MVCC全称Multi-Version Concurrency Control,即多版本并发控制,主要是为了提高数据库的并发性能。对存储引擎的MVCC机制,早有涉猎学习。但如果在工作中生活中没有足够的经历,其实很难对它有深入的理解。为什么要有MVCC机制?它解决了什么问题?存储引擎到底帮我们做了什么?
我理解存储引擎主要帮我们做了两件事
- 高性能的读写数据(通过索引实现)
- 保障数据的正确性(通过事务实现)
事务可以使「一组操作」要么全部成功,要么全部失败。最常见的场景就是转账。例如我给你发支付宝转了888块红包。那自然我的支付宝余额会扣减888块,你的支付宝余额会增加888块,事务就是保证我的余额扣减跟你的余额增添是同时成功或者同时失败的,这样这次转账就正常了
数据库并发场景
并发情况下,多线程会竞争操作数据,主要有以下几种情况
读-读:不存在任何问题,也不需要并发控制读-写:有线程安全问题,可能会造成事务隔离性问题,可能遇到脏读,幻读,不可重复读写-写:有线程安全问题,可能会存在更新丢失问题
MVCC解决并发哪些问题?
在数据库操作中普遍存在对一条数据同时读写的情况,但没有事务时,读线程可能会读到别人没有提交的数据而产生脏读。解决这个问题简单的方式就是读写互斥,但这样就降低了并发性。因此就出现了mvcc机制,所以mvcc是用来解决读—写冲突的无锁并发控制,这里又引入了事务隔离级别的概念,都是环环相扣的。
为了讲清楚隔离级别,需要先了解MySQL锁相关的知识。在InnoDB引擎下,按锁的粒度分类,可以简单分为行锁和表锁。行锁实际上是作用在索引之上的。当我们的SQL命中了索引,那锁住的就是命中条件内的索引节点(这种就是行锁),如果没有命中索引,那我们锁的就是整个索引树(表锁)。简单来说就是:锁住的是整棵树还是某几个节点,完全取决于SQL条件是否有命中到对应的索引节点。
而行锁又可以简单分为读锁(共享锁、S锁)和写锁(排它锁、X锁)。读锁是共享的,多个事务可以同时读取同一个资源,但不允许其他事务修改。写锁是排他的,写锁会阻塞其他的写锁和读锁。
在MVCC下,可以做到读写不阻塞,且避免了类似脏读这样的问题。那MVCC是怎么做的呢?MVCC通过生成数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。回到事务隔离级别下,针对于 read commit (读已提交) 隔离级别,它生成的就是语句级快照,而针对于repeatable read (可重复读),它生成的就是事务级的快照。
前面提到过read uncommit隔离级别下会产生脏读,而read commit (读已提交) 隔离级别解决了脏读。思想其实很简单:在读取的时候生成一个版本号,等到其他事务commit了之后,才会读取最新已commit的版本号数据。比如说:事务A读取了记录(生成版本号),事务B修改了记录(此时加了写锁),事务A再读取的时候,是依据最新的版本号来读取的(当事务B执行commit了之后,会生成一个新的版本号),如果事务B还没有commit,那事务A读取的还是之前版本号的数据。通过「版本」的概念,这样就解决了脏读的问题,而「版本」其实就是对应快照的数据。
MVCC没有解决的问题
并发读-写时:可以做到读操作不阻塞写操作,同时写操作也不会阻塞读操作。也解决了脏读、幻读、不可重复读等事务隔离问题,但没有解决上面的写-写 更新丢失问题。
写-写更新丢失场景(脏写)
事务A和事务B都对一行数据进行更新,更新前是Null,事务A更新后是数据是A,此时undo日志里有一条记录比如 XX数据更新之前的值是Null;然后事务B将数据更新为B,在这个时候事务A突然回滚了,此时这一行数据根据undo日志将值从B变成Null了,事务B就会发现他更新的值变成Null了。
因此有了下面提高并发性能的组合拳:
MVCC + 悲观锁:MVCC解决读写冲突,悲观锁解决写写冲突MVCC + 乐观锁:MVCC解决读写冲突,乐观锁解决写写冲突
MVCC的实现原理
它的实现原理主要是版本链,undo日志 ,Read View来实现的
版本链
我们数据库中的每行数据,除了我们肉眼看见的数据,还有几个隐藏字段,得开天眼才能看到。分别是trx_id、db_roll_pointer。
- trx_id(事务ID):6byte,最近修改(修改/插入)
事务ID:记录创建这条记录/最后一次修改该记录的事务ID。 - roll_pointer(版本链关键):7byte,
回滚指针,指向这条记录的上一个版本(存储于rollback segment里)
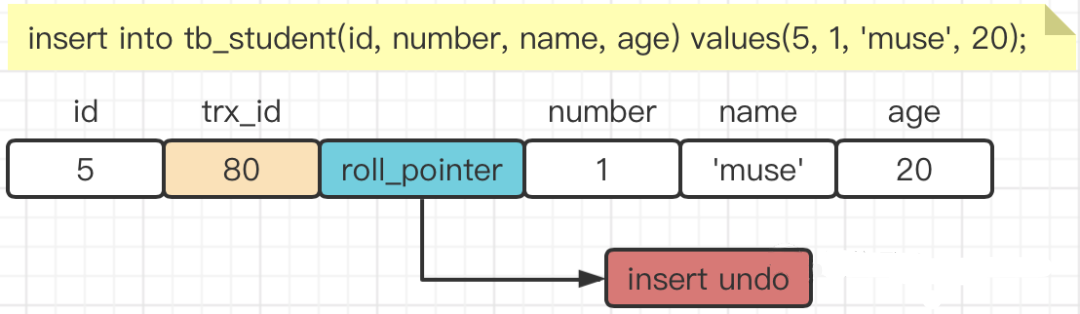
如上图,trx_id是当前操作该记录的事务ID,而roll_pointer是一个回滚指针,用于配合undo日志,指向上一个旧版本。
每次对数据库记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,所以现在的情况就像下图一样:

对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id(trx_id),这个信息很重要,在根据ReadView判断版本可见性的时候会用到。



