在接触到Go语言时,了解到协程的概念。协程,又称微线程,纤程。英文名Coroutine,作为传统线程模型的进化版,虽说协程这个概念几十年前就有了,但是协程只是在近年才开始兴起,Go 、Kotlin、Python , 都是支持协程的。特别是Go语言应用范围越来越广,最近几年协程的概念越来越深入人心。Go语言作为一个出道以来就自带 『高并发』光环的富二代编程语言,它的并发(并行)编程肯定是值得开发者去探究的,而Go语言中的并发(并行)编程是经由goroutine(协程调度器)实现的,goroutine是Go最重要的特性之一,具有使用成本低、消耗资源低、能效高等特点,官方宣称原生goroutine并发成千上万不成问题
线程模型
互联网时代以来,由于在线用户数量的爆炸,单台服务器处理的连接也水涨船高,迫使编程模式由从前的串行模式升级到并发模型,而几十年来,并发模型也是一代代地升级,有IO多路复用、多进程以及多线程,这几种模型都各有长短,现代复杂的高并发架构大多是几种模型协同使用,不同场景应用不同模型,扬长避短,发挥服务器的最大性能,而多线程,因为其轻量和易用,成为并发编程中使用频率最高的并发模型,而后衍生的协程等其他子产品,也都基于它,而我们今天要分析的 goroutine 也是基于线程,因此,我们先来聊聊线程的三大模型:
线程的实现模型主要有3种:内核级线程模型、用户级线程模型和两级线程模型(也称混合型线程模型),它们之间最大的差异就在于用户线程与内核调度实体(KSE,Kernel Scheduling Entity)之间的对应关系上。而所谓的内核调度实体 KSE 就是指可以被操作系统内核调度器调度的对象实体(这说的啥玩意儿,敢不敢通俗易懂一点?)。简单来说 KSE 就是内核级线程,是操作系统内核的最小调度单元,也就是我们写代码的时候通俗理解上的线程了。在Java中我们通过Thread创建的线程都是内核级线程,JVM没有提供协程的功能。
内核级线程模型
用户线程与内核线程KSE是一对一(1 : 1)的映射模型,也就是每一个用户线程绑定一个实际的内核线程,而线程的调度则完全交付给操作系统内核去做,应用程序对线程的创建、终止以及同步都基于内核提供的系统调用来完成,大部分编程语言的线程库(比如Java的java.lang.Thread、C++11的std::thread等等)都是对操作系统的线程(内核级线程)的一层封装,创建出来的每个线程与一个独立的KSE静态绑定,因此其调度完全由操作系统内核调度器去做,也就是说,一个进程里创建出来的多个线程每一个都绑定一个KSE。这种模型的优势和劣势同样明显:优势是实现简单,直接借助操作系统内核的线程以及调度器,所以CPU可以快速切换调度线程,于是多个线程可以同时运行,因此相较于用户级线程模型它真正做到了并行处理;但它的劣势是,由于直接借助了操作系统内核来创建、销毁和以及多个线程之间的上下文切换和调度,因此资源成本大幅上涨,且对性能影响很大。
用户级线程模型
用户线程与内核线程KSE是多对一(N : 1)的映射模型,多个用户线程的一般从属于单个进程并且多线程的调度是由用户自己的线程库来完成,线程的创建、销毁以及多线程之间的协调等操作都是由用户自己的线程库来负责而无须借助系统调用来实现。一个进程中所有创建的线程都只和同一个KSE在运行时动态绑定,也就是说,操作系统只知道用户进程而对其中的线程是无感知的,内核的所有调度都是基于用户进程。许多语言实现的 协程库 基本上都属于这种方式(比如python的gevent)。由于线程调度是在用户层面完成的,也就是相较于内核调度不需要让CPU在用户态和内核态之间切换,这种实现方式相比内核级线程可以做的很轻量级,对系统资源的消耗会小很多,因此可以创建的线程数量与上下文切换所花费的代价也会小得多。但该模型有个原罪:并不能做到真正意义上的并发,假设在某个用户进程上的某个用户线程因为一个阻塞调用(比如I/O阻塞)而被CPU给中断(抢占式调度)了,那么该进程内的所有线程都被阻塞(因为单个用户进程内的线程自调度是没有CPU时钟中断的,从而没有轮转调度),整个进程被挂起。即便是多CPU的机器,也无济于事,因为在用户级线程模型下,一个CPU关联运行的是整个用户进程,进程内的子线程绑定到CPU执行是由用户进程调度的,内部线程对CPU是不可见的,此时可以理解为CPU的调度单位是用户进程。所以很多的协程库会把自己一些阻塞的操作重新封装为完全的非阻塞形式,然后在以前要阻塞的点上,主动让出自己,并通过某种方式通知或唤醒其他待执行的用户线程在该KSE上运行,从而避免了内核调度器由于KSE阻塞而做上下文切换,这样整个进程也不会被阻塞了。
混合型线程模型
混合型线程模型是博采众长之后的产物,充分吸收前两种线程模型的优点且尽量规避它们的缺点。在此模型下,用户线程与内核KSE是多对多(N : M)的映射模型:首先,区别于用户级线程模型,两级线程模型中的一个进程可以与多个内核线程KSE关联,也就是说一个进程内的多个线程可以分别绑定一个自己的KSE,这点和内核级线程模型相似;其次,又区别于内核级线程模型,它的进程里的线程并不与KSE唯一绑定,而是可以多个用户线程映射到同一个KSE,当某个KSE因为其绑定的线程的阻塞操作被内核调度出CPU时,其关联的进程中其余用户线程可以重新与其他KSE绑定运行。所以,混合型线程模型既不是用户级线程模型那种完全靠自己调度的也不是内核级线程模型完全靠操作系统调度的,而是中间态(自身调度与系统调度协同工作),因为这种模型的高度复杂性,操作系统内核开发者一般不会使用,所以更多时候是作为第三方库的形式出现,而Go语言中的runtime调度器就是采用的这种实现方案,实现了Goroutine与KSE之间的动态关联,不过Go语言的实现更加高级和优雅;该模型为何被称为两级?即用户调度器实现用户线程到KSE的『调度』,内核调度器实现KSE到CPU上的『调度』。
JVM中的Thread和OS的Thread的关系
我们都知道CPU的每个核心同一时刻只能执行一个线程。因此会带来一个问题,当线程数量超过CPU的核心数量的时候怎么办?当然是有的线程先暂停一下,然后让其他的线程走走,每个线程都有机会走一下,最终的目标就是让每个线程都执行完毕。对于大部分Java的开发者来说,JVM都是Oracle提供的,而Android开发者面对的就是ART了。但是不管是Oracle的JVM还是谷歌Android的ART,对于这种主流的JVM实现,他们的线程数量和操作系统中线程的数量基本都是保持在1:1的。也就是说只要在Java语言里面每start Thread 一次,JVM中就会多一个Thread,最终就会多一个os级别的线程,在不考虑调整JVM参数的情况下,一个Thread所占用的内存大小是1mb。最终的JVM的Thread的调度还是依赖底层的操作系统级别的Thread调度。只要是依赖了操作系统级别的Thread调度,那么就不可避免的存在Thread切换带来的开销。每一次Thread的 上下文切换都会带来开销,最终结果就是如果线程过多,那么最终线程执行代码的时间就变少,因为大部分的CPU的时间都消耗在了切换线程上下文上。怎么证明在Java中Thread和OS的Thread 是1:1的关系?看源码实现,start方法开启一个线程以后,在start方法中调用了start0方法,而这里start0是一个JNI方法
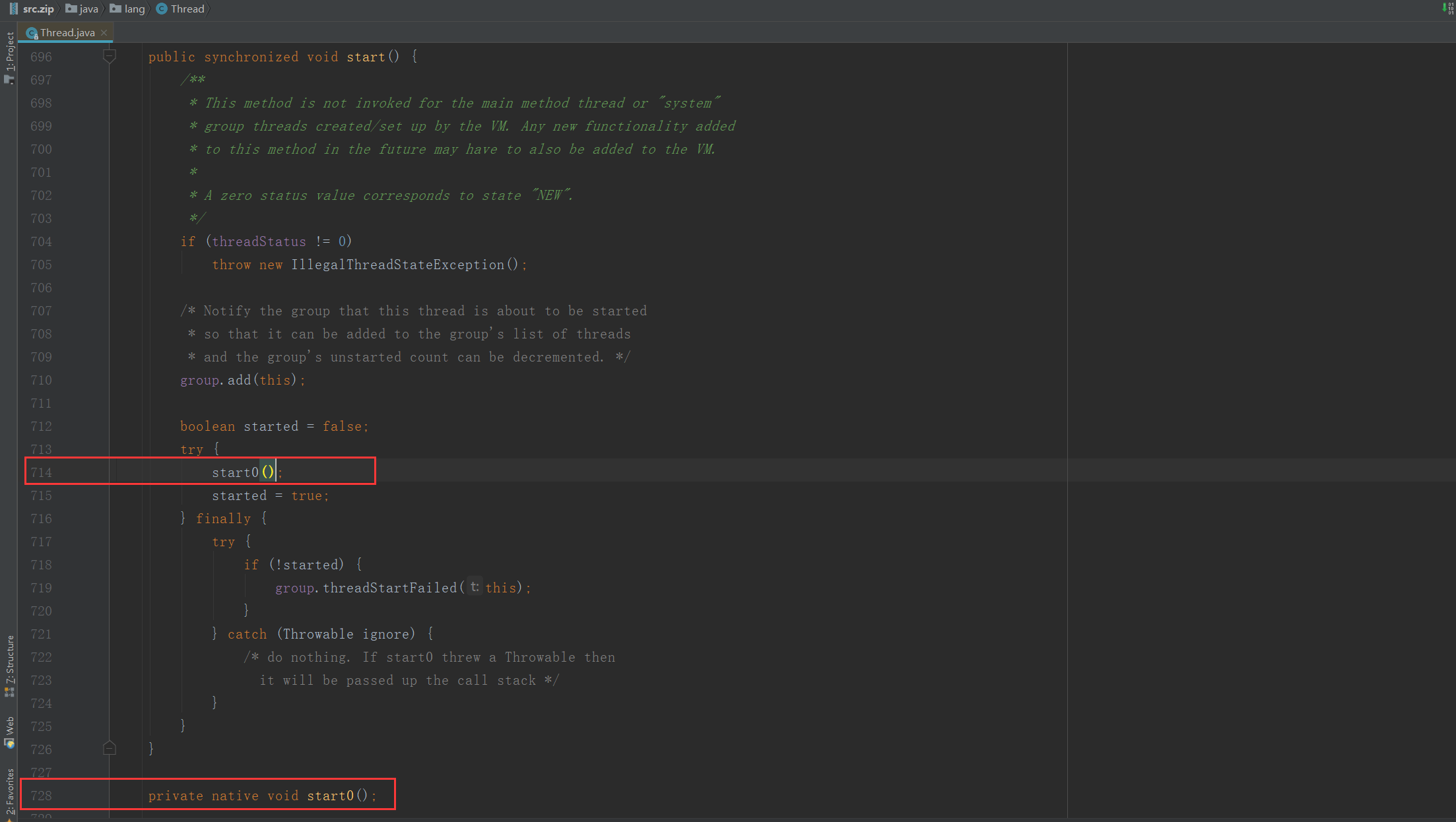
在openjdk的 jdk 目录下 /src/share/native/java/lang/ 目录下查询Thread.c 文件
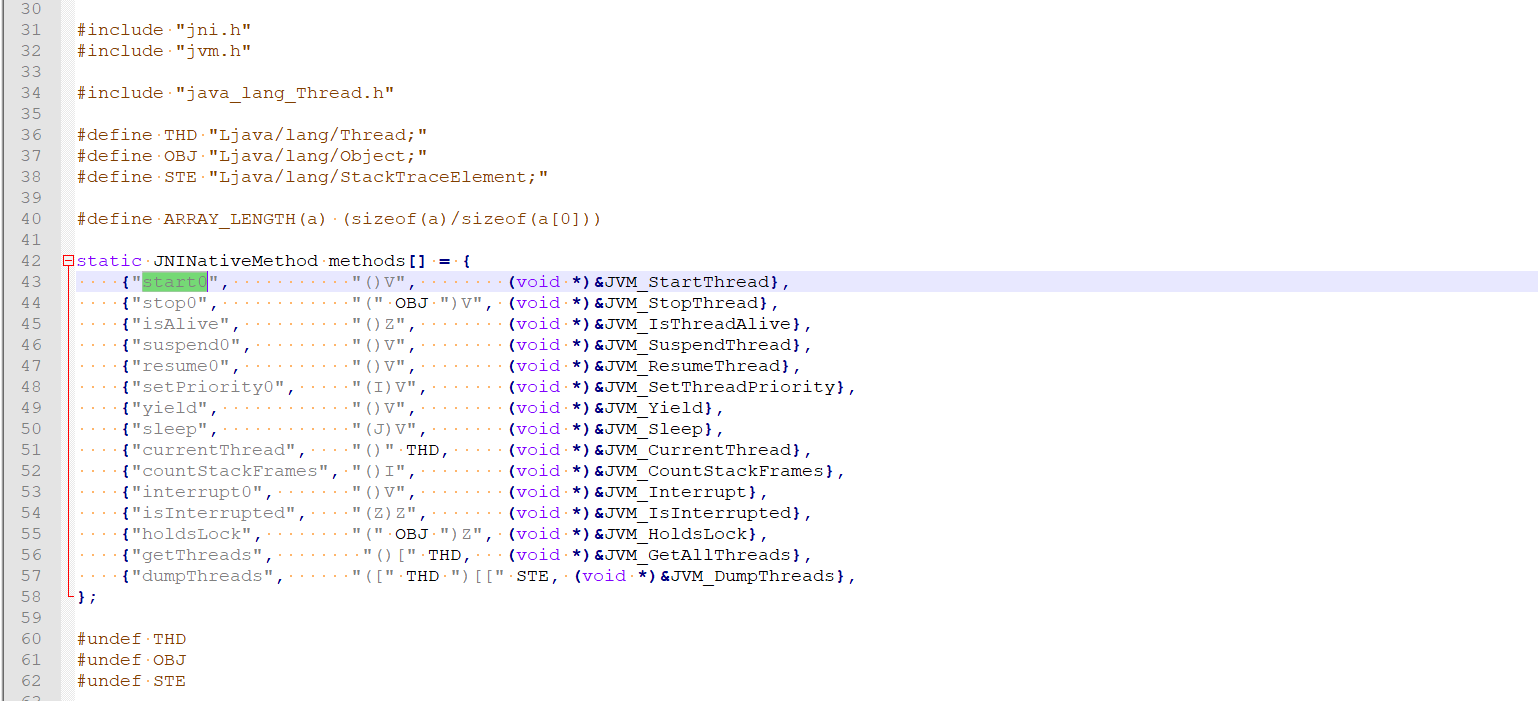
start0 方法最终调用的JVM_StartThread方法. 再看看这个方法。在openjdk的 hotspot 目录下(注意不是jdk目录了):/src/share/vm/prims/ 下面的 jvm.cpp 文件
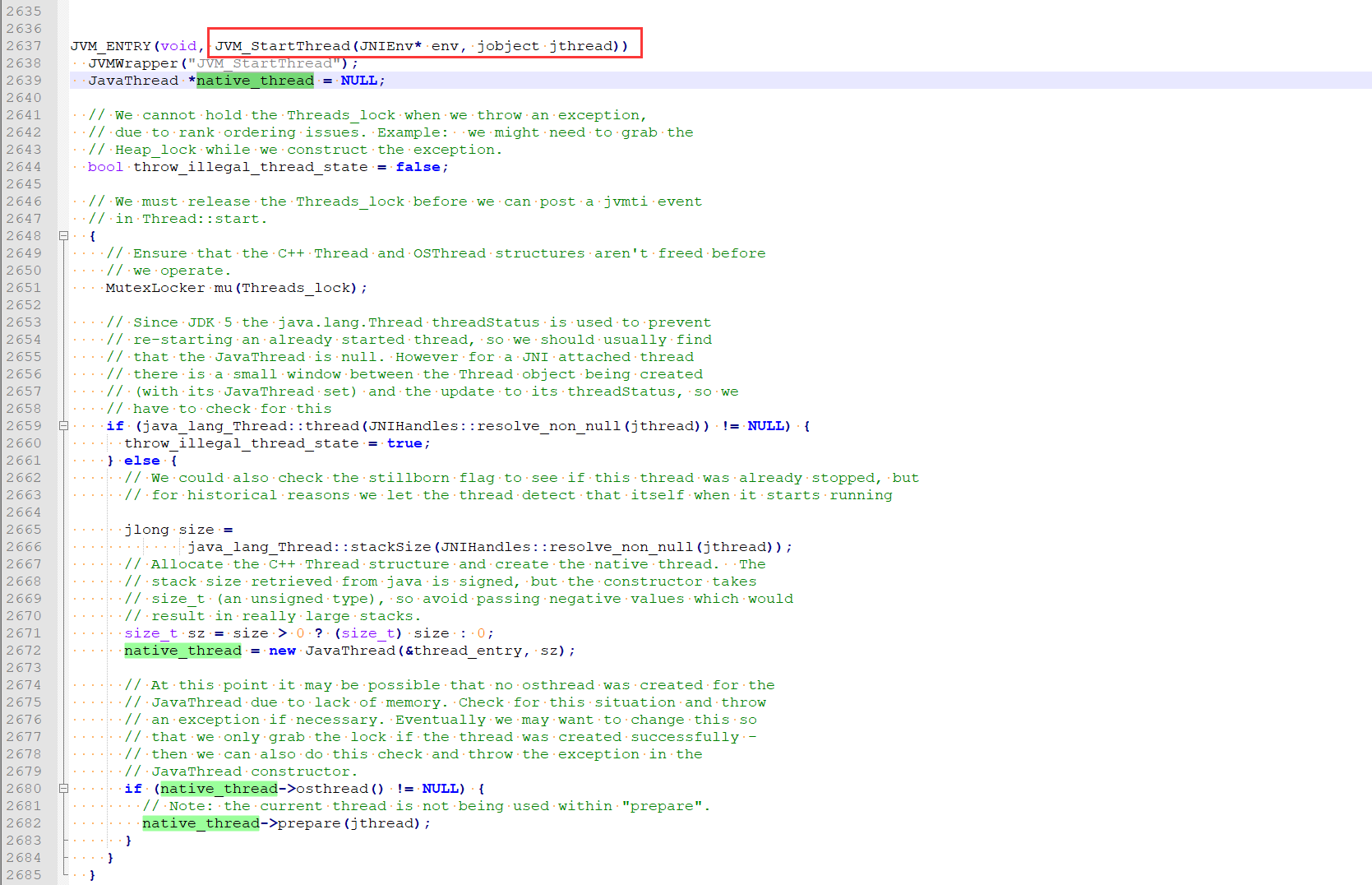
在代码的2672行 new JavaThread创建了线程,继续下去就跟平台有关了,就看Linux系统的吧,继续看下JavaThread类的构造函数
JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz) :
Thread()
#if INCLUDE_ALL_GCS
, _satb_mark_queue(&_satb_mark_queue_set),
_dirty_card_queue(&_dirty_card_queue_set)
#endif // INCLUDE_ALL_GCS
{
if (TraceThreadEvents) {
tty->print_cr("creating thread %p", this);
}
initialize();
_jni_attach_state = _not_attaching_via_jni;
set_entry_point(entry_point);
os::ThreadType thr_type = os::java_thread;
thr_type = entry_point == &compiler_thread_entry ? os::compiler_thread :
os::java_thread;
os::create_thread(this, thr_type, stack_sz);
_safepoint_visible = false;
}在代码17行,执行了create_thread创建线程,继续看这个方法的实现,在hotspot 目录下的src/os/linux/vm/os_linux.cpp
bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
……
pthread_t tid;
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);
……
}省略了无关代码,属性Linux的应该知道 pthread_create函数就是Linux下创建线程的系统函数了。这就完整的证明了主流JVM中 Java代码里Thread和最终对应os中的Thread是1:1的关系。
G-P-M 模型概述
每一个OS线程都有一个固定大小的内存块(一般会是2MB)来做栈,这个栈会用来存储当前正在被调用或挂起(指在调用其它函数时)的函数的内部变量。这个固定大小的栈同时很大又很小。因为2MB的栈对于一个小小的goroutine来说是很大的内存浪费,而对于一些复杂的任务(如深度嵌套的递归)来说又显得太小。因此,Go语言做了它自己的『线程』。
在Go语言中,每一个goroutine是一个独立的执行单元,相较于每个OS线程固定分配2M内存的模式,goroutine的栈采取了动态扩容方式, 初始时仅为2KB,随着任务执行按需增长,最大可达1GB(64位机器最大是1G,32位机器最大是256M),且完全由golang自己的调度器 Go Scheduler 来调度。此外,GC还会周期性地将不再使用的内存回收,收缩栈空间。 因此,Go程序可以同时并发成千上万个goroutine是得益于它强劲的调度器和高效的内存模型。Go的创造者大概对goroutine的定位就是屠龙刀,因为他们不仅让goroutine作为golang并发编程的最核心组件(开发者的程序都是基于goroutine运行的)而且golang中的许多标准库的实现也到处能见到goroutine的身影,比如net/http这个包,甚至语言本身的组件runtime运行时和GC垃圾回收器都是运行在goroutine上的,作者对goroutine的厚望可见一斑。
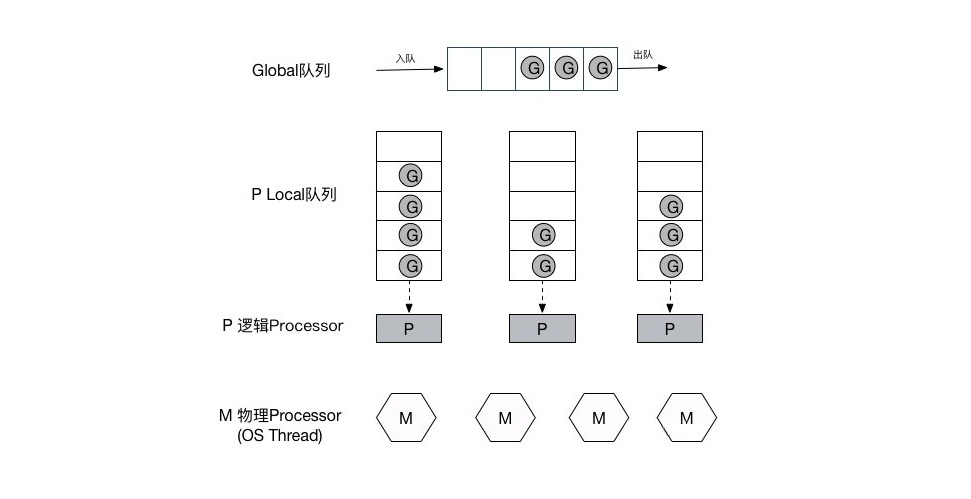
任何用户线程最终肯定都是要交由OS线程来执行的,goroutine(称为G)也不例外,但是G并不直接绑定OS线程运行,而是由Goroutine Scheduler中的 P - Logical Processor (逻辑处理器)来作为两者的『中介』,P可以看作是一个抽象的资源或者一个上下文,一个P绑定一个OS线程,在golang的实现里把OS线程抽象成一个数据结构:M,G实际上是由M通过P来进行调度运行的,但是在G的层面来看,P提供了G运行所需的一切资源和环境,因此在G看来P就是运行它的 “CPU”,由 G、P、M 这三种由Go抽象出来的实现,最终形成了Go调度器的基本结构:
- G: 表示Goroutine,每个Goroutine对应一个G结构体,G存储Goroutine的运行堆栈、状态以及任务函数,可重用。G并非执行体,每个G需要绑定到P才能被调度执行。
- P: Processor,表示逻辑处理器, 对G来说,P相当于CPU核,G只有绑定到P(在P的local runq中)才能被调度。对M来说,P提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等,P的数量决定了系统内最大可并行的G的数量(前提:物理CPU核数 >= P的数量),P的数量由用户设置的GOMAXPROCS决定,但是不论GOMAXPROCS设置为多大,P的数量最大为256。
- M: Machine,OS线程抽象,代表着真正执行计算的资源,在绑定有效的P后,进入schedule循环;而schedule循环的机制大致是从Global队列、P的Local队列以及wait队列中获取G,切换到G的执行栈上并执行G的函数,调用goexit做清理工作并回到M,如此反复。M并不保留G状态,这是G可以跨M调度的基础,M的数量是不定的,由Go Runtime调整,为了防止创建过多OS线程导致系统调度不过来,目前默认最大限制为10000个。
关于P,我们需要再絮叨几句,在Go 1.0发布的时候,它的调度器其实G-M模型,也就是没有P的,调度过程全由G和M完成,这个模型暴露出一些问题:
- 单一全局互斥锁(Sched.Lock)和集中状态存储的存在导致所有goroutine相关操作,比如:创建、重新调度等都要上锁;
- goroutine传递问题:M经常在M之间传递『可运行』的goroutine,这导致调度延迟增大以及额外的性能损耗;
- 每个M做内存缓存,导致内存占用过高,数据局部性较差;
- 由于syscall调用而形成的剧烈的worker thread阻塞和解除阻塞,导致额外的性能损耗。
这些问题实在太扎眼了,导致Go1.0虽然号称原生支持并发,却在并发性能上一直饱受诟病,然后,Go语言委员会中一个核心开发大佬看不下了,亲自下场重新设计和实现了Go调度器(在原有的G-M模型中引入了P)并且实现了一个叫做 work-stealing 的调度算法:
- 每个P维护一个G的本地队列;
- 当一个G被创建出来,或者变为可执行状态时,就把他放到P的可执行队列中;
- 当一个G在M里执行结束后,P会从队列中把该G取出;如果此时P的队列为空,即没有其他G可以执行, M就随机选择另外一个P,从其可执行的G队列中取走一半。
该算法避免了在goroutine调度时使用全局锁。
至此,Go调度器的基本模型确立:
大规模Goroutine的瓶颈
既然Go调度器已经这么牛逼优秀了,我们为什么还要自己去实现一个golang的 Goroutine Pool 呢?事实上,优秀不代表完美,任何不考虑具体应用场景的编程模式都是耍流氓!有基于G-P-M的Go调度器背书,go程序的并发编程中,可以任性地起大规模的goroutine来执行任务,官方也宣称用golang写并发程序的时候随便起个成千上万的goroutine毫无压力。
然而,你起1000个goroutine没有问题,10000也没有问题,10w个可能也没问题;那,100w个呢?1000w个呢?(这里只是举个极端的例子,实际编程起这么大规模的goroutine的例子极少)这里就会出问题,什么问题呢?
- 首先,即便每个goroutine只分配2KB的内存,但如果是恐怖如斯的数量,聚少成多,内存暴涨,就会对GC造成极大的负担,写过java的同学应该知道jvm GC那万恶的STW(Stop The World)机制,也就是GC的时候会挂起用户程序直到垃圾回收完,虽然Go1.8之后的GC已经去掉了STW以及优化成了并行GC,性能上有了不小的提升,但是,如果太过于频繁地进行GC,依然会有性能瓶颈;
- 其次,还记得前面我们说的runtime和GC也都是goroutine吗?是的,如果goroutine规模太大,内存吃紧,runtime调度和垃圾回收同样会出问题,虽然G-P-M模型足够优秀,韩信点兵,多多益善,但你不能不给士兵发口粮(内存)吧?巧妇难为无米之炊,没有内存,Go调度器就会阻塞goroutine,结果就是P的Local队列积压,又导致内存溢出,这就是个死循环…,甚至极有可能程序直接Crash掉,本来是想享受golang并发带来的
快感效益,结果却得不偿失。
一个http标准库引发的血案
我想,作为golang拥趸的Gopher们一定都使用过它的net/http标准库,很多人都说用golang写web server完全可以不用借助第三方的web framework,仅用net/http标准库就能写一个高性能的web server,的确,我也用过它写过web server,简洁高效,性能表现也相当不错,除非有比较特殊的需求否则一般的确不用借助第三方web framework,但是天下没有白吃的午餐,net/http为啥这么快?要搞清这个问题,从源码入手是最好的途径。孔子曾经曰过:源码面前,如同裸奔。所以,高清无码是阻碍程序猿发展大大滴绊脚石啊,源码才是我们进步阶梯,切记切记!接下来我们就来先看看net/http内部是怎么实现的。
net/http接收请求且开始处理的源码放在src/net/http/server.go里,先从入口函数ListenAndServe进去:
func (srv *Server) ListenAndServe() error {
addr := srv.Addr
if addr == "" {
addr = ":http"
}
ln, err := net.Listen("tcp", addr)
if err != nil {
return err
}
return srv.Serve(tcpKeepAliveListener{ln.(*net.TCPListener)})
}看到最后那个srv.Serve调用了吗?没错,这个Serve方法里面就是实际处理http请求的逻辑,我们再进入这个方法内部:
func (srv *Server) Serve(l net.Listener) error {
defer l.Close()
...
// 不断循环取出TCP连接
for {
// 看我看我!!!
rw, e := l.Accept()
...
// 再看我再看我!!!
go c.serve(ctx)
}
}首先,这个方法的参数(l net.Listener) ,是一个TCP监听的封装,负责监听网络端口,rw, e := l.Accept()则是一个阻塞操作,从网络端口取出一个新的TCP连接进行处理,最后go c.serve(ctx)就是最后真正去处理这个http请求的逻辑了,看到前面的go关键字了吗?没错,这里启动了一个新的goroutine去执行处理逻辑,而且这是在一个无限循环体里面,所以意味着,每来一个请求它就会开一个goroutine去处理,相当任性粗暴啊…,不过有Go调度器背书,一般来说也没啥压力,然而,如果,我是说如果哈,突然一大波请求涌进来了(比方说黑客搞了成千上万的肉鸡DDOS你,没错!就这么倒霉!),这时候,就很成问题了,他来10w个请求你就要开给他10w个goroutine,来100w个你就要老老实实开给他100w个,线程调度压力陡升,内存爆满,再然后,你就跪了…
总结
协程为什么那么任性,原因是协程是用户空间实现的并发,减少了内核线程切换导致的上下文切换。Go语言的三位最初的缔造者 — Rob Pike、Robert Griesemer 和 Ken Thompson 中,Robert Griesemer 参与设计了Java的HotSpot虚拟机和Chrome浏览器的JavaScript V8引擎,Rob Pike 在大名鼎鼎的bell lab侵淫多年,参与了Plan9操作系统、C编译器以及多种语言编译器的设计和实现,Ken Thompson 更是图灵奖得主、Unix之父、C语言之父。这三人在计算机史上可是元老级别的人物,特别是 Ken Thompson ,是一手缔造了Unix和C语言计算机领域的上古大神,所以Go语言的设计哲学有着深深的Unix烙印:简单、模块化、正交、组合、pipe、功能短小且聚焦等;而令许多开发者青睐于Go的简洁、高效编程模式的原因,也正在于此。



