时间轮算法在很多开源的中间件被广泛应用, Redisson 分布式锁中使用时间轮算法实现看门狗,来为锁续时。另一个场景是使用时间轮算法来实现心跳续时,在使用长连接的时候,我们通常需要使用心跳机制来防止意外断开的无效连接浪费系统资源。心跳机制的实现常用的有两种:
- 第一:每一个客户端连接上时,就创建一个定时器,如果在指定时间内没有收到客户端发来的心跳,那么该定时器就将连接断开。如果收到,则重置定时器,重新计时。但是在连接数量上万,甚至数十万百万时,定时器的数量也将有数十万甚至百万个,极大的耗费系统资源,甚至拖垮整个系统,因此这种方式适用于连接数量不多的情况。
- 第二:使用时间轮片(Timing Wheel)算法来实现心跳。
时间轮
简单来说: 时间轮是一种高效利用线程资源进行批量化调度的一种调度模型。把大批量的调度任务全部绑定到同一个调度器上,使用这一个调度器来进行所有任务的管理、触发、以及运行。所以时间轮的模型能够高效管理各种延时任务、周期任务、通知任务。具体实现如下:
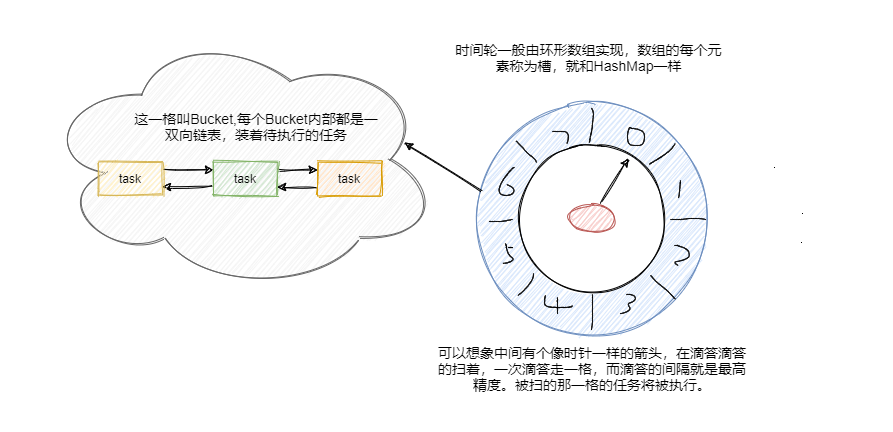
在Netty 中针对 I/O 超时调度的场景进行了优化,实现了 HashedWheelTimer 时间轮算法。HashedWheelTimer 是一个环形结构,可以用时钟来类比,钟面上有很多 bucket ,每一个 bucket 上可以存放多个任务,使用一个 List 保存该时刻到期的所有任务,同时一个指针随着时间流逝一格一格转动,并执行对应 bucket 上所有到期的任务。任务通过 取模决定应该放入哪个 bucket 。和 HashMap 的原理类似,newTask 对应 put,使用 LinkedList 来解决 Hash 冲突。
以上图为例,假设一个 bucket 是 1 秒,则指针转动一轮表示的时间段为 8s,假设当前指针指向 0,此时需要调度一个 3s 后执行的任务,显然应该加入到 (0+3=3) 的方格中,指针再走 3 次就可以执行了;如果任务要在 10s 后执行,应该等指针走完一轮零 2 格再执行,因此应放入 2,同时将 round(1)保存到任务中。检查到期任务时只执行 round 为 0 的, bucket 上其他任务的 round 减 1。
这样只需要一个线程就可以实现全部定时任务的触发,而不是一个定时任务就需要一个线程去轮询
层级时间轮
Kafka 针对时间轮算法进行了优化,实现了层级时间轮 TimingWheel。先简单介绍一下,层级时间轮就是相当于时针分针秒针,秒针转动一圈,分针就走了一个bucket。层级适合时间跨度较大时存在明显优势。
如果任务的时间跨度很大,数量也多,传统的 HashedWheelTimer 会造成任务的 round 很大,单个 bucket 的任务 List 很长,并会维持很长一段时间。这时可将轮盘按时间粒度分级。
时间轮的设计思想类似于我们生活中的手表。手表由时针、分针和秒针组成,它们各自有独立的刻度,但又彼此相关:秒针转动一圈,分针会向前推进一格;分针转动一圈,时针会向前推进一格。这就是典型的分层时间轮。和手表不太一样的是,Kafka 自己有专门的术语。在 Kafka 中,手表中的“一格”叫“一个桶(Bucket)”,而“推进”对应于 Kafka 中的“滴答”,也就是 tick。后面你在阅读源码的时候,会频繁地看到 Bucket、tick 字眼,你可以把它们理解成手表刻度盘面上的“一格”和“向前推进”的意思。除此之外,每个 Bucket 下也不是白板一块,它实际上是一个双向循环链表(Doubly Linked Cyclic List),里面保存了一组延时请求。
时间轮的使用
这里使用的时间轮是Netty这个包中提供的,使用方法比较简单。先构建一个HashedWheelTimer时间轮。
- tickDuration: 100 ,表示每个时间格代表当前时间轮的基本时间跨度,这里是100ms,也就是指针100ms跳动一次,每次跳动一个窗格
- ticksPerWheel:1024,表示时间轮上一共有多少个窗格,分配的窗格越多,占用内存空间就越大
- leakDetection:是否开启内存泄漏检测。
- maxPendingTimeouts[可选参数],最大允许等待的任务数,默认没有限制。
通过newTimeout()把需要延迟执行的任务添加到时间轮中
@RestController
public class RedissonController {
@Autowired
RedissonClient redissonClient;
HashedWheelTimer hashedWheelTimer= new HashedWheelTimer(new DefaultThreadFactory("demo-timer"), 100, TimeUnit.MILLISECONDS, 1024, false);
/**
* 添加延迟任务
* @param delay
*/
@GetMapping("/{delay}")
public void tick(@PathVariable("delay")Long delay){
System.out.println("currentDate:"+new Date());
hashedWheelTimer.newTimeout(timeout -> {
System.out.println("executeDate:"+new Date());
}, delay, TimeUnit.SECONDS);
}
}时间轮的功能
- 可以添加指定时间的延时任务,每个任务都是task抽象的父类,每个任务都放在环形object类型数组中,在这个任务中可以实现自己的业务逻辑。
- 有一个触发任务,实际上是一个线程,主要作用是相当于按时遍历时间轮每个节点,查看是否到时间执行,就相当于表针运行状态触发执行任务,这里就是TriggerJob。
- 停止运行(包含强制停止和所有任务完成后停止)。
- 查看待执行任务数量。
总结
时间轮算法相比于简单的轮询数组,避免了一些无效的轮询。因为时间轮算法的每次触发就相当于时钟的指针往前走了一个单元时间(PS :单元时间自己定义,可以是毫秒,秒,分,时,想一想圆形钟表的秒针,分针,时针。当场景复杂时,可以实现多层级的时间轮)。



