互联网时代,传统应用都有这样一个特点:访问量、数据量都比较小,单库单表都完全可以支撑整个业务。随着业务的发展和用户规模的迅速扩大,对系统的要求也越来越高。因此传统的MySQL单库单表架构的性能问题就暴露出来了。而有下面几个因素会影响数据库性能
- 数据量:业界公认MySQL单表容量在 1千万 以下是最佳状态,因为这时它的BTREE索引树高在3~5之间,超过阈值后性能会随着数据量的增大而变弱。MySQL单表的数据量是500w-1000w之间性能比较好,超过1000w性能会下降。
- 磁盘:因为单个服务的磁盘空间是有限制的,如果并发压力下,所有的请求都访问同一个节点,会对磁盘IO造成非常大的影响。
- 数据库连接:数据库连接是非常稀少的资源,如果一个库里既有用户、商品、订单相关的数据,当海量用户同时操作时,数据库连接就很可能成为瓶颈。
为了提升性能,所以我们必须要解决上述几个问题,那就有必要引进分库分表,当然除了分库分表,还有别的解决方案,就是NoSQL和NewSQL,NoSQL主要是MongoDB等,NewSQL则以TiDB为代表。
分区
就是把一张表的数据分成N个区块,在逻辑上看最终还是一张表,但底层是由N个物理区块组成的,分区实现比较简单,数据库mysql、pgsql、oracle等很容易就可支持。分区后每个区块维护自己的索引B+树,按分区键DML操作效率可以得到很大提升,而不用走全局的索引树
什么时候使用分区?
一张表的查询速度已经慢到影响使用的时候。
- sql经过优化
- 数据量大
- 表中的数据是分段的
- 对数据的操作往往只涉及一部分数据,而不是所有的数据
最常见的分区方法就是按照时间进行分区,分区一个最大的优点就是可以非常高效的进行历史数据的清理,mysql5自5.1开始对分区(Partition)有支持。目前MySQL支持范围分区(RANGE),列表分区(LIST),哈希分区(HASH)以及KEY分区四种。RANGE分区实例
CREATE TABLE my_range_datetime(
id INT,
hiredate DATETIME
)
PARTITION BY RANGE (TO_DAYS(hiredate) ) (
PARTITION p1 VALUES LESS THAN ( TO_DAYS('20171202') ),
PARTITION p2 VALUES LESS THAN ( TO_DAYS('20171203') ),
PARTITION p3 VALUES LESS THAN ( TO_DAYS('20171204') ),
PARTITION p4 VALUES LESS THAN ( TO_DAYS('20171205') ),
PARTITION p5 VALUES LESS THAN ( TO_DAYS('20171206') ),
PARTITION p6 VALUES LESS THAN ( TO_DAYS('20171207') ),
PARTITION p7 VALUES LESS THAN ( TO_DAYS('20171208') ),
PARTITION p8 VALUES LESS THAN ( TO_DAYS('20171209') ),
PARTITION p9 VALUES LESS THAN ( TO_DAYS('20171210') ),
PARTITION p10 VALUES LESS THAN ( TO_DAYS('20171211') ),
PARTITION p11 VALUES LESS THAN (MAXVALUE)
);分表分库
就是把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表明,然后操作它。一般我们经验而言,最多支撑到并发 2000,一定要扩容了,而且一个健康的单库并发值你最好保持在每秒 1000 左右,不要太大。那么你可以将一个库的数据拆分到多个库中,访问的时候就访问一个库好了。
什么时候分表分库?
一张表的查询速度已经慢到影响使用的时候。
- sql经过优化
- 数据量大
- 当频繁插入或者联合查询时,速度变慢
分表后,单表的并发能力提高了,磁盘I/O性能也提高了,写操作效率提高了。分表又分为单库分表(表名不同)和多库分表(表名相同),不管使用哪种策略都还需要自己去实现路由,制定路由规则等,可以考虑使用开源的分库分表中间件,无侵入应用设计,例如淘宝的tddl等。
| # | 分库分表前 | 分库分表后 |
|---|---|---|
| 并发支撑情况 | MySQL 单机部署,扛不住高并发 | MySQL 从单机到多机,能承受的并发增加了多倍 |
| 磁盘使用情况 | MySQL 单机磁盘容量几乎撑满 | 拆分为多个库,数据库服务器磁盘使用率大大降低 |
| SQL 执行性能 | 单表数据量太大,SQL 越跑越慢 | 单表数据量减少,SQL 执行效率明显提升 |
分库分表中间件全部可以归结为两大类型:
- CLIENT模式;
- PROXY模式;
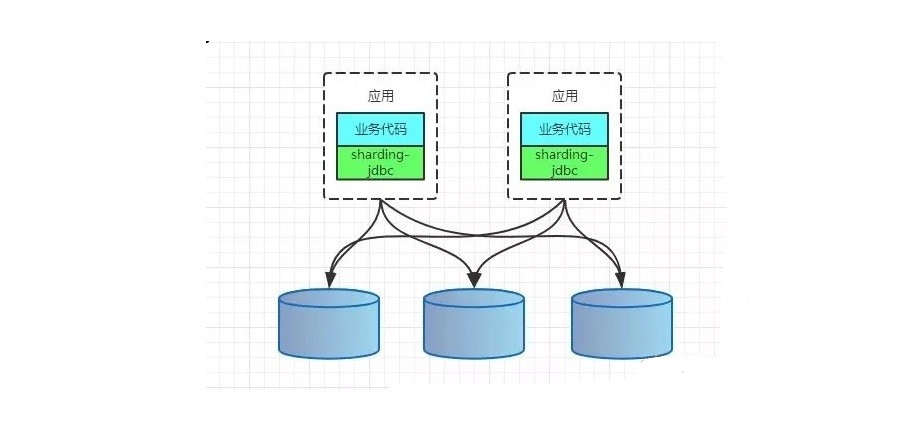
CLIENT模式代表有阿里的TDDL,开源社区的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已经支持了proxy模式)。
PROXY模式代表有阿里的cobar,民间组织的MyCAT。架构如下
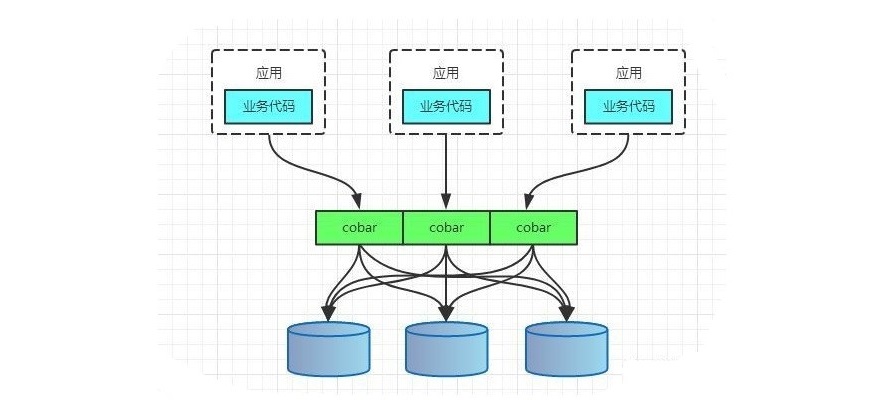
无论是CLIENT模式,还是PROXY模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
分库分表后引入的问题
分布式事务问题
如果我们做了垂直分库或者水平分库以后,就必然会涉及到跨库执行SQL的问题,这样就引发了互联网界的老大难问题-“分布式事务”。那要如何解决这个问题呢?
1.使用分布式事务中间件 2.使用MySQL自带的针对跨库的事务一致性方案(XA),不过性能要比单库的慢10倍左右。3.能否避免掉跨库操作(比如将用户和商品放在同一个库中)
跨库join的问题
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。粗略的解决方法: 全局表:基础数据,所有库都拷贝一份。 字段冗余:这样有些字段就不用join去查询了。 系统层组装:分别查询出所有,然后组装起来,较复杂
横向扩容的问题
当我们使用HASH取模做分表的时候,针对数据量的递增,可能需要动态的增加表,此时就需要考虑因为reHash导致数据迁移的问题。
结果集合并、排序的问题
因为我们是将数据分散存储到不同的库、表里的,当我们查询指定数据列表时,数据来源于不同的子库或者子表,就必然会引发结果集合并、排序的问题。如果每次查询都需要排序、合并等操作,性能肯定会受非常大的影响。走缓存可能是一条路
中间件比较
目前分表分库的中间件比较多的基本有以下几种
- Cobar
- TDDL
- Sharding-jdbc
- Mycat
Cobar
阿里 b2b 团队开发和开源的,属于 proxy 层方案,就是介于应用服务器和数据库服务器之间。应用程序通过 JDBC 驱动访问 Cobar 集群,Cobar 根据 SQL 和分库规则对 SQL 做分解,然后分发到 MySQL 集群不同的数据库实例上执行。早些年还可以用,但是最近几年都没更新了,基本没啥人用,差不多算是被抛弃的状态吧。而且不支持读写分离、存储过程、跨库 join 和分页等操作。
TDDL
淘宝团队开发的,属于 client 层方案。支持基本的 crud 语法和读写分离,但不支持 join、多表查询等语法。目前使用的也不多,因为还依赖淘宝的 diamond 配置管理系统。
ShardingSphere
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
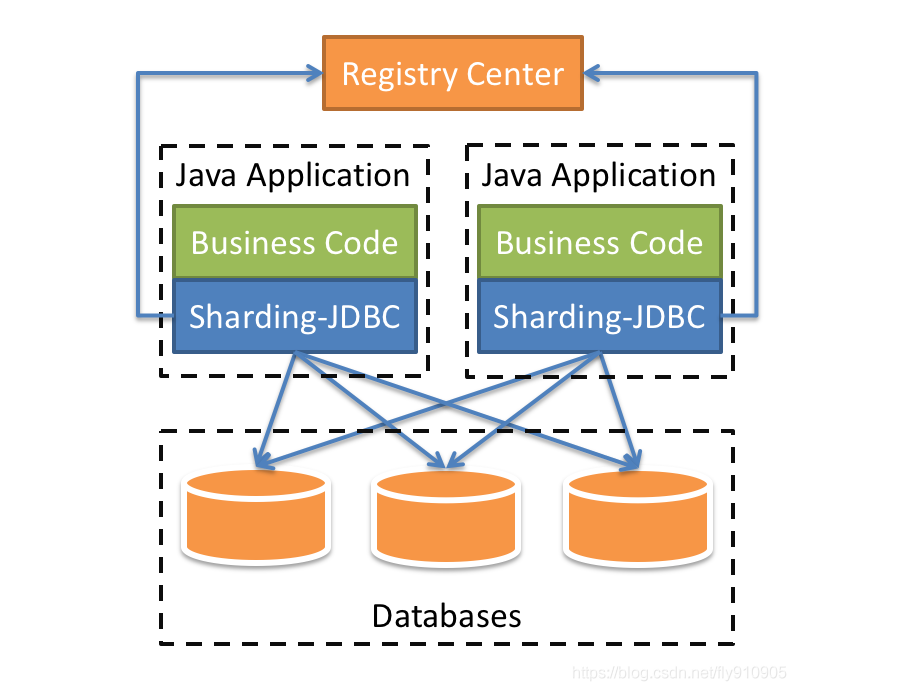
Sharding-jdbc
当当开源的,属于 client 层方案,是 ShardingSphere 的 client 层方案, ShardingSphere 还提供 proxy 层的方案 Sharding-Proxy。确实之前用的还比较多一些,因为 SQL 语法支持也比较多,没有太多限制,而且截至 2019.4,已经推出到了 4.0.0-RC1 版本,支持分库分表、读写分离、分布式 id 生成、柔性事务(最大努力送达型事务、TCC 事务)。而且确实之前使用的公司会比较多一些(这个在官网有登记使用的公司,可以看到从 2017 年一直到现在,是有不少公司在用的),目前社区也还一直在开发和维护,还算是比较活跃,个人认为算是一个现在也可以选择的方案。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
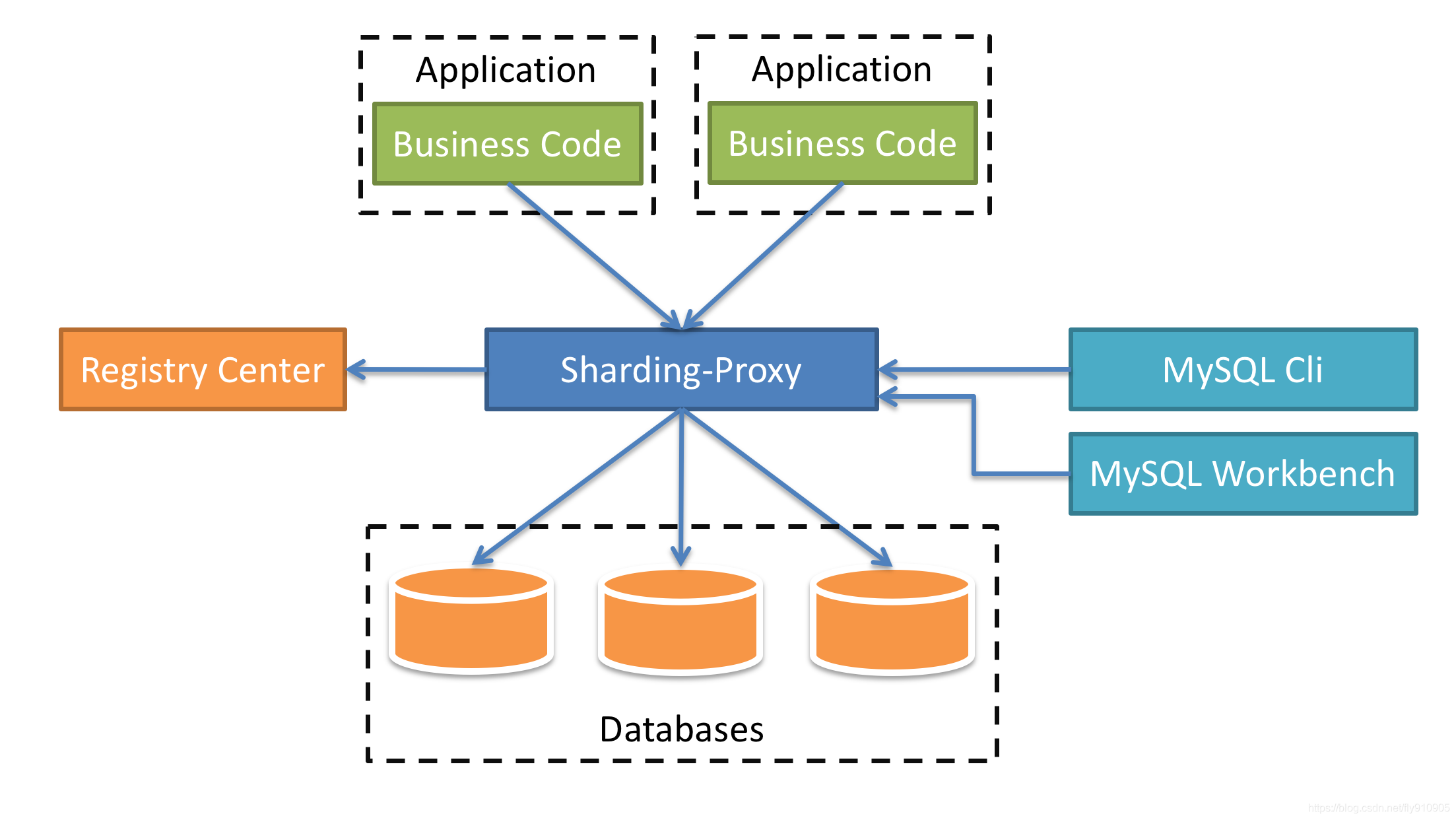
Sharding-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL版本,它可以使用任何兼容MySQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL使用。
- 适用于任何兼容MySQL协议的客户端。
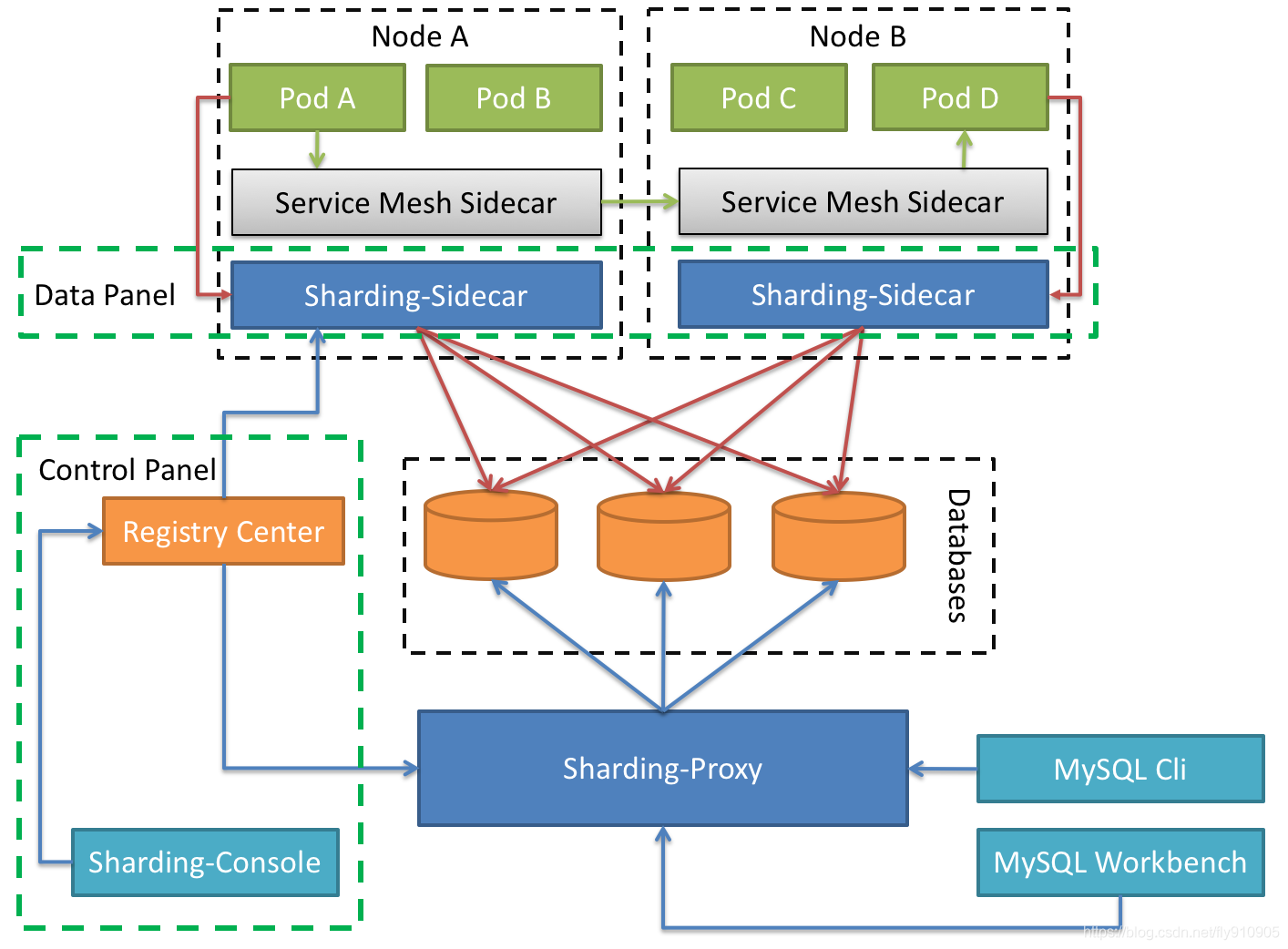
Sharding-Sidecar(TBD)
定位为Kubernetes或Mesos的云原生数据库代理,以DaemonSet的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。
Database Mesh的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效的梳理。使用Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
| Sharding-JDBC | Sharding-Proxy | Sharding-Sidecar | |
|---|---|---|---|
| 数据库 | 任意 | MySQL | MySQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 损耗低 |
| 无中心化 | 是 | 否 | 是 |
| 静态入口 | 无 | 有 | 无 |
混合架构
- Sharding-JDBC采用无中心化架构,适用于Java开发的高性能的轻量级OLTP应用;
- Sharding-Proxy提供静态入口以及异构语言的支持,适用于OLAP应用以及对分片数据库进行管理和运维的场景。
ShardingSphere是多接入端共同组成的生态圈。 通过混合使用Sharding-JDBC和Sharding-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,架构师可以更加自由的调整适合于当前业务的最佳系统架构。
OLTP与OLAP的介绍
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
Mycat
基于 Cobar 改造的,属于 proxy 层方案,支持的功能非常完善,而且目前应该是非常火的而且不断流行的数据库中间件,社区很活跃,也有一些公司开始在用了。但是确实相比于 Sharding jdbc 来说,年轻一些,经历的锤炼少一些。
综上,现在其实建议考量的,就是 Sharding-jdbc 和 Mycat,这两个都可以去考虑使用。
Sharding-jdbc 这种 client 层方案的优点在于不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是如果遇到升级啥的需要各个系统都重新升级版本再发布,各个系统都需要耦合 Sharding-jdbc 的依赖;
Mycat 这种 proxy 层方案的缺点在于需要部署,自己运维一套中间件,运维成本高,但是好处在于对于各个项目是透明的,如果遇到升级之类的都是自己中间件那里搞就行了。
通常来说,这两个方案其实都可以选用,但是我个人建议中小型公司选用 Sharding-jdbc,client 层方案轻便,而且维护成本低,不需要额外增派人手,而且中小型公司系统复杂度会低一些,项目也没那么多;但是中大型公司最好还是选用 Mycat 这类 proxy 层方案,因为可能大公司系统和项目非常多,团队很大,人员充足,那么最好是专门弄个人来研究和维护 Mycat,然后大量项目直接透明使用即可。
如何平滑过渡
停机迁移方案
把系统停掉,没有流量写入了,此时老的单库单表数据库静止了。然后用之前写好一个导数的一次性工具,此时直接跑起来,然后将单库单表的数据哗哗哗读出来,写到分库分表里面去。当历史数据非常多,出现大表时,可能会出现失败的情况
双写迁移方案
简单来说,就是在线上系统里面,之前所有写库的地方,增删改操作,除了对老库增删改,都加上对新库的增删改,这就是所谓的双写,同时写俩库,老库和新库。
然后系统部署之后,新库数据差太远,用之前说的导数工具,跑起来读老库数据写新库,写的时候要根据 主键这类字段判断这条数据最后修改的时间,除非是读出来的数据在新库里没有,或者是比新库的数据新才会写。简单来说,就是不允许用老数据覆盖新数据。
导完一轮之后,有可能数据还是存在不一致,那么就程序自动做一轮校验,比对新老库每个表的每条数据,接着如果有不一样的,就针对那些不一样的,从老库读数据再次写。反复循环,直到两个库每个表的数据都完全一致为止。接着当数据完全一致了,就 ok 了,基于仅仅使用分库分表的最新代码,重新部署一次,不就仅仅基于分库分表在操作了么,还没有几个小时的停机时间,很稳。现在基本玩数据迁移之类的,都是这么干的。
全局ID生成策略
自动增长列
优点:数据库自带功能,有序,性能佳。
缺点:单库单表无妨,分库分表时如果没有规划,ID可能重复。
解决方案,一个是设置自增偏移和步长。
- 假设总共有 10 个分表
- 级别可选: SESSION(会话级), GLOBAL(全局)
- SET @@SESSION.auto_increment_offset = 1; ## 起始值, 分别取值为 1~10
- SET @@SESSION.auto_increment_increment = 10; ## 步长增量
如果采用该方案,在扩容时需要迁移已有数据至新的所属分片。
另一个是全局ID映射表。
- 在全局 Redis 中为每张数据表创建一个 ID 的键,记录该表当前最大 ID;
- 每次申请 ID 时,都自增 1 并返回给应用;
- Redis 要定期持久至全局数据库。
UUID
好处就是本地生成,不要基于数据库来了;不好之处就是,UUID 太长了、占用空间大,作为主键性能太差了;更重要的是,UUID 不具有有序性,会导致 B+ 树索引在写的时候有过多的随机写操作(连续的 ID 可以产生部分顺序写),还有,由于在写的时候不能产生有顺序的 append 操作,而需要进行 insert 操作,将会读取整个 B+ 树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显。
适合的场景:如果你是要随机生成个什么文件名、编号之类的,你可以用 UUID,但是作为主键是不能用 UUID 的。
Snowflake(雪花) 算法
nowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala 语言实现,是把一个 64 位的 long 型的 id,1 个 bit 是不用的,用其中的 41 bits 作为毫秒数,用 10 bits 作为工作机器 id,12 bits 作为序列号。
- 1 bit:不用,为啥呢?因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
- 41 bits:表示的是时间戳,单位是毫秒。41 bits 可以表示的数字多达
2^41 - 1,也就是可以标识2^41 - 1个毫秒值,换算成年就是表示 69 年的时间。 - 10 bits:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。但是 10 bits 里 5 个 bits 代表机房 id,5 个 bits 代表机器 id。意思就是最多代表
2^5个机房(32 个机房),每个机房里可以代表2^5个机器(32 台机器)。 - 12 bits:这个是用来记录同一个毫秒内产生的不同 id,12 bits 可以代表的最大正整数是
2^12 - 1 = 4096,也就是说可以用这个 12 bits 代表的数字来区分同一个毫秒内的 4096 个不同的 id。
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000 00000000
public class IdWorker {
private long workerId;
private long datacenterId;
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence) {
// sanity check for workerId
// 这儿不就检查了一下,要求就是你传递进来的机房id和机器id不能超过32,不能小于0
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(
String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(
String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
System.out.printf(
"worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
// 这个是二进制运算,就是 5 bit最多只能有31个数字,也就是说机器id最多只能是32以内
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 这个是一个意思,就是 5 bit最多只能有31个数字,机房id最多只能是32以内
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << sequenceBits);
private long lastTimestamp = -1L;
public long getWorkerId() {
return workerId;
}
public long getDatacenterId() {
return datacenterId;
}
public long getTimestamp() {
return System.currentTimeMillis();
}
public synchronized long nextId() {
// 这儿就是获取当前时间戳,单位是毫秒
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format(
"Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 这个意思是说一个毫秒内最多只能有4096个数字
// 无论你传递多少进来,这个位运算保证始终就是在4096这个范围内,避免你自己传递个sequence超过了4096这个范围
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
// 这儿记录一下最近一次生成id的时间戳,单位是毫秒
lastTimestamp = timestamp;
// 这儿就是将时间戳左移,放到 41 bit那儿;
// 将机房 id左移放到 5 bit那儿;
// 将机器id左移放到5 bit那儿;将序号放最后12 bit;
// 最后拼接起来成一个 64 bit的二进制数字,转换成 10 进制就是个 long 型
return ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift)
| (workerId << workerIdShift) | sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
// ---------------测试---------------
public static void main(String[] args) {
IdWorker worker = new IdWorker(1, 1, 1);
for (int i = 0; i < 30; i++) {
System.out.println(worker.nextId());
}
}
}动态扩容
优雅的设计扩容缩容的意思就是 进行扩容缩容的代价要小,迁移数据要快。可以采用逻辑分库分表的方式来代替物理分库分表的方式,要扩容缩容时,只需要将逻辑上的数据库、表改为物理上的数据库、表。
所以设计的时候就多分几个库,一开始上来就是 32 个库,每个库 32 个表,那么总共是 1024 张表。按这个分法
- 第一,基本上国内的互联网肯定都是够用了
- 第二,无论是并发支撑还是数据量支撑都没问题。
每个库正常承载的写入并发量是 1000,那么 32 个库就可以承载 32 _ 1000 = 32000 的写并发,如果每个库承载 1500 的写并发,32 _ 1500 = 48000 的写并发,接近 5 万每秒的写入并发,前面再加一个 MQ,削峰,每秒写入 MQ 8 万条数据,每秒消费 5 万条数据。有些除非是国内排名非常靠前的这些公司,他们的最核心的系统的数据库,可能会出现几百台数据库的这么一个规模,128 个库,256 个库,512 个库。1024 张表,假设每个表放 500 万数据,在 MySQL 里可以放 50 亿条数据。每秒 5 万的写并发,总共 50 亿条数据,对于国内大部分的互联网公司来说,其实一般来说都够了。
谈分库分表的扩容,第一次分库分表,就一次性给他分个够,一个实践是利用32 * 32来分库分表,即分为32个库,每个库32张表,一共就是1024张表,根据某个id先根据先根据数据库数量32取模路由到库,再根据一个库的表数量32取模路由到表里面。32*32的规模对大部分的中小型互联网公司来说,已经可以支撑好几年了。
刚开始的时候,这个库可能就是逻辑库,建在一个mysql服务上面,比如一个mysql服务器建了16个数据库。
如果后面要进行拆分,就是不断的在库和mysql实例之间迁移就行了。将mysql服务器的库搬到另外的一个服务器上面去,比如每个服务器创建8个库,这样就由两台mysql服务器变成了4台mysql服务器。我们系统只需要配置一下新增的两台服务器即可。
比如说最多可以扩展到32个数据库服务器,每个数据库服务器是一个库。如果还是不够?最多可以扩展到1024个数据库服务器,每个数据库服务器上面一个库一个表。因为最多是1024个表。
这么搞,是不用自己写代码做数据迁移的,都交给dba来搞好了,但是dba确实是需要做一些库表迁移的工作,但是总比你自己写代码,抽数据导数据来的效率高得多了。
哪怕是要减少库的数量,也很简单,其实说白了就是按倍数缩容就可以了,然后修改一下路由规则。



