在应用系统中,常需要把热点数据存储到缓存中,减少磁盘的交互,为了节约内存,我们通常只存储热点数据,而动态的淘汰访问量较少的数据。这里就需要用到淘汰算法,redis的缓存数据失效机制就是一个很好的淘汰算法例子,我们知道redis数据默认有效时间是30分钟,在30分钟内没有续时就会自动被移除,这样对于热点数据因为访问频繁,所以一直得到了续时并保留在了内存中,而冷门数据就会被移除,需要注意的是redis续时操作需要手动的代码执行。那么如果要自己实现一个缓存淘汰容器应该怎么做呢,本文汇总了常见的缓存数据淘汰算法。
LRU(Least Recently Used)
LRU(又叫最近最久未使用算法)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是如果数据最近被访问过,那么将来被访问的几率也更高。而最近一段时间都没有使用的数据,很大概率不会再使用。做法是把最长时间未被访问的数据置换出去。这种算法是完全从最近使用的时间角度去考虑的。最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
- 新数据插入到链表头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 当链表满的时候,将链表尾部的数据丢弃。
LRU有点是实现简单,只需要一个链表就可以实现,不过缺点也很明显,缓存污染情况比较严重,所谓缓存污染即如果某个客户端偶发性的或周期性的批量访问大量历史数据时,会使缓存中的数据被这些历史数据替换掉,从而使其他客户端访问数据的命中率大大降低。此外还有一个缺点,每次数据来访问时需要遍历链表,找到命中的数据索引,然后将数据移到头部。
Java中LinkedHashMap就是包含了基于LRU算法实现集合容器,如果没太关注过LinkedHashMap的话,可能并不知道它还有LRU的功能,LinkedHashMap实现了LRU其中的99%,但是得做一点小小的改动,需要覆写其中的removeEldestEntry(Map.Entry)方法,LinkedHashMap默认是按数据的插入顺序排序的,但它提供了一个参数accessOrder,当accessOrder为true使用访问顺序排序,false使用插入顺序排序。只需要在创建时赋值就行了,如下
Map<String, String> map = new LinkedHashMap<String, String>(16,0.75f,true);下面我用图来表示LRU算法具体过程:
链表没有满的情况,新数据A来访问,直接把A插入到队列的头部
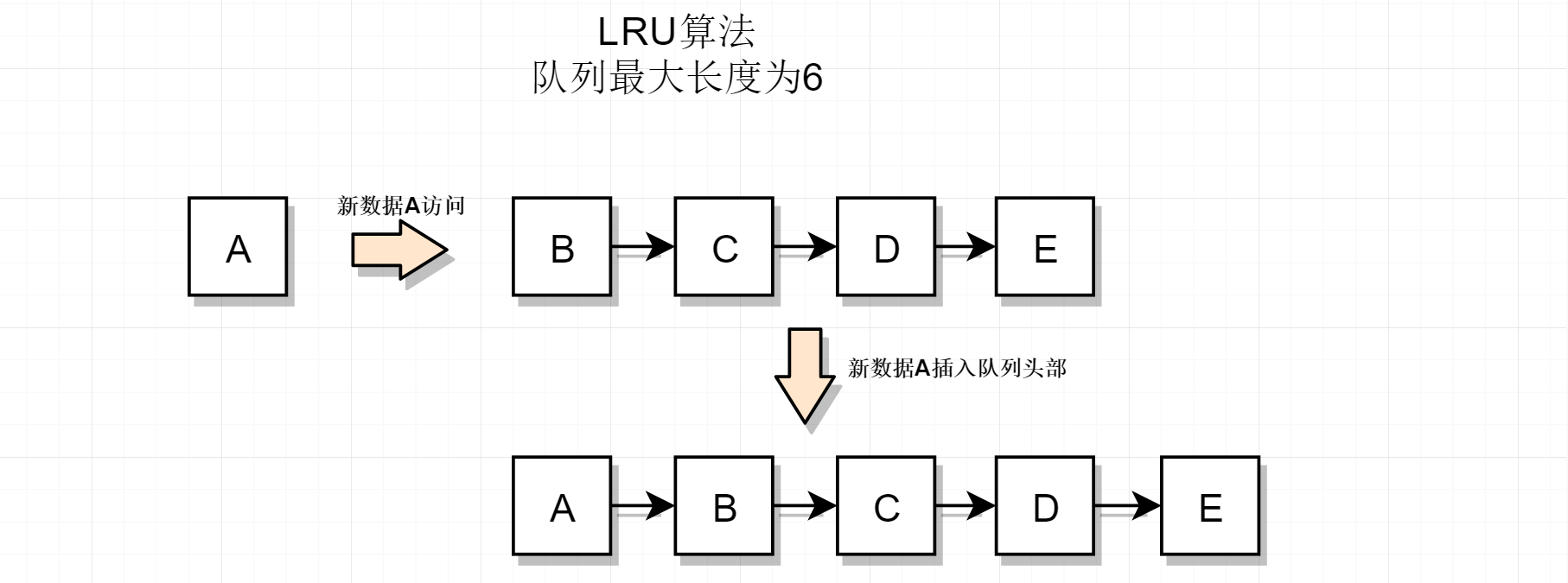
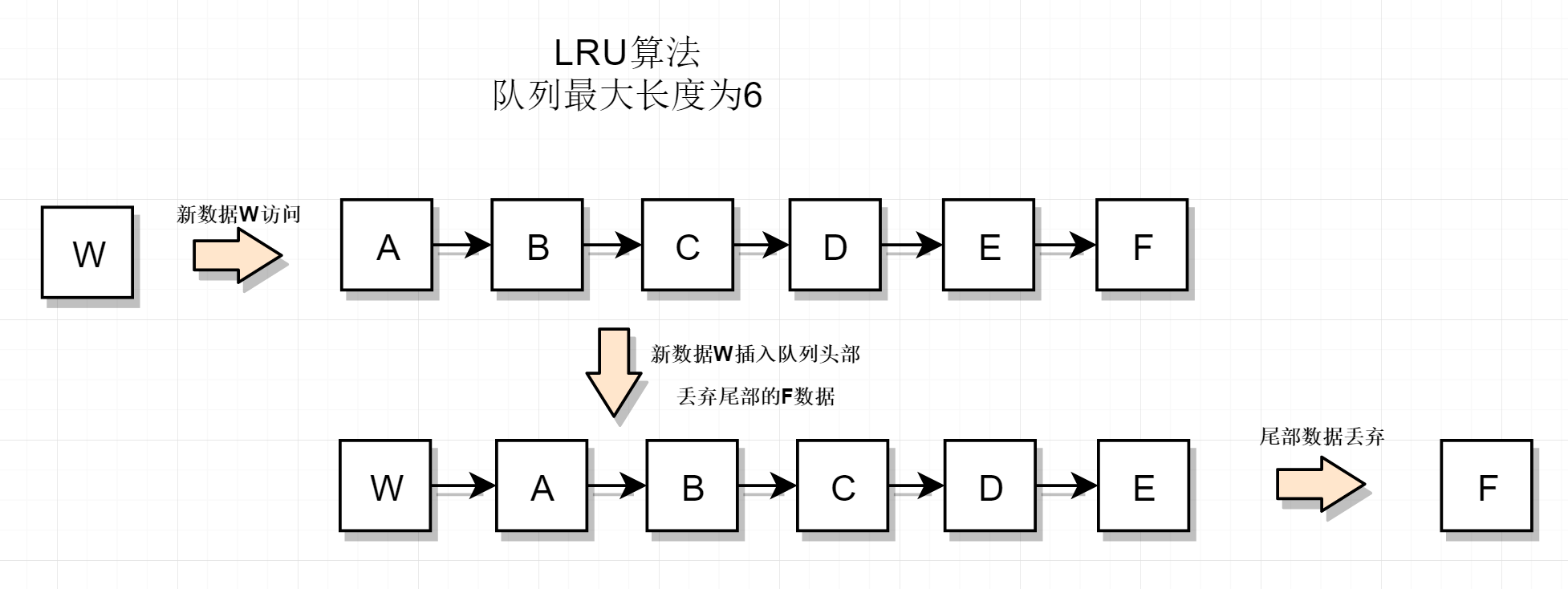
链表已满,新数据来访问时,把链表尾部的数据淘汰,新数据插入到链表头部
具体LRU实现代码如下
public class LRUCache {
Entry head, tail;
int capacity;
int size;
// 哈希缓存,降低时间复杂度
Map<Integer, Entry> cache;
public LRUCache(int capacity) {
this.capacity = capacity;
// 初始化链表
initLinkedList();
size = 0;
cache = new HashMap<>(capacity + 2);
}
/**
* 如果节点不存在,返回 -1.如果存在,将节点移动到头结点,并返回节点的数据。
*/
public int get(int key) {
Entry node = cache.get(key);
if (node == null) {
return -1;
}
// 存在移动节点
moveToHead(node);
return node.value;
}
/**
* 将节点加入到头结点,如果容量已满,将会删除尾结点
*/
public void put(int key, int value) {
Entry node = cache.get(key);
if (node != null) {
node.value = value;
moveToHead(node);
return;
}
// 不存在。先加进去,再移除尾结点
// 此时容量已满 删除尾结点
if (size == capacity) {
Entry lastNode = tail.pre;
deleteNode(lastNode);
cache.remove(lastNode.key);
size--;
}
// 加入头结点
Entry newNode = new Entry();
newNode.key = key;
newNode.value = value;
addNode(newNode);
cache.put(key, newNode);
size++;
}
private void moveToHead(Entry node) {
// 首先删除原来节点的关系
deleteNode(node);
addNode(node);
}
private void addNode(Entry node) {
head.next.pre = node;
node.next = head.next;
node.pre = head;
head.next = node;
}
private void deleteNode(Entry node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
public static class Entry {
public Entry pre;
public Entry next;
public int key;
public int value;
public Entry(int key, int value) {
this.key = key;
this.value = value;
}
public Entry() {
}
}
private void initLinkedList() {
head = new Entry();
tail = new Entry();
head.next = tail;
tail.pre = head;
}
public static void main(String[] args) {
LRUCache cache = new LRUCache(2);
cache.put(1, 1);
cache.put(2, 2);
System.out.println(cache.get(1));
cache.put(3, 3);
System.out.println(cache.get(2));
}
}
也可以直接用LinkedHashMap实现,这样代码更简单
// 继承LinkedHashMap
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int MAX_CACHE_SIZE;
public LRUCache(int cacheSize) {
// 使用构造方法 public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)
// initialCapacity、loadFactor都不重要
// accessOrder要设置为true,按访问排序
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
MAX_CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
// 超过阈值时返回true,进行LRU淘汰
return size() > MAX_CACHE_SIZE;
}
}LRU-K
缓存命中率是缓存系统的非常重要指标,如果缓存系统的缓存命中率过低,将会导致查询回流到数据库,导致数据库的压力升高。LRU 算法劣势在于对于偶发的批量操作,比如说批量查询历史数据,就有可能使缓存中热门数据被这些历史数据替换,造成缓存污染,导致缓存命中率下降,减慢了正常数据查询。
因此出现了LRU-K,它是对上面LRU算法的改进。LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法缓存污染的问题,其核心思想是将最近使用过1次的判断标准扩展为最近使用过K次。也就是说没有到达K次访问的数据并不会被缓存,这也意味着需要对于缓存数据的访问次数进行计数,并且访问记录不能无限记录,也需要使用替换算法进行替换。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。简单的描述就是:
当访问次数达到K次后,将数据索引从历史队列移到缓存队列中(缓存队列时间降序);缓存数据队列中被访问后重新排序;需要淘汰数据时,淘汰缓存队列中排在末尾的数据
相比于LRU-1,缓存数据更不容易被替换,而且偶发性的数据不易被缓存。在保证了缓存数据纯净的同时还提高了热点数据命中率。命中率要比LRU要高,但是因为需要维护一个历史队列,因此内存消耗会比LRU多。实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
Two queues(2Q)
2Q算法其实是LRU-K的一个具体实现版本LRU-2,它的算法思想是:使用两个队列来保存数据,一个历史队列和一个LRU队列,2Q的历史队列是采用FIFO的方法进行缓存的。FIFO原理就不多介绍了吧,学过数据结构的都应该知道,它是一个先进先出队列。如果一个数据被首次访问,它会放到历史队列中,当这个数据再次被访问时,会把它移到LRU队列中
工作原理
2Q算法维护两个队列:历史队列(采用FIFO的淘汰策略)和缓存队列(采用LRU-1的淘汰策略)
- 新访问的数据插入到FIFO队列
- 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰
- 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部
- 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部
- LRU队列淘汰末尾的数据
缺点跟LRU-K一致,其实2Q算法就是LRU-2,并且历史队列采用了FIFO的淘汰策略。下面用图表示2Q算法的执行过程。
新数据来访情况
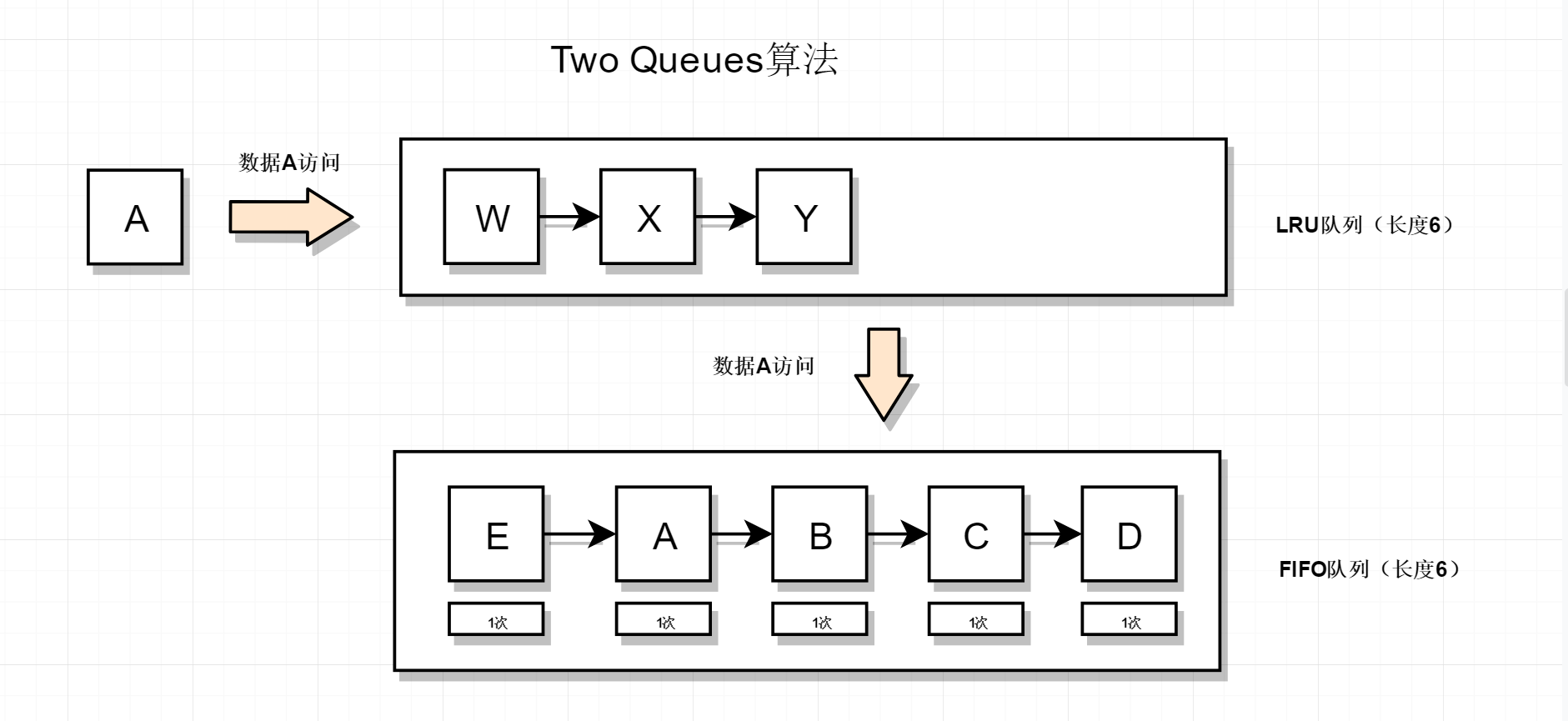
初始状态如下,此时新数据E来访
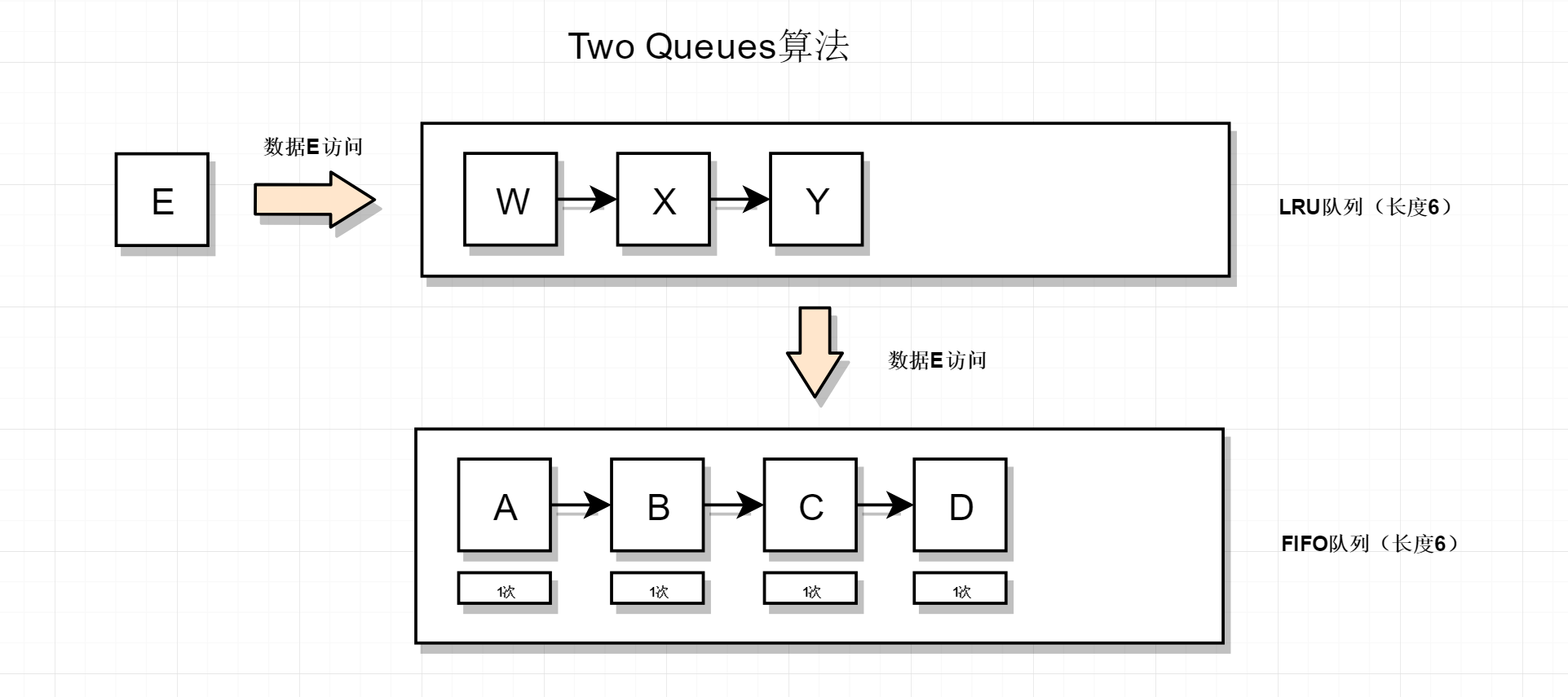
先查询LRU队列,发现没有E数据,然后查询FIFO队列,也没有找到E数据,于是把E数据插入到FIFO队列头部
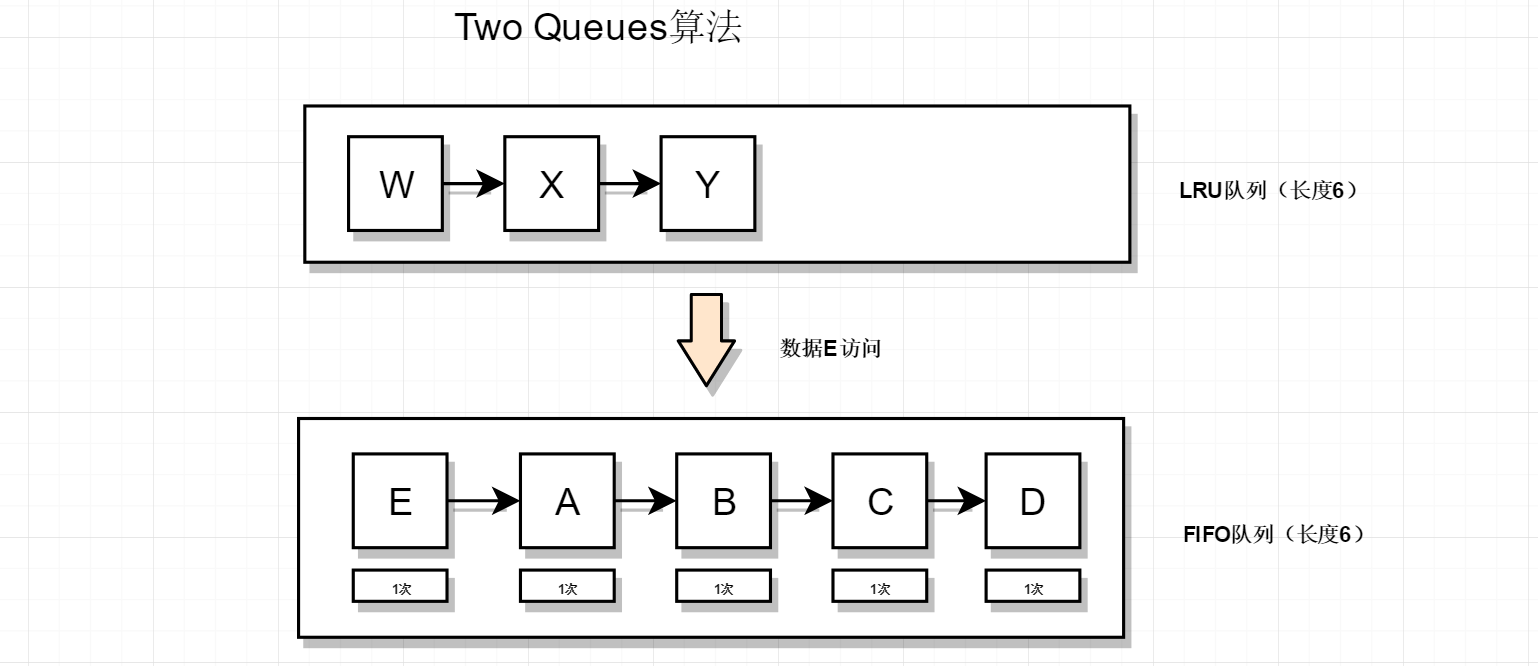
历史数据来访
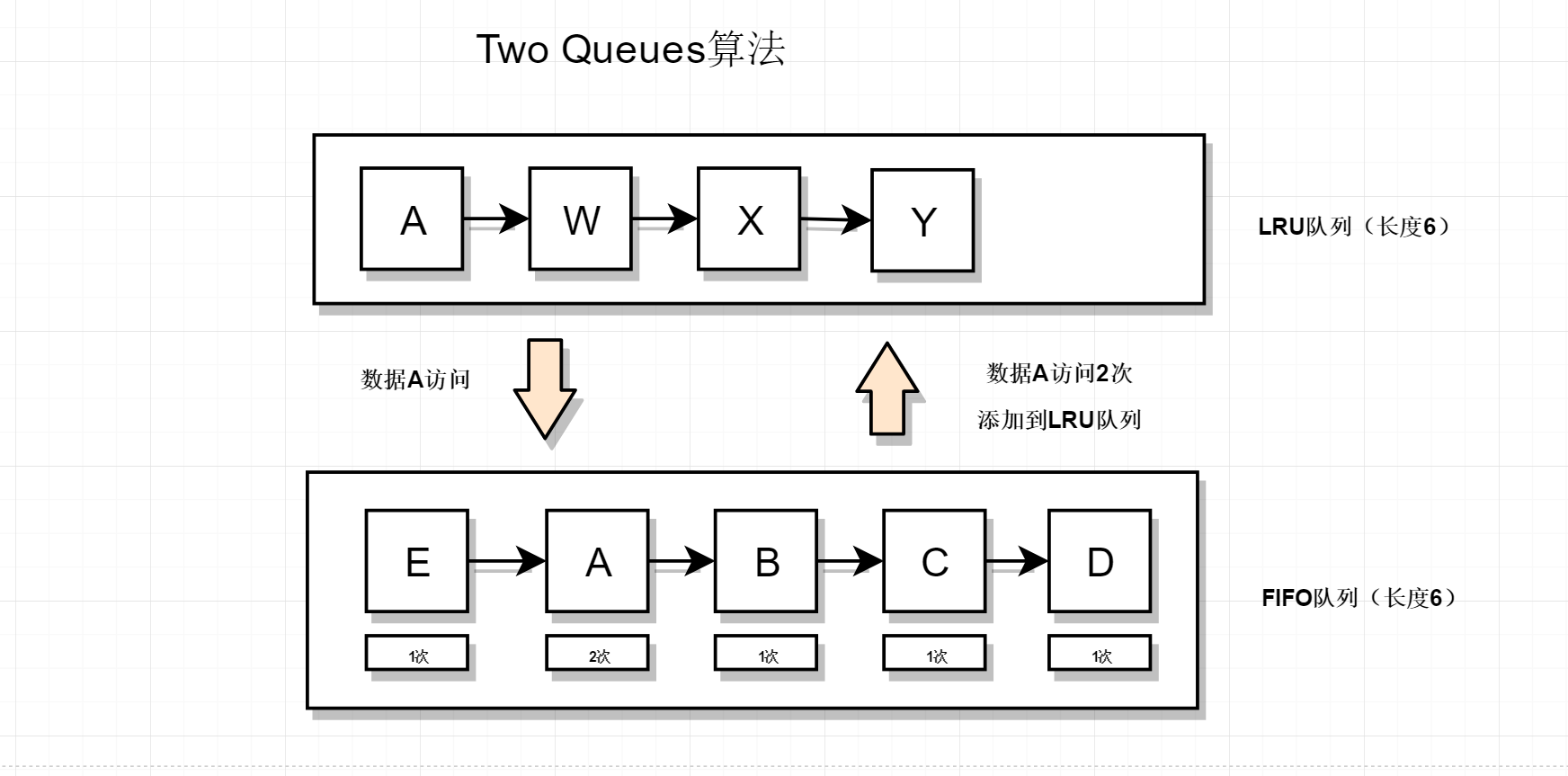
接着上图的结果,此时历史数据A来访,如下
先查询LRU队列,发现没有E数据,然后查询FIFO队列,此时A再FIFO队列中有数据,说明A数据这是第二次被访问,所以把A数据移到LRU队列(注意FIFO队列不需要删除A数据,因为A数据是按先进先出去删除数据的),所以结果如下
2Q算法命中率要高于LRU,需要两个队列,但两个队列本身都比较简单。代码实现并不麻烦。当然我们在使用缓存的时候也不需要自己去实现缓存算法,Java中有现成的框架可以直接拿来使用,Redis就不用说了,它是一个单独的服务,是个中间件。在本地使用的Java框架有cache4j,EhCache;其中cache4j是一款轻量级java内存缓存框架,实现FIFO、LRU、TwoQueues缓存模型,使用非常方便,它的特点是支持并发,使用简单,命中率稳定。使用示例:
// 配置
CacheConfig config = CacheConfig.custom().setMaxElement(10000); // 缓存元素个数上限
// 缓存节点工厂
INodeFactory<String, Object> cachefFactory = new CacheNodeFactory<String, Object>();
// 缓存模型
TwoQueuesCache<String, Object> tqc = new TwoQueuesCache<String, Object>(config, cachefFactory);
// 缓存
tqc.put("a", "av");
// 获取缓存元素
tqc.get("a");cache4j适用于本地缓存,相比EhCache更加轻量简单,EhCache自1.2后支持集群,也是hibernate 默认的缓存CacheProvider。所以配置起来稍显复杂,不过功能也更强大。



