线程,对于每个开发者来说都不陌生,随便动手写一写代码就是一个线程。它就像一个能干的小帮手,帮你完成了各种各样的工作,但要真正说起它的运行机制,它的来龙去脉。恐怕不下点功夫,还真难以说的清楚。从Linux内核的角度来说,并没有线程这个概念。Linux把所有的线程都当做进程来实现,内核没有为线程准备特别的调度算法和特别的数据结构。线程仅仅被视为一个与其他进程共享某些资源的进程。所以,在内核看来,它就是一个普通的进程。
什么是线程
在说线程之前,首先要说一下另一个概念:进程。什么是进程,进程是表示资源分配的基本单位,又是调度运行的基本单位。例如,用户运行自己的程序,系统就创建一个进程,并为它分配资源,包括各种表格、内存空间、磁盘空间、I/O设备等。然后,把该进程放人进程的就绪队列。进程调度程序选中它,为它分配CPU以及其它有关资源,该进程才真正运行。所以,进程是系统中的并发执行的单位。在Mac、Windows 、Linux等采用微内核结构的操作系统中,进程的功能发生了变化:它只是资源分配的单位,而不再是调度运行的单位。在微内核系统中,真正调度运行的基本单位是线程。因此,实现并发功能的单位是线程。
线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。因此线程是一个动态的概念,从硬件角度上来说,线程表示当程序运行时。一个控制流占有的CPU,寄存器,内存,I/O等硬件资源的集合叫一个线程。从软件角度上来说,线程表示操作系统能够调度的最小单位,也是我们编写代码控制并发的基本单位。
用户线程 / 内核线程
用户线程:开发者自己实现线程的数据结构、创建销毁和调度维护。也就相当于需要实现一个自己的线程调度内核。最简单的理解是在用户空间中用一个内核线程去并发调用自己实现的多个方法,这时候这些方法就可以理解为用户线程,这里只是举个简单的例子,当然可以用多个内核线程调度多个方法,即多对多线程模型。例如Go语言中的协程就是纯粹的用户线程。
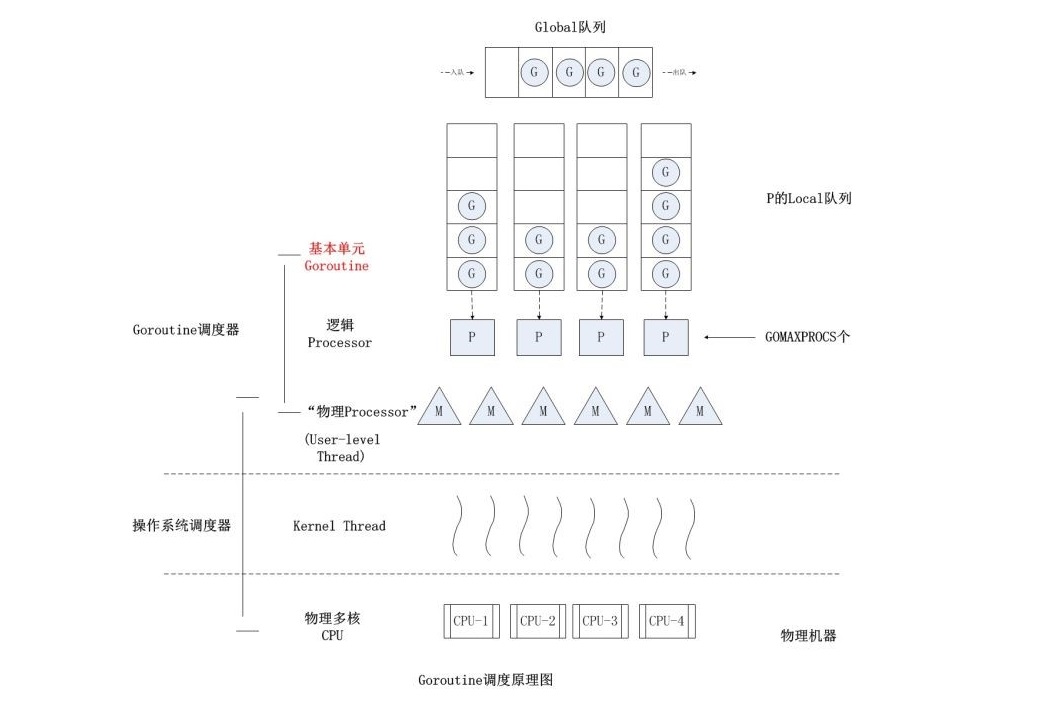
Go语言中协程调度器,G代表的是协程,内核线程和协程的映射是M:N
内核线程:直接使用操作系统中已经实现的线程,而线程的创建、销毁、调度和维护,都是靠操作系统(准确的说是内核)来实现,开发者只需要使用系统调用。Java中的Thread创建的线程不是纯粹的用户线程,具体看JVM使用的是什么线程模型实现的,如果使用一对一,那么Java中的Thread就可用理解为内核线程
用户态 / 内核态
线程的用户态和内核态是只有内核线程才有的概念,表示线程的两个状态,为什么需要用户态和内核态?在CPU的所有指令中,有一些指令是非常危险的,如果错用,将导致整个系统崩溃。比如:清内存、设置时钟等。如果所有的程序都能使用这些指令,那么你的系统一天死机n回就不足为奇了。所以,CPU将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通的应用程序只能使用那些不会造成灾难的指令。Intel的CPU将特权级别分为4个级别:Ring0,Ring1,Ring2,Ring3。内核态与用户态是操作系统的两种运行级别,跟intel cpu没有必然的联系, 如上所提到的intel cpu提供Ring0-Ring3四种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为 内核态
- 内核态: CPU可以访问内存所有数据, 包括外围设备, 例如硬盘, 网卡。 CPU也可以将从一个程序切换到另一个程序,实际上就是CPU把当前线程的代码执行权限级别从Ring3升到Ring0。
- 用户态: 只能受限的访问内存,且不允许访问外围设备。用户态的线程不需要直接访问硬件,如磁盘,网络,键盘输入等功能,只能发起内核调用,将读取磁盘的请求转交给操作系统执行
举个例子,用户程序App有如下的C语言代码,fork()方法是一个系统调用,那么在执行这个方法时,App会把请求转交给内核程序OS(即操作系统)。让内核去执行fork()
void testfork(){
if(0 == fork()){
printf("create new process success!\n");
}
printf("testfork ok\n");
}用请求转交来描述并不准确(很多网文博客都这样描述,这会给人带来误解,我就深受其害,造成很多理解上的困扰),因为这样描述,可能造成这样的理解,当App需要进行系统调用时,App是以某种协议发起一个请求到OS,然后OS把方法执行完成后返回结果,然后App程序再继续执行下面的代码。就像web开发中那样,两个应用之间发起一个类似HTTP请求然后等待结果,如下图
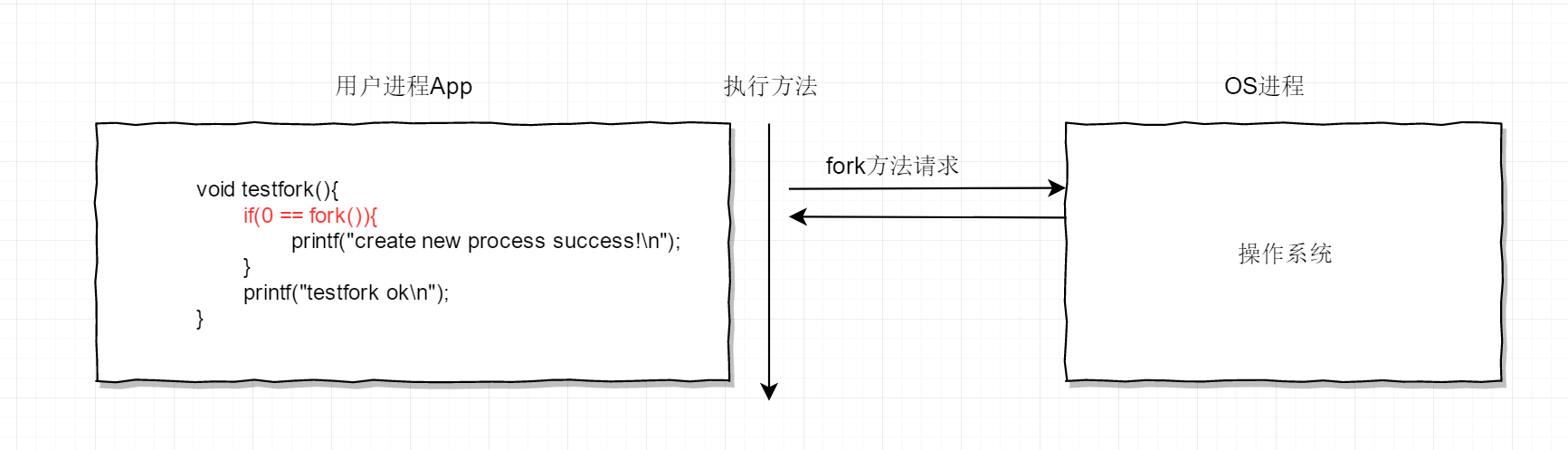
这样的理解是错误的,如果按这样的理解,那么执行用户进程中testfork()方法的线程和内核执行内核进程中fork()方法的线程可以是两个完全独立的线程,这就和web系统中的请求响应模型没什么区别,大错特错了。操作系统并不是这样做的(这里只考虑执行用户代码的线程是内核线程,如果用户进程中存在线程模型映射,那就另当别论了)。执行用户进程代码的线程始终是一个线程,即使线程中存在系统调用,也是在这个线程中完成的。准确来说用户态,内核态和操作系统关系不大,而是CPU为了安全定义出了R0到R3特权级别,操作系统只是利用了CPU提供的这个特权级别来保障用户线程不随意调用硬件导致系统崩溃,因此线程中有两个栈,分别是用户栈和内核栈,用户栈是用来保存用户代码执行时的信息,而当线程中有系统调用时,CPU会把权限从R3提升为R0,然后转而去执行内核代码,而执行内核方法就是使用线程中的内核栈来保存运行时信息。现在我们从特权级的调度来理解用户态和内核态就比较好理解了,当代码运行在3级 特权级上时,就可以称这时候的线程运行在用户态,因为这是最低特权级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态;反之,当代码运行在0级特权级上时,就可以称这时候线程运行在内核态。
用户态和内核态的转换,用户态切换到内核态的3种方式
- 系统调用:这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使 用操作系统提供的服务程序完成工作,比如前例中fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户 特别开放的一个中断来实现,例如Linux的int 80h中断。
- 异常:当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
- 硬件中断:当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会 暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到 内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
内核栈
创建进程时,操作系统会为其分配相应的堆栈等资源。每个进程都有两个栈,用户栈与内存栈(不同进程共享内核空间)。当进程处于用户空间时,CPU堆栈指针寄存器的内容是用户栈地址,而当进程中断或系统调用陷入内核态时,CPU堆栈指针寄存器里保存的是内核空间地址。当进程陷入内核态时,进程所使用的堆栈也要从用户栈转到内核栈。进程陷入到内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样完成用户栈向内核栈的转换;当进程从内核态恢复到用户态之后时,在内核态之后的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了用户栈和内核栈的互转。
从内核转到用户态时,用户栈的地址是在陷入内核的时保存在内核栈里面的,但是在陷入内核的时候,如何知道内核栈的地址?关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为当进程在用户态运行时,使用的用户栈,当进程陷入到内核态时,内核保存进程在内核态运行的相关信息,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
用户态到内核态
我们知道,所有用户程序都是运行在用户态的, 但是有时候程序需要做一些内核态的事情, 例如从硬盘读取数据, 或者从键盘获取输入等。这时需要一个这样的机制: 用户态程序切换到内核态, 但是不能控制在内核态中执行的指令这种机制叫系统调用, 在CPU中的实现称之为陷阱指令(Trap Instruction)。他们的工作流程如下:
- 用户态程序将一些数据值放在寄存器中, 或者使用参数创建一个堆栈(stack frame), 以此表明需要操作系统提供的服务.
- 用户态程序执行陷阱指令
- CPU切换到内核态, 并跳到位于内存指定位置的指令, 这些指令是操作系统的一部分, 他们具有内存保护, 不可被用户态程序访问
- 这些指令称之为陷阱(trap)或者系统调用处理器(system call handler). 他们会读取程序放入内存的数据参数, 并执行程序请求的服务
- 系统调用完成后, 操作系统会重置CPU为用户态并返回系统调用的结果



