布隆过滤器在wiki上的介绍:
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难
对于布隆过滤器我早有了解,但在工作当中没有实际使用过,因此对他的理解仅停留在理论层面。直到最近我朋友在公司遇到一个问题,就是他们系统会有不存在的新用户发过来的请求(可理解为游客的场景),绕过了缓存直接打在数据库的场景。当时我也没想到好的方案,查阅资料发现可以用布隆过滤器来解决。于是决定重新梳理一下布隆过滤器
事实上,布隆过滤器被广泛用于网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统以及解决缓存穿透问题。通过介绍已经知晓布隆过滤器的作用是检索一个元素是否在集合中。可能有人认为这个功能非常简单,直接放在redis中或者数据库中查询就好了。又或者当数据量较小,内存又足够大时,使用hashMap或者hashSet等结构就好了。但是如果当这些数据量很大,数十亿甚至更多,内存装不下且数据库检索又极慢的情况,我们应该如何去处理?这个时候我们不妨考虑下布隆过滤器,因为它是一个空间效率占用极少和查询时间极快的算法,但是需要业务可以忍受一个判断失误率。
布隆过滤器判定的结论:要判断一个数存在或者不存在时,如果布隆过滤器说这个数不存在则一定不存;如果隆过滤器说这个数存在,则可能存在,也可能不存在(即误判)。
这非常适用我朋友碰到的那种游客访问的场景,实际上就是解决Redis缓存穿透问题。
布隆过滤器的原理
布隆过滤器它实际上是一个很长的二进制向量和一系列随机映射函数。以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。

多个无偏hash函数:
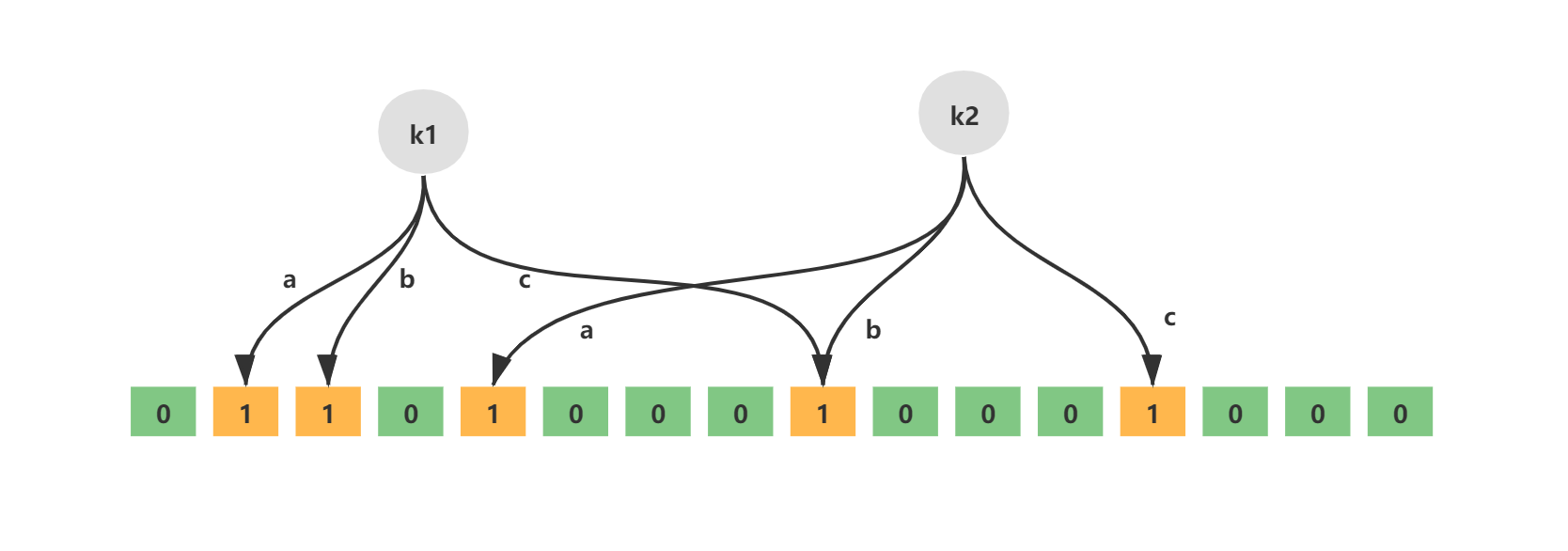
无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。
空间计算
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。这里一个免费的在线布隆过滤器在线计算的网址
它们之间的关系比较简单:
- 错误率越低,位数组越长,控件占用较大
- 错误率越低,无偏hash函数越多,计算耗时较长
增加元素
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 将计算得到的数组索引下标位置数据修改为1
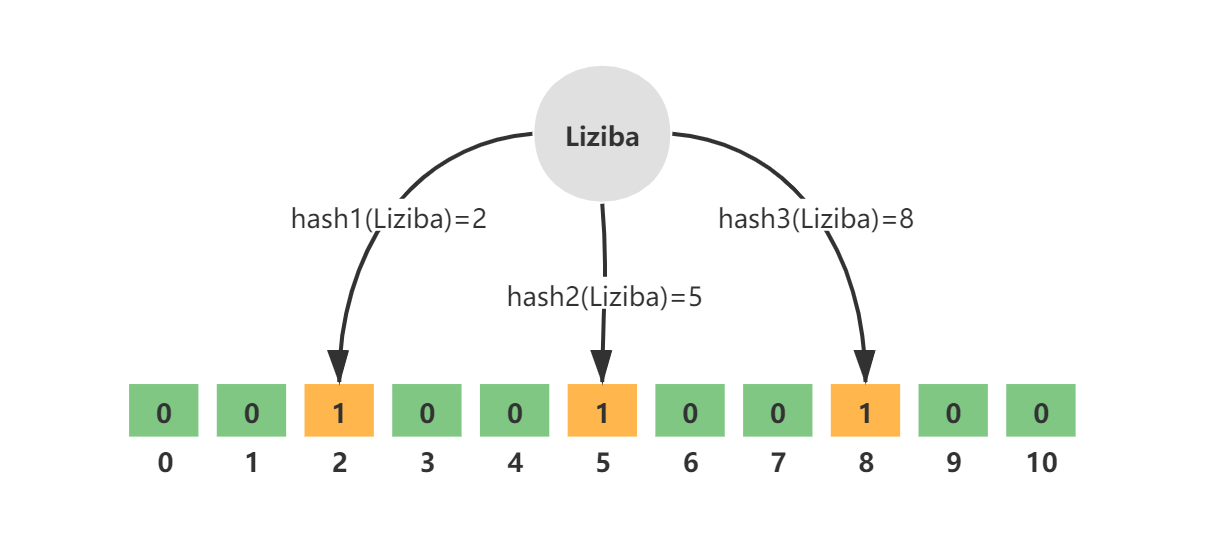
例如,key = Liziba,无偏hash函数的个数k=3,分别为hash1、hash2、hash3。三个hash函数计算后得到三个数组下标值,并将其值修改为1。如图所示
查询元素
布隆过滤器最大的用处就在于判断某样东西一定不存在或者可能存在,而这个就是查询元素的结果。其查询元素的过程如下
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
关于误判,其实非常好理解,hash函数在怎么好,也无法完全避免hash冲突,也就是说可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的到的数组索引也是相同的,这就是误判的原因。
Java集成Redis使用布隆过滤器
Redis经常会被问道缓存击穿问题,比较优秀的解决办法是使用布隆过滤器,也有使用空对象解决的,但是最好的办法肯定是布隆过滤器,我们可以通过布隆过滤器来判断元素是否存在,避免缓存和数据库都不存在的数据进行查询访问!在如下的代码中只要通过bloomFilter.contains(xxx)即可,我这里演示的还是误判率!
引入pom依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.0</version>
</dependency>编写测试代码
package com.lizba.bf;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
/**
* <p>
* Java集成Redis使用布隆过滤器防止缓存穿透方案
* </p>
*
* @Author: Liziba
* @Date: 2021/8/29 16:13
*/
public class RedisBloomFilterTest {
/** 预计插入的数据 */
private static Integer expectedInsertions = 10000;
/** 误判率 */
private static Double fpp = 0.01;
public static void main(String[] args) {
// Redis连接配置,无密码
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.211.108:6379");
// config.useSingleServer().setPassword("123456");
// 初始化布隆过滤器
RedissonClient client = Redisson.create(config);
RBloomFilter<Object> bloomFilter = client.getBloomFilter("user");
bloomFilter.tryInit(expectedInsertions, fpp);
// 布隆过滤器增加元素
for (Integer i = 0; i < expectedInsertions; i++) {
bloomFilter.add(i);
}
// 统计元素
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions*2; i++) {
if (bloomFilter.contains(i)) {
count++;
}
}
System.out.println("误判次数" + count);
}
}


