区写入内存的大小(单位:kb/s) |
| so | 每秒从内存写到交换区的大小(单位:kb/s) |
| io | |
| bi | 每秒读取的块数(读磁盘),现在的Linux版本块的大小为1024bytes |
| bo | 每秒写入的块数(写磁盘) |
| system | |
| in | 每秒中断数,包括时钟中断(in和cs值越大,会看到由内核消耗的cpu时间会越多) |
| cs | 每秒上下文切换数(in和cs值越大,会看到由内核消耗的cpu时间会越多) |
| cpu | |
| us | 用户进程执行消耗cpu时间(user time) |
| sy | 系统进程消耗cpu时间(system time) |
| id | 空闲时间(包括IO等待时间) |
| wa | 等待IO时间(Wa过高时,说明io等待比较严重,可能是由于磁盘大量随机访问造成的,也可能是磁盘的带宽出现瓶颈) |
(4). iostat
iostat是I/O statistics(输入/输出统计)的缩写,iostat命令查看系统的IO请求数量、系统处理IO请求的耗时,进而分析进程与操作系统的交互过程中IO方面是否存在瓶颈。同时也会汇报出CPU使用情况。同vmstat一样,iostat也有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。iostat常用命令格式如下:
1 | iostat [参数] [时间] [次数] |
执行iostat -x命令,会得到如下结果。如果command not found可通过yum 来安装,安装命令如下yum install sysstat
1 | [root@centos1 ~]# iostat -x |
输出内容详解:
| avg-cpu | |
|---|---|
| %user | CPU处在用户模式下的时间百分比 |
| %nice | CPU处在带NICE值的用户模式下的时间百分比 |
| %system | CPU处在系统模式下的时间百分比 |
| %iowait | CPU等待输入输出完成时间的百分比 |
| %steal | 管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比 |
| %idle | CPU空闲时间百分比 |
| Device | |
| rrqm/s | 每秒进行 merge 的读操作数目。即 rmerge/s |
| wrqm/s | 每秒进行 merge 的写操作数目。即 wmerge/s |
| r/s | 每秒完成的读 I/O 设备次数。即 rio/s |
| w/s | 每秒完成的写 I/O 设备次数。即 wio/s |
| rsec/s | 每秒读扇区数。即 rsect/s |
| wsec/s | 每秒写扇区数。即 wsect/s |
| rkB/s | 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。 |
| wkB/s | 每秒写K字节数。是 wsect/s 的一半。 |
| avgrq-sz | 平均每次设备I/O操作的数据大小 (扇区)。 |
| avgqu-sz | 平均I/O队列长度。 |
| await | 平均每次设备I/O操作的等待时间 (毫秒)。 |
| r_await | 每个读操作平均所需时间;不仅包括硬盘设备读操作时间,还包括了在kernel队列中的等待时间 |
| w_await | 每个写操作平均所需时间;不仅包括硬盘设备写操作时间,还包括了在kernel队列中的等待时间 |
| svctm | 平均每次设备I/O操作的服务时间 (毫秒)。 |
| %util | 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比。如果该参数是100%表示设备已经接近满负荷运行了,该磁盘可能存在瓶颈 |
说明:如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有大量io在等待。网上有个形象的比喻来理解这些属性:
- r/s+w/s 类似于交款人的总数
- 平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
- 平均服务时间(svctm)类似于收银员的收款速度
- 平均等待时间(await)类似于平均每人的等待时间
- 平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
- I/O 操作率 (%util)类似于收款台前有人排队的时间比例
设备IO操作:总IO(io)/s = r/s(读) +w/s(写)
打赏一个呗