最近项目在做一个统计功能,本地开发完后需要造大量数据进行自测,一来测试统计功能是否正确,二来这个表在生产环境上数据量较大,需要测一下单表数据很多时的性能情况。因此在本地测试时首先要给表造十多万条数据,这么多的数据量一条一条的新增显然是不现实的。我想到的一种方式是通过代码批量插入实现,不过这样太麻烦了,需要去额外写代码,于是想通过sql或是存储过程直接去做。故此在这里总结一下各数据库批量造数据的脚步
PostgreSQL
pgsql批量造数据主要通过generate_series方法,下面这个例子中generate_series有个1000的参数,这样就可以造1000条数据。有一点不好的是,只能单表
DROP TABLE IF EXISTS student_info;
CREATE TABLE student_info(
user_id VARCHAR(20),
user_name VARCHAR(20),
remark VARCHAR(20),
create_time Date
);
insert into student_info
select
round(random()*100),
'张三',
'测试数据'
from generate_series(1,1000);使用存储过程
使用存储过程可以一次性造多表的数据,并且可以自由设置不同的参数。有时候业务数据量过大而需要分表,于是把student_info做了10个分表,在造数据时需要把每个分表都插入一部分测试数据,并且插入时间递增。
do $$
declare
i integer :=1;
begin
for i in 1..1000 loop
if i<=100 then
insert into student_info_0(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>100 and i<=200 then
insert into student_info_1(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>200 and i<=300 then
insert into student_info_2(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>300 and i<=400 then
insert into student_info_3(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>400 and i<=500 then
insert into student_info_4(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>500 and i<=600 then
insert into student_info_5(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>600 and i<=700 then
insert into student_info_6(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>700 and i<=800 then
insert into student_info_7(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>800 and i<=900 then
insert into student_info_8(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
elsif i>900 and i<=1000 then
insert into student_info_9(user_id,user_name,remark,create_time) values('00'||i,'张三','测试数据',now()::timestamp+ (i||' min')::interval);
end if;
end loop;
end $$;关于时间函数使用
--当前时间
select now();
--两年后时间
select now() + interval '2 years';
--两个月后
select now() + interval '2 month';
--三个月前
select now() - interval '3 week';
--十分钟后
select now() + '10 min';删除重复数据,并保留一条
有时候我们需要造了很多重复数据,便想删除重复数据,但要保留其中的一条。假设student_info表的数据如下。
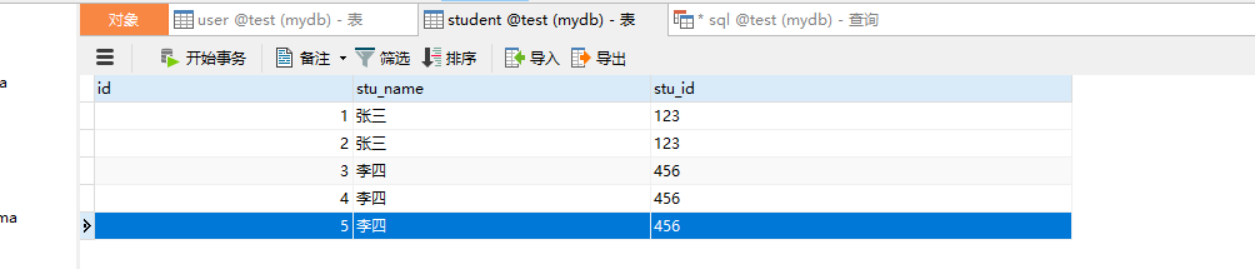
表中张三和李四的stu_id都有重复的,张三重复了两条,而李四重复了三条。我们想删除stu_id重复的并保留id最小的数据,在pgsql中可以这么写
delete from student where id not in (SELECT min(id) FROM student GROUP BY stu_id HAVING COUNT(stu_id)>=1)Oracle
oracle主要通过一个循环实现,以刚刚创建的student_info表为例,如果plsql不自动提交事务,可以把commit代码放开,sql脚本如下
begin
for i in 1..5 loop
insert into student_info values('00'||i,'张三','测试数据');
end loop;
-- commit; --循环执行完后进行提交
end
/
select * from student_info;Mysql
这里数据量在100W级别,如果想要千万级不要使用rand() 或者uuid() 会导致性能下降。在循环中可以实现多个表的批量插入,脚本如下
delimiter $$ --结束符为 $$
DROP PROCEDURE IF EXISTS mytest; --判断进程是否存在,存在则删除
CREATE PROCEDURE mytest() --新建进程
BEGIN
declare i int;
DECLARE j varchar(200);
set i = 2;
while i < 1000 do --循环体
SET j=CONCAT('00',i); --拼接字符串
INSERT INTO student_info(`user_id`, `user_name`, `remark`)
VALUES (j, '张三','e10adc3949ba59abbe56e057f20f883e');
INSERT INTO pub_user_post (`POST_CODE`, `USER_CODE`)
VALUES (i, 'A685187D29AF4AD793F2753DC17C1435');
set i=i+1;
end while;
end $$ --结束定义语句
delimiter ; --先把结束符恢复为 ;
call mytest(); --调用进程


