领域模型是对领域内的概念类或现实世界中对象的可视化表示。又称概念模型、领域对象模型、分析对象模型。它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。
业务对象模型(也叫领域模型domain model)是描述业务用例实现的对象模型。它是对业务角色和业务实体之间应该如何联系和协作以执行业务的一种抽象。业务对象模型从业务角色内部的观点定义了业务用例。该模型为产生预期效果确定了业务人员以及他们处理和使用的对象(“业务类和对象”)之间应该具有的静态和动态关系。它注重业务中承担的角色及其当前职责。这些模型类的对象组合在一起可以执行所有的业务用例。领域模型分为4大类:失血模型、贫血模型、充血模型、胀血模型。这类理论都是些软件设计领域的大牛(如Martin Fowler)提出来的,有其背景和原因。想要理解这几个分类,先要知道“血”指的是domain object的model层内容。
失血模型
失血模型中,domain object只有属性的get set方法的纯数据类,所有的业务逻辑完全由Service层来完成的
- service: 肿胀的服务逻辑
- model:只包含get, set方法
显然失血模型service层负担太重,一般不会有这种设计。
贫血模型
贫血模型中,domain ojbect包含了不依赖于持久化的原子领域逻辑,而组合逻辑在Service层。
- service :组合服务,也叫事务服务
- model:除包含get set方法,还包含原子服务
- dao:数据持久化
充血模型
充血模型中,绝大多业务逻辑都应该被放在domain object里面,包括持久化逻辑,而Service层是很薄的一层,仅仅封装事务和少量逻辑,不和DAO层打交道。
- service :组合服务 也叫事务服务
- model:除包含get set方法,还包含原子服务和数据持久化的逻辑
胀血模型
胀血模型取消了Service层,只剩下domain object和DAO两层,在domain object的domain logic上面封装事务。
一般来说失血模型和胀血模型不常见,多采用贫血模型。我们日常开发在Spring框架中基本是用的贫血模型,因为在代码中,无论是与数据库映射的Entity,还是定义的方法参数Dto,都是只有属性和get,set方法。例如一个User类
@Data
public class User {
private Long id;
private String name;
private int age;
}get,set方法也会使用Lombok插件生成,所有的业务逻辑全放在了Service层。乍一看,这种模式有模有样:数据库表通过映射建造一些 ORM 类,各类之间存在一定的关系,而且还使用了服务层(Service layer)进行分层管理。
但是让我们仔细想想。User 类无非一些 getter 和 setter,符合了领域模型包含数据的标准,却缺失了最重要的部分:行为。而将业务逻辑放入服务类(Service class)中,形成了一种类似于事务处理脚本的面向过程的编程方式,与领域模型所倡导的面向对象编程背道而驰。在面向对象的编程范式中,一个对象是高内聚的,一个User不应该仅仅只有属性,应该还有他自己的方法,比如 eat(),cry()。而在贫血模式中,这些本该是User具有的行为,却被抽离放到了UserService里了,User类本身只充当了一个存放数据的结构体。
为什么贫血模型如此流行?
- 大部分情况下,我们开发的系统业务可能都比较简单,简单到就是基于SQL 的 CRUD 操作,所以,我们根本不需要动脑子精心设计充血模型,贫血模型就足以应付这种简单业务的开发工作。
- 充血模型的设计要比贫血模型更加有难度。因为充血模型是一种面向对象的编程风格。我们从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。而不是像贫血模型那样,我们只需要定义数据,之后有什么功能开发需求,我们就在 Service 层定义什么操作,不需要事先做太多设计。
- 思维已固化,转型有成本
由于失血模型和胀血模型基本上不会使用,主要了解一下贫血模型和充血模型的区别
贫血模型
贫血模型是指领域对象里只有get和set方法(POJO)和少量的原子方法,所有的业务逻辑都不包含在内而是放在Business Logic层
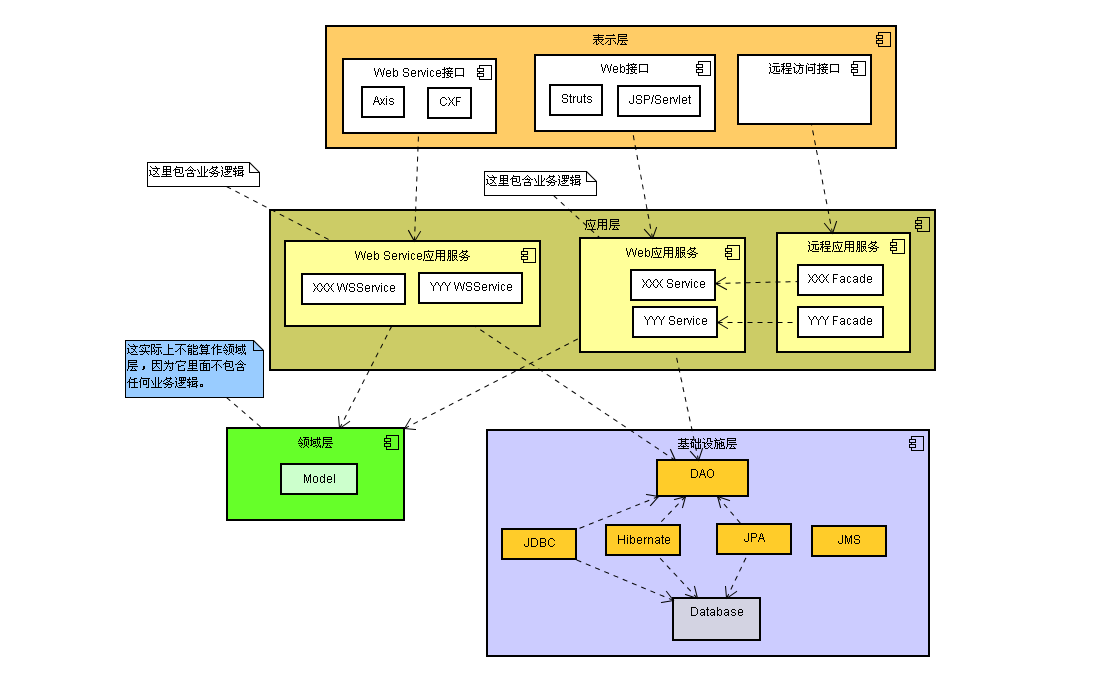
优点是系统的层次结构清楚,各层之间单向依赖,Client->(BusinessFacade)->BusinessLogic->Data Access Object。可见,领域对象几乎只作传输介质之用,不会影响到层次的划分。但该模型的缺点是不够面向对象OOP,领域对象只是作为保存状态或者传递状态使用,它是没有生命的,只有数据没有行为的对象不是真正的对象,在Business Logic里面处理所有的业务逻辑,对于细粒度的逻辑处理,通过增加一层Facade达到门面包装的效果
在使用Spring的时候,通常暗示着你使用了贫血模型,我们把Domain类用来单纯地存储数据,Spring管不着这些类的注入和管理,Spring关心的逻辑层(比如单例的被池化了的Business Logic层)可以被设计成singleton的bean。假使我们这里逆天而行,硬要在Domain类中提供业务逻辑方法,那么我们在使用Spring构造这样的数据bean的时候就遇到许多麻烦,比如:bean之间的引用,可能引起大范围的bean之间的嵌套构造器的调用。
贫血模型实施的最大难度在于如何梳理好BusinessLogic层内部的划分关系,由于该层会比较庞大,边界不易控制,内部的各个模块之间的依赖关系不易管理
充血模型
充血模型层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,BusinessLogic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成Client->(BusinessFacade)->BusinessLogic->Domain Object->Data Access Object。
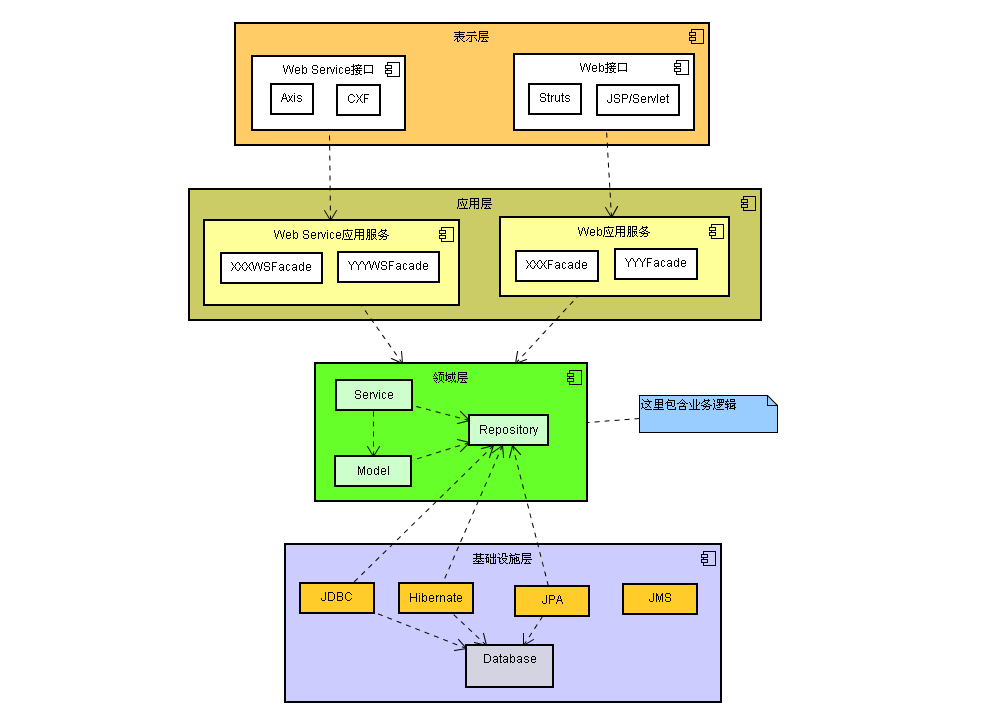
它的优点是面向对象,BusinessLogic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。
缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。即使划分好了业务逻辑,由于分散在Business Logic和DomainObject层中,不能更好的分模块开发。熟悉业务逻辑的开发人员需要渗透到Domain Logic中去,而在DomianLogic又包含了持久化,对于开发者来说这十分混乱。 其次,如果BusinessLogic要控制事务并且为上层提供一个统一的服务调用入口点,它就必须把在Domain Logic里实现的业务逻辑全部重新包装一遍,完全属于重复劳动。
每一个领域模型对象都可以具备自己的基础业务方法,通常满足充血模型的特征。充血模型更加适合较复杂业务逻辑的设计开发。充血模型的层次和模块的划分是一门学问,对开发人员要求亦较高,可以考虑定义这样的一些规则:
- 事务控制不要放在领域模型的对象中实现,可以放在facade中完成。
- 领域模型对象中只保留该模型驱动的一般方法,对于业务特征明显的特异场景方法调用放在facade中完成。
什么是基于充血模型的 DDD 开发模式?
在贫血模型中,数据和业务逻辑被分割到不同的类中。充血模型(Rich Domain Model)正好相反,数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象编程风格。领域驱动设计,即 DDD,主要是用来指导如何解耦业务系统,划分业务模块,定义业务领域模型及其交互。
在基于充血模型的 DDD 开发模式中,Service 层包含 Service 类和 Domain 类两部分。Domain 就相当于贫血模型中的 BO。不过,Domain 与 BO 的区别在于它是基于充血模型开发的,既包含数据,也包含业务逻辑。而 Service 类变得非常单薄。基于充血模型的 DDD 开发模式,跟基于贫血模型的传统开发模式的主要区别就在 Service 层,Controller 层和 Repository 层的代码基本上相同。
总结一下的话就是,基于贫血模型的传统的开发模式,重 Service 轻 BO;基于充血模型的 DDD 开发模式,轻 Service 重Domain。
什么项目应该考虑使用基于充血模型的 DDD 开发模式?
基于贫血模型的传统的开发模式,比较适合业务比较简单的系统开发。相对应的,基于充血模型的 DDD 开发模式,更适合业务复杂的系统开发。比如,包含各种利息计算模型、还款模型等复杂业务的金融系统。
你可能会有一些疑问,这两种开发模式,落实到代码层面,区别不就是一个将业务逻辑放到Service 类中,一个将业务逻辑放到 Domain 领域模型中吗?为什么基于贫血模型的传统开发模式,就不能应对复杂业务系统的开发?而基于充血模型的 DDD 开发模式就可以呢?
答案:除了代码层面,两种不同的开发模式会导致不同的开发流程。
我们平时的开发,大部分都是 SQL 驱动(SQL-Driven)的开发模式。我们接到一个后端接口的开发需求的时候,就去看接口需要的数据对应到数据库中,需要哪张表或者哪几张表,然后思考如何编写 SQL 语句来获取数据。之后就是定义 Entity、BO、VO,然后模板式地往对应的 Repository、Service、Controller 类中添加代码。
业务逻辑包裹在一个大的 SQL 语句中,而 Service 层可以做的事情很少。SQL 都是针对特定的业务功能编写的,复用性差。当我要开发另一个业务功能的时候,只能重新写个满足新需求的 SQL 语句,这就可能导致各种长得差不多、区别很小的 SQL 语句满天飞。
所以,在这个过程中,很少有人会应用领域模型、OOP 的概念,也很少有代码复用意识。对于简单业务系统来说,这种开发方式问题不大。但对于复杂业务系统的开发来说,这样的开发方式会让代码越来越混乱,最终导致无法维护。
如果我们在项目中,应用基于充血模型的 DDD 的开发模式,那对应的开发流程就完全不一样了。在这种开发模式下,我们需要事先理清楚所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成。我们知道,越复杂的系统,对代码的复用性、易维护性要求就越高,我们就越应该花更多的时间和精力在前期设计上。而基于充血模型的 DDD 开发模式,正好需要我们前期做大量的业务调研、领域模型设计,所以它更加适合这种复杂系统的开发。
在基于充血模型的 DDD 开发模式中,将业务逻辑移动到Domain 中,Service 类变得很薄,但在我们的代码设计与实现中,并没有完全将Service 类去掉,这是为什么?或者说,Service 类在这种情况下担当的职责是什么?哪些功能逻辑会放到 Service 类中?
- Service 类负责与 Repository 交流。在我的设计与代码实现中,VirtualWalletService类负责与 Repository 层打交道,调用 Respository 类的方法,获取数据库中的数据,转化成领域模型 VirtualWallet,然后由领域模型 VirtualWallet 来完成业务逻辑,最后调用Repository 类的方法,将数据存回数据库。之所以让 VirtualWalletService 类与 Repository 打交道,而不是让领域模型 VirtualWallet 与 Repository 打交道,那是因为我们想保持领域模型的独立性,不与任何其他层的代码(Repository 层的代码)或开发框架(比如 Spring、MyBatis)耦合在一起,将流程性的代码逻辑(比如从 DB 中取数据、映射数据)与领域模型的业务逻辑解耦,让领域模型更加可复用。
- Service 类负责跨领域模型的业务聚合功能。VirtualWalletService 类中的 transfer() 转账函数会涉及两个钱包的操作,因此这部分业务逻辑无法放到 VirtualWallet 类中,所以,我们暂且把转账业务放到 VirtualWalletService 类中了。当然,虽然功能演进,使得转账业务变得复杂起来之后,我们也可以将转账业务抽取出来,设计成一个独立的领域模型。
- Service 类负责一些非功能性及与三方系统交互的工作。比如幂等、事务、发邮件、发消息、记录日志、调用其他系统的 RPC 接口等,都可以放到 Service 类中。
在基于充血模型的 DDD 开发模式中,尽管 Service 层被改造成了充血模型,但是 Controller 层和 Repository 层还是贫血模型,是否有必要也进行充血领域建模呢?
答案是没有必要。Controller 层主要负责接口的暴露,Repository 层主要负责与数据库打交道,这两层包含的业务逻辑并不多,前面我们也提到了,如果业务逻辑比较简单,就没必要做充血建模,即便设计成充血模型,类也非常单薄,看起来也很奇怪。
尽管这样的设计是一种面向过程的编程风格,但我们只要控制好面向过程编程风格的副作用,照样可以开发出优秀的软件。那这里的副作用怎么控制呢?
就拿 Repository 的 Entity 来说,即便它被设计成贫血模型,违反面相对象编程的封装特性,有被任意代码修改数据的风险,但Entity 的生命周期是有限的。一般来讲,我们把它传递到 Service 层之后,就会转化成 BO 或者 Domain 来继续后面的业务逻辑。Entity 的生命周期到此就结束了,所以也并不会被到处任意修改。
我们再来说说 Controller 层的 VO。实际上 VO 是一种 DTO(Data Transfer Object,数据传输对象)。它主要是作为接口的数据传输承载体,将数据发送给其他系统。从功能上来讲,它理应不包含业务逻辑、只包含数据。所以,我们将它设计成贫血模型也是比较合理的。



