布隆过滤器是大数据领域一个经常用到的算法。如果看过《数学之美》的同学对它应该并不陌生,它经常用在集合的判断上,在海量数据的场景当中用来快速地判断某个元素在不在一个庞大的集合当中。它的原理不难,但是设计非常巧妙。一般的业务场景用不上布隆过滤器,但在大数据量,高并发场景下,它的作用就被凸显出来了。布隆过滤器被广泛用于网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统以及解决缓存穿透问题。
缓存穿透
在应用系统开发过程中,少不了使用缓存来降低磁盘IO的访问次数,我们经常会把一部分数据放在Redis等缓存,比如产品详情。这样有查询请求进来,我们可以根据产品ID直接去缓存中取数据,而不用读取数据库,这是提升性能最简单,最普遍,也是最有效的做法。一般的查询请求流程是这样的:先查缓存,有缓存的话直接返回,如果缓存中没有,再去数据库查询,然后再把数据库取出来的数据放入缓存,一切看起来很美好。这个查询逻辑实际上是有漏洞的,如果黑客使用一大批系统中不存在的产品ID来请求,根据刚刚这个逻辑,那么缓存中肯定是查不到的,所以就会导致这一大批产品ID去请求数据库,造成这段时间内数据库IO压力巨大,甚至数据库服务挂掉,如果数据库是集群的话,就可能造成雪崩效应了。这时候你就得吭哧吭哧的跑过来加班了o(╥﹏╥)o ,对于这种情况我们有什么办法可以解决呢?下面举例两种解决方案
- 把数据库中所有的产品ID全部保存到Redis中
- 使用布隆过滤器
第一种方案很直观,产品ID全在内存中了,请求过来就只需要查Redis了,Redis中不存在就直接返回。这样相当于把Redis当做数据库了。但如果系统中产品很多,假设产品ID使用32位的UUID生成字符串,那么一个产品ID相当于0.06KB,一亿个产品就相当于6GB了,如果到产品到两亿三亿呢,内存这么昂贵,这种方式显然就不行了。第二种方式就是今天的主角,布隆过滤器就可以解决这个问题,而且不需要存储下原值,这是一个非常巧妙的做法,让我们一起来看下它的原理。
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难,实际上是不支持删除。布隆过滤器被广泛用于网页黑名单系统、垃圾邮件过滤系统、爬虫的网址判重系统以及解决缓存穿透问题。通过介绍已经知晓布隆过滤器的作用是检索一个元素是否在集合中。布隆过滤器离不开哈希函数,所以在这里有必要介绍下哈希函数的概念,如果你已经掌握了,可以直接跳过。
哈希函数
哈希函数的概念是:将任意大小的输入数据转换成特定大小的输出数据的函数,转换后的数据称为哈希值或哈希编码,也叫散列值。下面是一幅示意图:
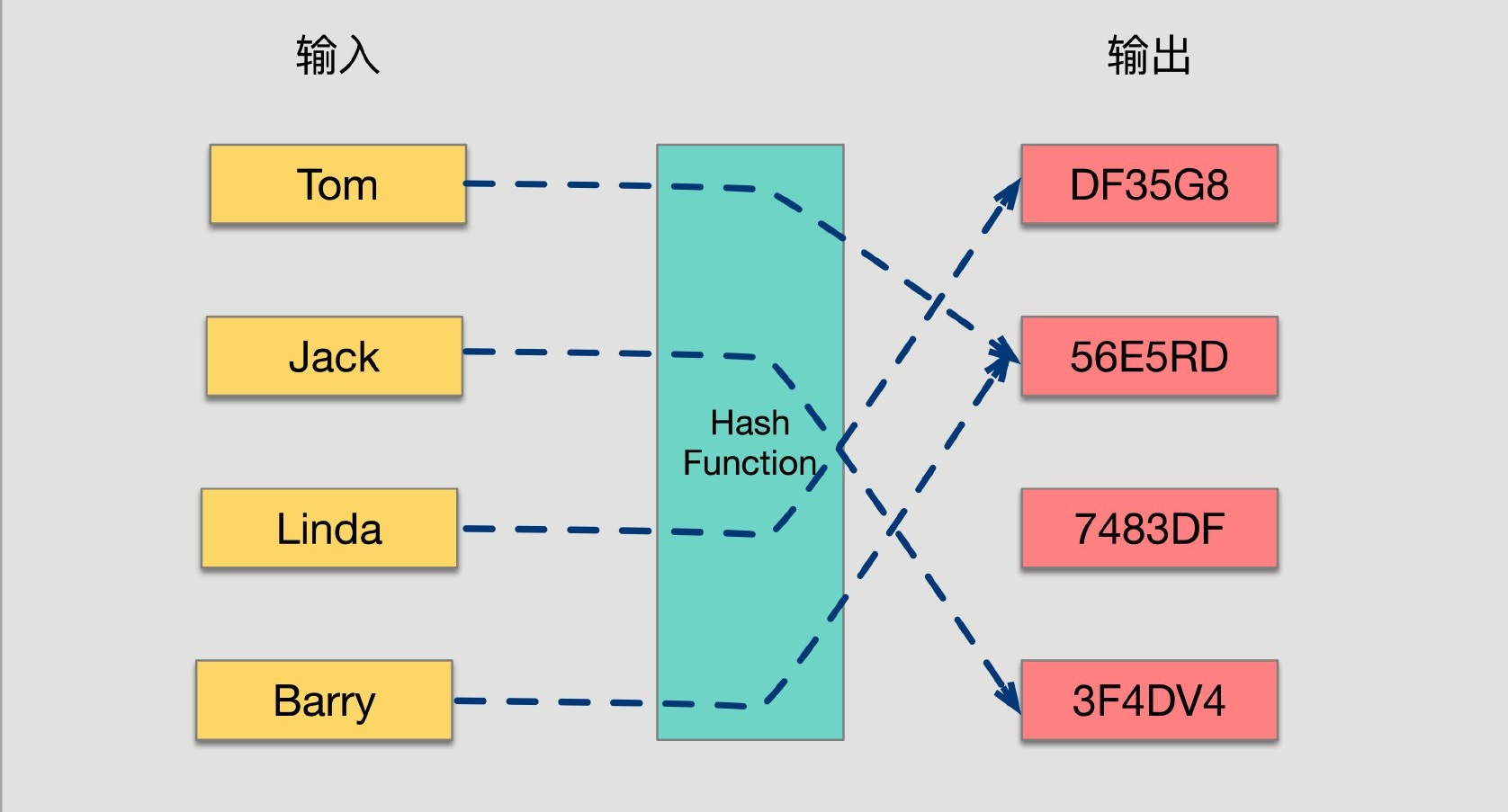
哈希函数的性质:
- 经典的哈希函数都有无限大的输入值域(无穷大)。
- 经典的哈希函数的输出域都是固定的范围(有穷大,假设输出域为S)
- 当给哈希函数传入相同的值时,返回值必一样
- 当给哈希函数传入不同的输入值时,返回值可能一样,也可能不一样。
- 输入值会尽可能均匀的分布在S上
前三点都是哈希函数的基础,第四点描述了哈希函数存在哈希碰撞的现象,因为输入域无限大,输出域有穷大,这是必然的,输入域中会有不同的值对应到输入域S中。第五点事评价一个哈希函数优劣的关键,哈希函数越优秀,分布就越均匀且与输入值出现的规律无关。
布隆过滤器原理
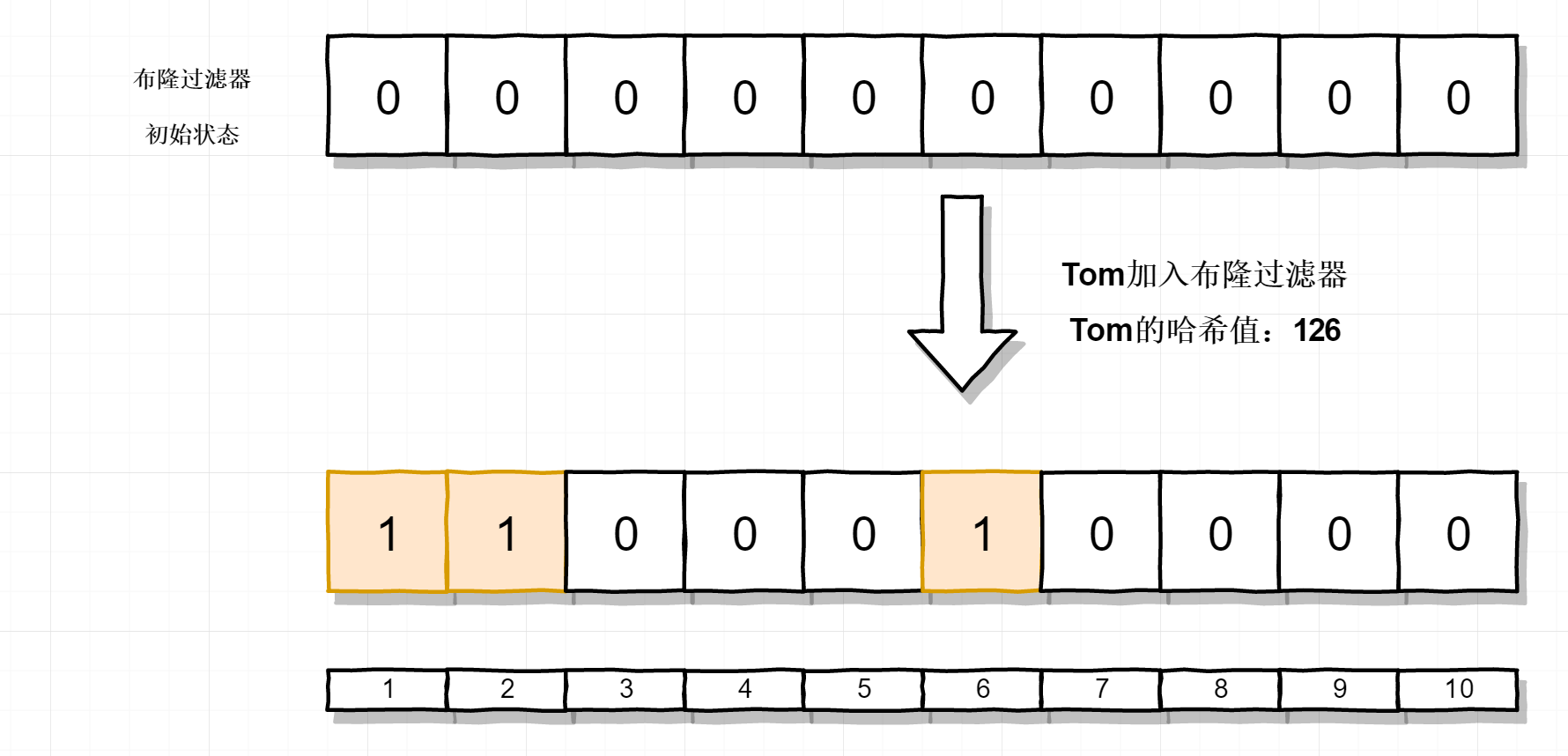
布隆过滤器本身的结构非常简单,就是一个一维的bool型的数组,也就是说每一位只有0或者1,是一个bit,这个数组的长度是M。为了理解布隆过滤器的工作原理,我举两个数据来演示布隆过滤器的插入和判断原理,就以上图的四个用户Tom,Jack,Linda和Barry为例吧,当然我们需要一种哈希算法把用户名字映射为数字而不是字符串,假设他们的名字经过哈希算法后映射的数字如下
| 名字 | 哈希值 |
|---|---|
| Tom | [1,2,6] |
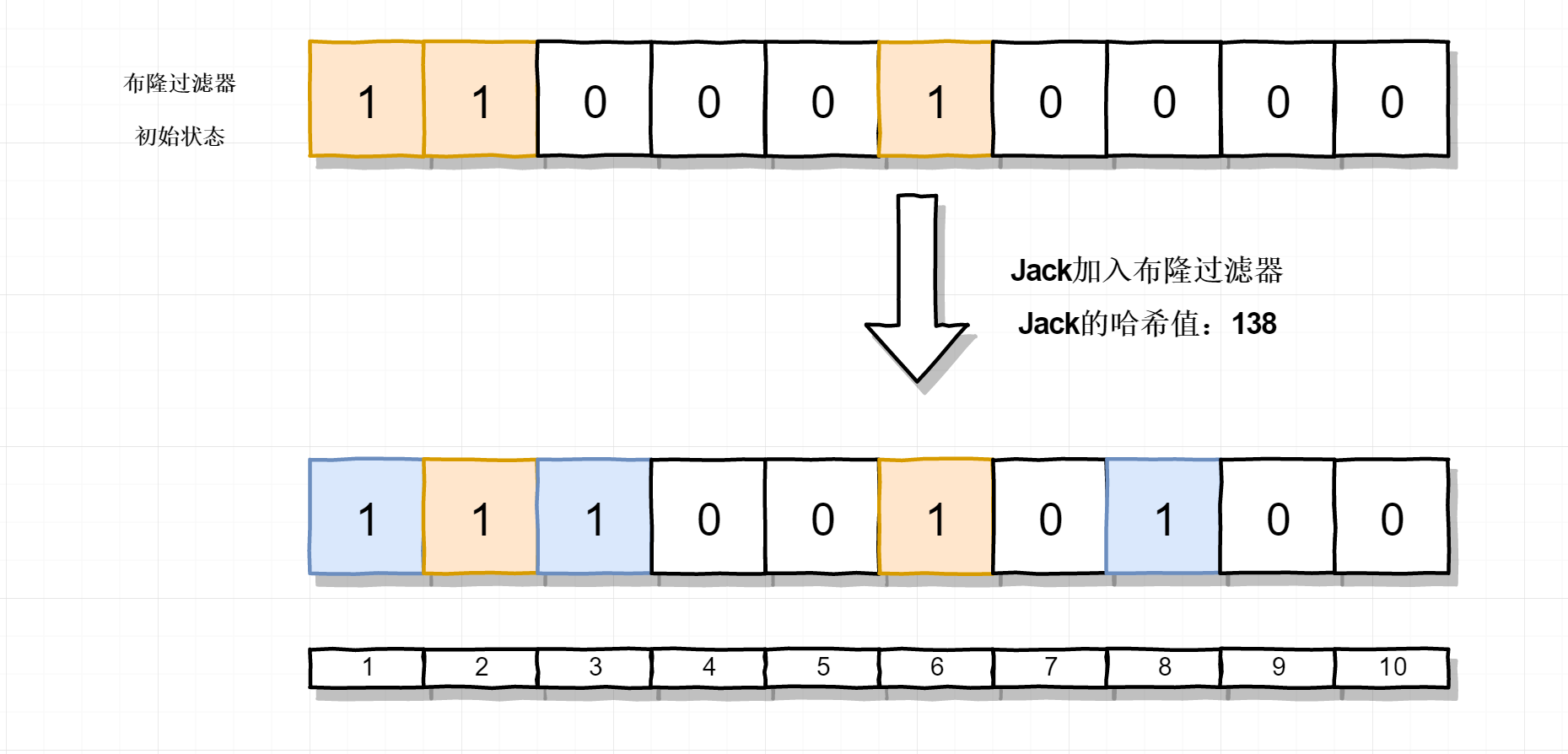
| Jack | [1,3,8] |
| Linda | [3,5,7] |
| Test | [1,2,6] |
把Tom加入到布隆过滤器,它的哈希值是 [1,2,6],把布隆过滤器中对应的位置为1,结果如下
把Jack加入到布隆过滤器,它的哈希值是 [1,3,8]。同样把布隆过滤器中对应的位置为1,注意此时布隆过滤器中1这个位置已经被Tom置为1了,我们忽略就行,结果如下
把Linda加入到布隆过滤器中,结果如下
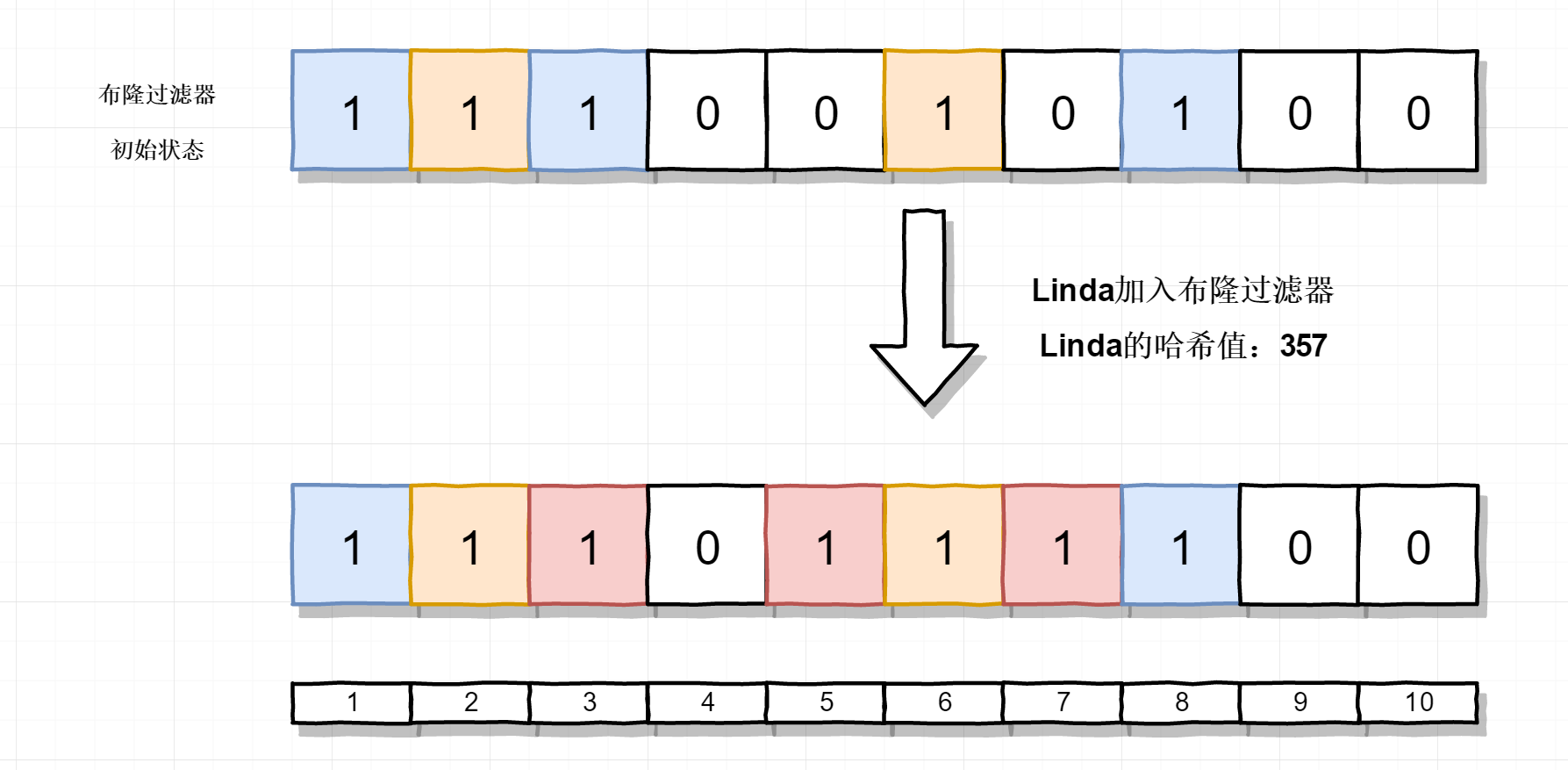
这就是布隆过滤器的工作原理了,上面表格中有一个Test用户,它的哈希值是 [1,2,6]。它是没有加入到布隆过滤器的,不过如果使用Test这条数据去测试布隆过滤器时,会发现它的哈希值都命中了,因此会返回 true。这时判断就出错了,这就是布隆过滤器的误判。通过布隆过滤器的工作原理,我们也可以推演出降低误判的方法是加长布隆过滤器的长度,我刚刚的例子中布隆过滤器的数组长度只有10,如果变成100,那么多哈希散列就会分散的多,大大降低了误判的可能。不过这并不能消除误判,只是降低了误判的概率。
Java实现简单的布隆过滤器
package edu.se;
import java.util.BitSet;
public class BloomFileter {
//使用加法hash算法,所以定义了一个8个元素的质数数组
private static final int[] primes = new int[]{2, 3, 5, 7, 11, 13, 17, 19};
//用八个不同的质数,相当于构建8个不同算法
private Hash[] hashList = new Hash[primes.length];
//创建一个长度为10亿的比特位
private BitSet bits = new BitSet(256 << 22);
public BloomFileter() {
for (int i = 0; i < primes.length; i++) {
//使用8个质数,创建八种算法
hashList[i] = new Hash(primes[i]);
}
}
//添加元素
public void add(String value) {
for (Hash f : hashList) {
//算出8个信息指纹,对应到2的32次方个比特位上
bits.set(f.hash(value), true);
}
}
//判断是否在布隆过滤器中
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (Hash f : hashList) {
//查看8个比特位上的值
ret = ret && bits.get(f.hash(value));
}
return ret;
}
//加法hash算法
public static class Hash {
private int prime;
public Hash(int prime) {
this.prime = prime;
}
public int hash(String key) {
int hash, i;
for (hash = key.length(), i = 0; i < key.length(); i++) {
hash += key.charAt(i);
}
return (hash % prime);
}
}
public static void main(String[] args) {
BloomFileter bloomFileter = new BloomFileter();
System.out.println(bloomFileter.contains("5324512515"));
bloomFileter.add("5324512515");
//维护1亿个在线用户
for (int i = 1 ; i < 100000000 ; i ++){
bloomFileter.add(String.valueOf(i));
}
long begin = System.currentTimeMillis();
System.out.println(begin);
System.out.println(bloomFileter.contains("5324512515"));
long end = System.currentTimeMillis();
System.out.println(end);
System.out.println("判断5324512515是否在线使用了:" + (begin - end));
}
}
布隆过滤器的核心点在于哈希算法的结果要足够分散,这对哈希算法要求比较高,如果哈希算法的结果不够分散,会增加布隆过滤器误判的概率。
灵魂拷问
布隆过滤器的原理也明白了,Java代码实现也给出来了,这个时候我们来思考一个问题
布隆过滤器可以删除元素吗?
在了解了布隆过滤器的工作原理后,我想这个问题已经很简单了,布隆过滤器是不支持删除的。因为布隆过滤器的每一个bit并不是独占的,很有可能多个元素共享了某一位。如果我们直接删除这一位的话,会影响其他的元素。比如例子中的Tom和Jack的哈希值就共用了布隆过滤器中的第一位,而Jack和Linda的哈希值共用了布隆过滤器中的第三位。如果我们直接删除把布隆过滤器中对应的位置为0的话,会影响到其他元素。当然,在一些必须要有删除功能的场景下,也是有办法的。方法也很简单,就是修改数据结构,将原本每一位一个bit改成一个int,当我们插入元素的时候,不再是将bit设置为true,而是让对应的位置自增,而删除的时候则是对应的位减一。这样,我们删除单个结果就不会影响其他元素了。这种方法并不是完美的,由于布隆过滤器存在误判的情况,很有可能我们会删除原本就不存在的值,这同样会对其他元素产生影响。
应用场景
- 数据库防止穿库 Google Bigtable,Apache HBase和Apache Cassandra以及Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能。 如同一开始的业务场景。如果数据量较大,不方便放在缓存中。需要对请求做拦截防止穿库。
- 缓存宕机 缓存宕机的场景,使用布隆过滤器会造成一定程度的误判。原因是除了Bloom Filter 本身有误判率,宕机之前的缓存不一定能覆盖到所有DB中的数据,当宕机后用户请求了一个以前从未请求的数据,这个时候就会产生误判。当然,缓存宕机时使用布隆过滤器作为应急的方式,这种情况应该也是可以忍受的。
- WEB拦截器 相同请求拦截防止被攻击。用户第一次请求,将请求参数放入BloomFilter中,当第二次请求时,先判断请求参数是否被BloomFilter命中。可以提高缓存命中率
- 恶意地址检测 chrome 浏览器检查是否是恶意地址。 首先针对本地BloomFilter检查任何URL,并且仅当BloomFilter返回肯定结果时才对所执行的URL进行全面检查(并且用户警告,如果它也返回肯定结果)。
- 比特币加速 bitcoin 使用BloomFilter来加速钱包同步。
- 网页爬虫对 URL 去重,避免爬取相同的 URL 地址;
- Medium 使用布隆过滤器避免推荐给用户已经读过的文章;
总结
布隆过滤器是一个优缺点都非常明显的数据结构,对于BloomFilter的优点来说,对于一些允许出现误差的业务场景,缺点都可以忽略。毕竟只需要很小的存储空间就能存储N个元素。空间效率十分优秀。这样特点鲜明的数据结构真的非常吸引人。
算法优点
- 数据空间小,不用存储数据本身。
算法缺点
- 元素可以添加到集合中,但不能被删除。
- 匹配结果只能是“绝对不在集合中”,并不能保证匹配成功的值已经在集合中。
- 当集合快满时,即接近预估最大容量时,误报的概率会变大。
- 数据占用空间放大。一般来说,对于1%的误报概率,每个元素少于10比特,与集合中的元素的大小或数量无关。 查询过程变慢,hash函数增多,导致每次匹配过程,需要查找多个位(hash个数)来确认是否存在。



