曾经我在刚开始学习编程时,有个非常疑惑的地方。一般的家用电脑是8G内存,而应用程序如游戏英雄联盟或者穿越火线安装之后远大于8G内存,那么它们是如何运行起来的,这也是理解进程线程切换时为什么有上下文切换的关键,如果内存足够大,足以把所有的应用程序全部完整的加载到内存中,那其实也就不存在上下文切换。对于这些问题,虽然当时也查了许多资料,不过无奈不懂的东西太多,看的不明所以,最近终于对这个问题终于有了一些理解,故在此记录一下。最主要的是要理解内存管理单元MMU,然后MMU是Memory Management Unit的缩写,中文名是内存管理单元。它是一种负责处理中央处理器(CPU)的内存访问请求的计算机硬件。它的功能包括虚拟地址到物理地址的转换(即虚拟内存管理)、内存保护、中央处理器高速缓存的控制,在较为简单的计算机体系结构中,负责总线的仲裁以及存储体切换(bank switching,尤其是在8位的系统上)。
历史
许多年以前,当人们还在使用DOS或是更古老的操作系统的时候,计算机的内存还非常小,一般都是以K为单位进行计算,相应的,当时的程序规模也不大,所以内存容量虽然小,但还是可以容纳当时的程序。但随着图形界面的兴起还有用户需求的不断增大,应用程序的规模也随之膨胀起来,终于一个难题在程序员的面前,那就是应用程序太大以至于内存容纳不下该程序,通常解决的办法是把程序分割成许多称为覆盖块(overlay)的片段。
覆盖块0首先运行,结束时他将调用另一个覆盖块。虽然覆盖块的交换是由OS完成的,但是必须先由程序员把程序先进行分割,这是一个费时费力的工作,而且相当枯燥。人们必须找到更好的办法从根本上解决这个问题。不久人们找到了一个办法,这就是虚拟存储器(virtual memory)。虚拟存储器的基本思想是程序,数据,堆栈的总的大小可以超过物理存储器的大小,操作系统把当前使用的部分保留在内存中,而把其他未被使用的部分保存在磁盘上。比如对一个16MB的程序和一个内存只有4MB的机器,操作系统通过选择,可以决定各个时刻将哪4M的内容保留在内存中,并在需要时在内存和磁盘间交换程序片段,这样就可以把这个16M的程序运行在一个只具有4M内存机器上了。而这个16M的程序在运行前不必由程序员进行分割。
MMU 作用
内存管理单元通常应用在桌面型计算机或者服务器,通过虚拟存储器使得计算机可以使用比实际的物理内存更多的存储空间。同时,内存管理单元还对实际的物理内存进行分割和保护,使得每个软件任务只能访问其分配到的内存空间。简而言之,MMU的作用有两个
- 将虚拟地址翻译成为物理地址,然后访问实际的物理地址
- 访问权限控制
现代的多用户多进程操作系统, 需要MMU, 才能达到每个用户进程都拥有自己的独立的地址空间的目标. 使用MMU, OS划分出一段地址区域,在这块地址区域中, 每个进程看到的内容都不一定一样. 例如MICROSOFT WINDOWS操作系统, 地址4M-2G处划分为用户地址空间. 进程A在地址 0X400000映射了可执行文件. 进程B同样在地址 0X400000映射了可执行文件. 如果A进程读地址0X400000, 读到的是A的可执行文件映射到RAM的内容. 而进程B读取地址0X400000时则读到的是B的可执行文件映射到RAM的内容
MMU的工作原理
如果处理器没有MMU,CPU内部执行单元产生的内存地址信号将直接通过地址总线发送到芯片引脚,被内存芯片接收,这就是物理地址(physical address),简称PA。英文physical代表物理的接触,所以PA就是与内存芯片physically connected的总线上的信号。
如果启用MMU,CPU执行单元产生的地址信号在发送到内存芯片之前将被MMU截获,这个地址信号称为虚拟地址(virtual address),简称VA,MMU会负责把VA翻译成另一个地址,然后发到内存芯片地址引脚上,即VA映射成PA,如下图:
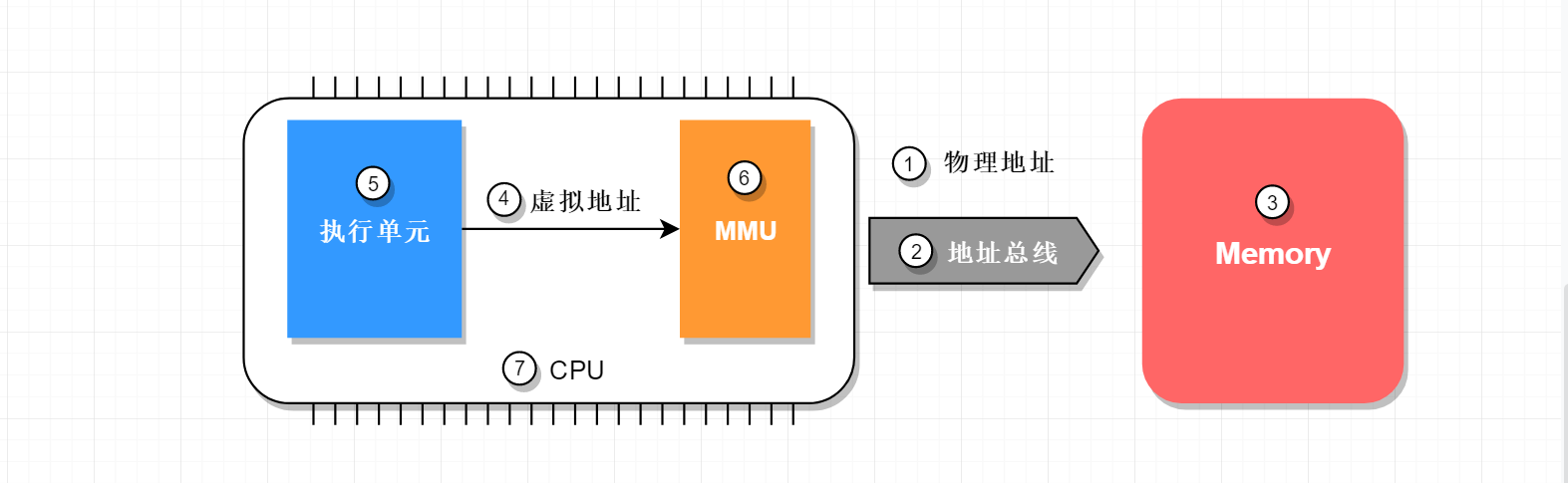
所以物理地址①是通过CPU对外地址总线②传给Memory③使用的地址,而虚拟地址④是CPU内部执行单元⑤产生的,发送给MMU⑥的地址。硬件上MMU⑥一般封装于CPU芯片⑦内部,所以虚拟地址④一般只存在于CPU⑦内部,到了CPU外部地址总线引脚上②的信号就是MMU转换过的物理地址①
软件上MMU对用户程序不可见,在启用MMU的平台上(没有MMU不必说,只有物理地址,不存在虚拟地址),用户C程序中变量和函数背后的数据/指令地址等都是虚拟地址,这些虚拟内存地址从CPU执行单元⑤发出后,都会首先被MMU拦截并转换成物理地址,然后再发送给内存。也就是说用户程序运行 int pA =100;这条赋值语句时,假设debugger显示指针pA的值为0x30004000(虚拟地址),但此时通过硬件工具(如逻辑分析仪)侦测到的CPU与外存芯片间总线信号很可能是另外一个值,如0x8000(物理地址)。当然对一般程序员来说,只要上述语句运行后debugger显示0x30004000位置处的内存值为100就行了,根本无需关心pA的物理地址是多少。但进行OS移植或驱动开发的系统程序员不同,他们必须清楚软件如何在幕后辅助硬件MMU完成地址转换。
MMU的地址映射
根据图1,我们大致知道MMU在底层中扮演的角色,那么MMU具体是如何映射的地址的。在计算机上我们会运行一个操作系统,如linux,windows等,用户编写的源程序,需要经过编译,链接,生成可执行程序,然后源程序被操作系统加载执行。在链接的时候通常我们要指定一个链接脚本,链接脚本的作用有很多,其中一个的作用是控制可执行文件的section的符号的内存布局,也就是控制可执行程序将来要在内存中哪里放置。操作系统会按照可执行程序的要求将其加载到内存的对应地址执行。假如用户A编写的应用程序的链接地址范围是0x100-0x200,用户B编写的应用程序的链接地址范围是0x100-0x200,这是很有可能的。因为给操作系统提供应用程序的开发者很多,不可能为每个开发者限定使用那些内存。这样,执行程序A的时候就不能执行程序B,执行程序B的时候就不能执行程序A,因为它们执行时会覆盖对方内存中的程序。为了解决这个问题,必须引入虚拟地址,为此操作系统和处理器都做了处理,添加了MMU,让其进行地址翻译。在程序载入内存的时候,操作系统会为其建立地址翻译表,处理器执行不同应用程序的时候,使用不同的地址翻译表。如下图所示。
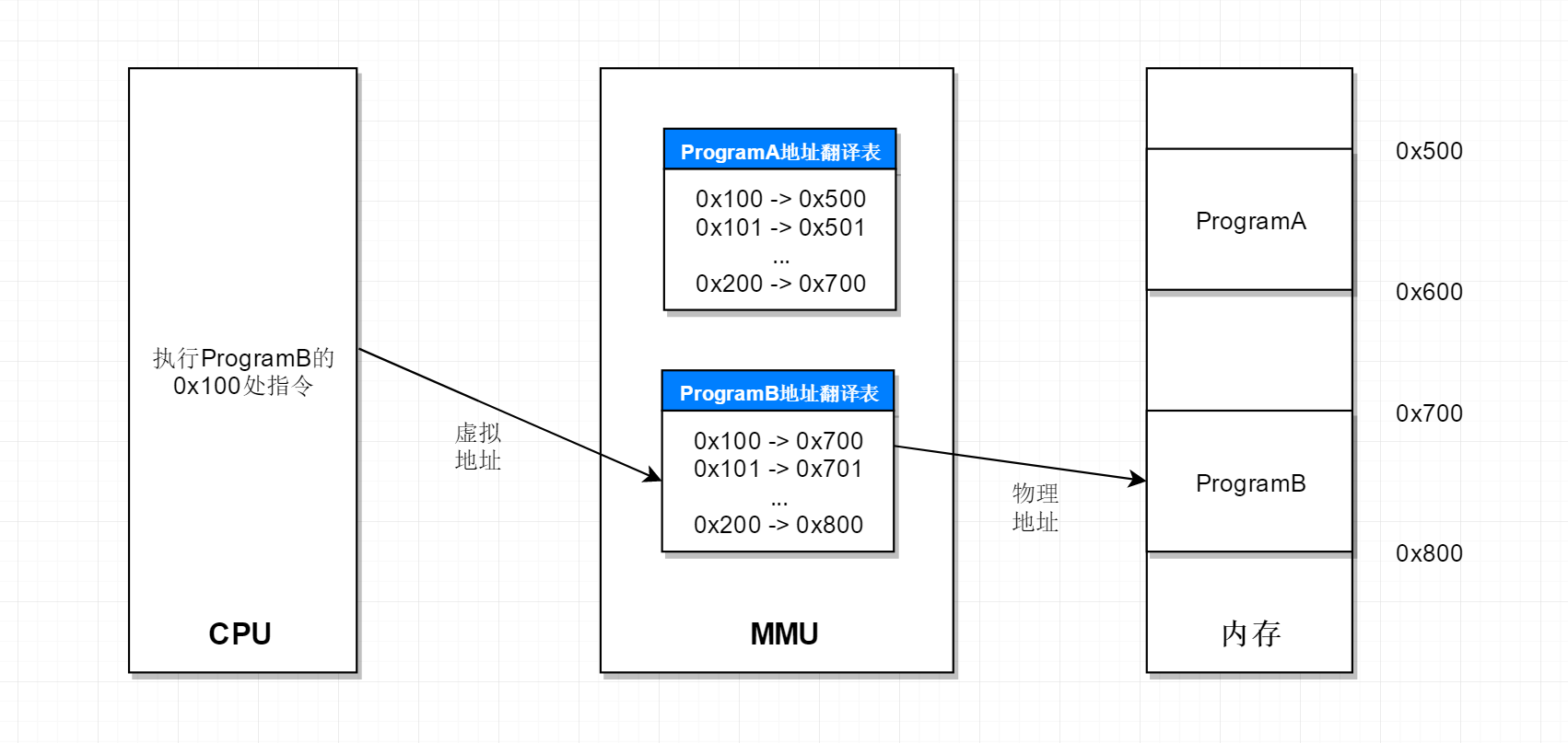
ProgramA被加载到物理地址地址0x500-0x600处,ProgramB被加载到物理地址0x700-0x800处,同时建立了各自的地址翻译表,当处理器要执行ProgramB时,会使用ProgramB对应的地址翻译表,比如读取ProgramB地址0x100处的指令,那么经过地址翻译表可知0x100对应实际内存的0x700处,所以实际读取的就是0x700处的指令。同样的,当处理器要执行ProgramA时,会使用ProgramA对应的地址翻译表,这样就避免了之前提到的内存冲突问题,有了MMU的支持,操作系统就可以轻松实现多任务了。
MMU的地址翻译功能还可以为用户提供比实际大得多的内存空间。用户在编写程序的时候并不知道运行该程序的计算机内存大小,如果在链接的时候指定程序被加载到地址Addr处,而运行该程序的计算机内存小于Addr,那么程序就无法执行,有了MMU后,程序员就不用关心实际内存大小,可以认为内存大小就是“2^指令地址宽度”。MMU会将超过实际内存的虚拟地址翻译为物理地址进行访问。 地址翻译表存储在内存中,如果采用图2中的方式:地址翻译表的表项是一个虚拟地址对应一个物理地址,那么会占用太多的内存空间,为此,需要修改翻译方式,常用的有三种:页式、段式、段页式,这也是三种不同的内存管理方式。
内存保护
内存保护也叫权限管理,除了具有地址翻译的功能外,还提供了内存保护功能。采用页式内存管理时可以提供页粒度级别的保护,允许对单一内存页设置某一类用户的读、写、执行权限,比如:一个页中存储代码,并且该代码不允许在用户模式下执行,那么可以设置该页的保护属性,这样当处理器在用户模式下要求执行该页的代码时,MMU会检测到并触发异常,从而实现对代码的保护。特别是在处理应用程序时,如果一个应用程序写的比较烂,出现了指针越界或栈溢出,程序跑飞等情况,因为不能访问别的程序的地址,所以不会影响到别的应用程序的运行。比如在操作系统下,应用程序不能访问寄存器,而操作系统可以。比如应用程序的只读数据段不能被写,否则会发生段错误。
大体积app在小资源系统运行
在嵌入式系统中,假如内存容量只有256M大,而应用程序却有1G大时,通常一个程序中,程序执行的比较多的是顺序指令,所以在运行1G的程序时,操作系统会先加载一小部分到内存中,当执行完这一部分或发生跳转发现内存中没有要跳转地址的指令时,操作系统再加载需要跳转部分的程序到其链接地址(虚拟地址),加载完后再继续执行。内次加载程序,都需要建立一个动态的地址映射表。当物理内存加载满后,操作系统会选择性的将最早之前加载入物理内存的程序置换到外部flash等存储器中,再加载需要用到的一块程序。因为置换需要时间,所以当使用存储容量较小内存的嵌入式系统后,让其运行大程序,使用可能会有一定的卡顿现象。
操作系统和MMU
现代的多用户多进程操作系统,需要MMU,才能达到每个用户进程都拥有自己独立的地址空间的目标。使用MMU,操作系统划分出一段地址区域,在这块地址区域中,每个进程看到的内容都不一定一样。所以实际上MMU是为满足操作系统越来越复杂的内存管理而产生的。OS和MMU的关系简单说:
- 系统初始化代码会在内存中生成页表,然后把页表地址设置给MMU对应寄存器,使MMU知道页表在物理内存中的什么位置,以便在需要时进行查找。之后通过专用指令启动MMU,以此为分界,之后程序中所有内存地址都变成虚地址,MMU硬件开始自动完成查表和虚实地址转换。
- OS初始化后期,创建第一个用户进程,这个过程中也需要创建页表,把其地址赋给进程结构体中某指针成员变量。即每个进程都要有独立的页表。
- 用户创建新进程时,子进程拷贝一份父进程的页表,之后随着程序运行,页表内容逐渐更新变化。比较复杂了,几句讲不清楚,不多说了哈,有时间讲linux的话再说吧
总结
总而言之MMU的作用就两点:地址翻译和内存保护。对于上层应用的开发者来说,其实不必要了解太多的MMU实现细节,但是了解其工作过程和原理,有助于我们理解程序的执行过程和操作系统的工作原理等,毕竟我们开发的应用程序都运行在它们之上。在一些性能要求比较高的应用场景,虚拟内存的使用情况也是必须要关注的一个指标



