分布式锁的实现有多种方式,但是不管怎样,设计分布式锁一般要满足以下条件:
- 互斥性:任意时刻,只能有一个客户端获取锁,不能同时有两个客户端获取到锁。
- 安全性:锁只能被持有该锁的客户端删除,不能由其它客户端删除。
- 避免死锁:分布式锁一定能得到释放,即使client在释放之前崩溃或者网络不可达
- 可重入性:很好理解,持有锁的节点,可以重复持有锁。
分布式锁一般有三种实现方式
- 基于数据库DB乐观锁
- 基于ZooKeeper的分布式锁
- 基于Redis的分布式锁
DB锁
在数据库新建一张表用于控制并发控制,表结构可以如下所示:
CREATE TABLE `lock_table` (
`id` int(11) unsigned NOT NULL COMMENT '主键',
`key_id` bigint(20) NOT NULL COMMENT '分布式key',
`memo` varchar(43) NOT NULL DEFAULT '' COMMENT '可记录操作内容',
`update_time` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id`,`key_id`),
UNIQUE KEY `key_id` (`key_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;key_id作为分布式key用来并发控制,memo可用来记录一些操作内容(比如memo可用来支持重入特性,标记下当前加锁的client和加锁次数)。将key_id设置为唯一索引,保证了针对同一个key_id只有一个加锁(数据插入)能成功。此时lock和unlock伪代码如下
def lock :
exec sql: insert into lock_table(key_id, memo, update_time) values (key_id, memo, NOW())
if result == true :
return true
else :
return false
def unlock :
exec sql: delete from lock_table where key_id = 'key_id' and memo = 'memo'需要注意的是,伪代码中的lock操作是非阻塞锁,也就是tryLock,如果想实现阻塞(或者阻塞超时)加锁,只修反复执行lock伪代码直到加锁成功为止即可。基于DB的分布式锁其实有一个问题,那就是如果加锁成功后,client端宕机或者由于网络原因导致没有解锁,那么其他client就无法对该key_id进行加锁并且无法释放了。为了能够让锁失效,需要在应用层加上定时任务,去删除过期还未解锁的记录,比如删除2分钟前未解锁的伪代码如下:
def clear_timeout_lock :
exec sql : delete from lock_table where update_time < ADDTIME(NOW(),'-00:02:00')但这仍然存在问题,当应用宕机时,定时任务没有执行,还是会出现锁没有释放的情况,造成死锁,因此还需要增加一个表用来记录锁释放的结果,定时从结果表中查出没有释放的锁记录,把锁释放掉
因为单实例DB的TPS一般为几百,所以基于DB的分布式性能上限一般也是1k以下,一般在并发量不大的场景下该分布式锁是满足需求的,不会出现性能问题。不过DB作为分布式锁服务需要考虑单点问题,对于分布式系统来说是不允许出现单点的,一般通过数据库的同步复制,以及使用vip切换Master就能解决这个问题。以上DB分布式锁是通过insert来实现的,如果加锁的数据已经在数据库中存在,那么用select xxx where key_id = xxx for udpate方式来做也是可以的。
Redis锁
从redis2.6.12开始,redis的set命令支持以下三个步骤为原子操作:1)判断key是否存在,2)不存在则设置值,3)设置key的过期时间。因此,通过这个命令就可以实现分布式锁,原理与数据库主键类似,而且redis可以设置key的过期时间,解决了数据库主键方案带来的死锁问题。命令如下
// 命令行
set key_id key_value NX PX expireTime
// 代码
jedis.set(keys,args,"NX","PX",30000)其中,set nx命令只会在key不存在时给key进行赋值,px用来设置key过期时间,key_value一般是随机值,用来保证释放锁的安全性(释放时会判断是否是之前设置过的随机值,只有是才释放锁)。由于资源设置了过期时间,一定时间后锁会自动释放。
set nx保证并发加锁时只有一个client能设置成功(Redis内部是单线程,并且数据存在内存中,也就是说redis内部执行命令是不会有多线程同步问题的),此时的lock/unlock伪代码如下
def lock:
if (redis.call('set', KEYS[1], ARGV[1], 'ex', ARGV[2], 'nx')) then
return true
end
return false
def unlock:
if (redis.call('get', KEYS[1]) == ARGV[1]) then
redis.call('del', KEYS[1])
return true
end
return false分布式锁服务中的一个问题:如果一个获取到锁的client因为某种原因导致没能及时释放锁,并且redis因为超时释放了锁,另外一个client获取到了锁,那么如何解决这个问题呢,一种方案是引入锁续约机制,也就是获取锁之后,释放锁之前,会定时进行锁续约,比如以锁超时时间的1/3为间隔周期进行锁续约
关于开源的redis的分布式锁实现有很多,比较出名的有redisson、百度的dlock,关于分布式锁的续约,redisson中使用了 watch dog 机制。
Redis锁具有过期时间,但是锁保护的同步代码块在不同条件下的执行时间是不一样的,如果过期时间设置较短,则会导致同步代码块还没有执行完,锁就被回收了。如果过期时间设置的很长,又会导致服务宕机后,其他线程等待锁的时间变的很长,由此可能导致线程资源全部无法释放,而源源不断的新请求在队列堆积,大量请求超时响应等。Redis采用的是主从同步的方式保证高可用性,劣势就是由于数据在内存中,一旦主节点宕机,从节点被启用,如果宕机时,锁的信息正好没有同步从节点成功,则会丢失锁的信息。
zookeeper分布式锁
ZooKeeper是一个高可用的分布式协调服务,由雅虎创建,是Google Chubby的开源实现。ZooKeeper提供了一项基本的服务:分布式锁服务。zookeeper重要的3个特征是:zab协议、node存储模型和watcher机制。通过zab协议保证数据一致性,zookeeper集群部署保证可用性,node存储在内存中,提高了数据操作性能,使用watcher机制,实现了通知机制(比如加锁成功的client释放锁时可以通知到其他client)。
zookeeper node模型支持临时节点特性,即client写入的数据时临时数据,当客户端宕机时临时数据会被删除,这样就不需要给锁增加超时释放机制了。当针对同一个path并发多个创建请求时,只有一个client能创建成功,这个特性用来实现分布式锁。注意:如果client端没有宕机,由于网络原因导致zookeeper服务与client心跳失败,那么zookeeper也会把临时数据给删除掉的,这时如果client还在操作共享数据,是有一定风险的。
基于zookeeper实现分布式锁,相对于基于redis和DB的实现来说,使用上更容易,效率与稳定性较好。curator封装了对zookeeper的api操作,同时也封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等,使用curator进行分布式加锁示例如下:
<!--引入依赖-->
<!--对zookeeper的底层api的一些封装-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<!--封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>Java代码实现
public static void main(String[] args) throws Exception {
String lockPath = "/curator_recipes_lock_path";
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("192.168.193.128:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();
client.start();
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
Runnable task = () -> {
try {
lock.acquire();
try {
System.out.println("zookeeper acquire success: " + Thread.currentThread().getName());
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.release();
}
} catch (Exception ex) {
ex.printStackTrace();
}
};
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < 1000; i++) {
executor.execute(task);
}
LockSupport.park();
}
在此之前的所有方案,在服务获取锁失败的时候,都只能采用自旋等待获取锁,或者放弃锁,而不能像Java进程内的锁,可以加入等待队列中,当锁的持有者释放锁以后,自动被唤醒获取锁。不过,利用zookeeper有序节点的特性,就可以实现获取锁失败后,加入等待队列,当持有锁的服务释放锁后,则被唤醒获取锁。如下图所示,
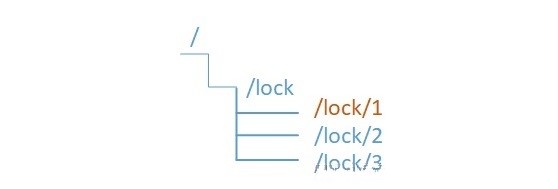
- 试图获取锁的节点同时在zookeeper上相同的父路径下创建有序节点,值最小的获取锁成功
- 获取锁失败的服务进入阻塞直到自己成为最小值
- 后面的节点监听前面的节点,一旦前面的节点释放锁,则自己进行获取锁操作
public boolean tryDistributedLock(ZkClient zkClient, String lockKey, String lockVal) {
String rootNode = "/lock/" + lockKey;
String data = lockVal;
try {
String myNode = createNode(zkClient, rootNode + "/", data, CreateMode.EPHEMERAL_SEQUENTIAL);
//取出所有子节点,如果是最小的节点,则表示取得锁
List<String> subNodes = zkClient.getChildren(rootNode);
Collections.sort(subNodes);
if (myNode.equals(subNodes.get(0))) {
return true;
}
System.out.println("lock have been hold!");
//如果不是最小的节点,找到比自己小1的节点
int i = 0;
for (String subNode : subNodes) {
if (subNode.equals(myNode)) {
break;
}
i++;
}
//监听自己的上一个节点,如果它释放锁了,则自己进入抢锁流程
waitNode = subNodes.get(i-1);
zkClient.subscribeDataChanges(waitNode, this);
return false;
} catch (Exception e) {
System.out.println("System error" + e.getMessage());
return false;
}
}
//监听类的方法
@Override
public void handleDataDeleted(String dataPath) throws Exception {
tryDistributedLock(zkClient, lockKey, lockVal);
}从上面介绍的3种分布式锁的设计与实现中,我们可以看出每种实现都有各自的特点,针对潜在的问题有不同的解决方案,归纳如下:
- 性能:redis > zookeeper > db
- 避免死锁:DB通过应用层设置定时任务来删除过期还未释放的锁,redis通过设置超时时间来解决,而zookeeper是通过临时节点来解决。
- 可用性:DB可通过数据库同步复制,vip切换master来解决,redis可通过集群或者master-slave方式来解决,zookeeper本身自己是通过zab协议集群部署来解决的。注意,DB和redis的复制一般都是异步的,也就是说某些时刻分布式锁发生故障可能存在数据不一致问题,而zookeeper本身通过zab协议保证集群内(至少n/2+1个)节点数据一致性。
- 锁唤醒:DB和redis分布式锁一般不支持唤醒机制(也可以通过应用层自己做轮询检测锁是否空闲,空闲就唤醒内部加锁线程),zookeeper可通过本身的watcher/notify机制来做。
使用分布式锁,安全性上和多线程(同一个进程内)加锁是没法比的,可能由于网络原因,分布式锁服务(因为超时或者认为client挂了)将加锁资源给删除了,如果client端继续操作共享资源,此时是有隐患的。因此,对于分布式锁,一个是尽量提高分布式锁服务的可用性,另一个就是要部署同一内网,尽量降低网络问题发生几率。这样来看,貌似分布式锁服务不是“完美”的。技术貌似也不好做到十全十美 ,最好是结合自己的业务实际场景,来选择不同的分布式锁实现,一般来说,基于redis的分布式锁服务应用较多。



