乔治·桑塔亚纳说过,“那些遗忘过去的人注定要重蹈覆辙。”这句话放在问题求解过程中也同样适用。不懂动态规划的人会在解决过的问题上再次浪费时间,懂的人则会事半功倍。那么什么是动态规划?这种算法有何神奇之处?对于动态规划我虽然早有耳闻,但一直未曾了解过。动态规划很难吗?其实并不难,当你真正学明白后甚至会觉得动态规划的思想很简单,如果你高中数学比较好的话,理解动态规划就更容易了,因为动态规划是核心思想其实就是高中数学学习过的数学归纳法。哈哈,是不是对程序就是数据结构+数学这句话又有了更深的认识了。
数学归纳法
数学归纳法(Mathematical Induction, MI)是一种数学证明方法,通常被用于证明某个给定命题在整个(或者局部)自然数范围内成立。虽然数学归纳法名字中有“归纳”,但是数学归纳法并非不严谨的归纳推理法,它属于完全严谨的演绎推理法。事实上,所有数学证明都是演绎法。最简单和常见的数学归纳法是证明当n等于任意一个自然数时某命题成立。证明分下面两步
- 证明当n= 1时命题成立。
- 假设n=k时命题成立,那么可以推导出在n=k+1时命题也成立。(k代表任意自然数)
举个例子,求自然数前n项的和
证明:S(n) = 1 + 2 + 3 …. + n 前n项和为n(n + 1) / 2
n = 1, S(1) = 1
假设n时命题成立
N+ 1时,
S(n + 1)
= S(n) + n + 1
= n(n + 1)/2 + n + 1
= (n + 1)(n + 2)/ 2
成立动态规划
动态规划的前两步跟数学归纳法一模一样,不同的是动态规划常会引入一个DP数组用来存储中间结果,就是利用历史记录,来避免我们的重复计算。而这些历史记录,我们得需要一些变量来保存,一般是用一维数组或者二维数组来保存。DP数组的作用主要有两个,一可以避免一些重复计算,降低算法复杂度。二DP数组中存储的都是历史数据,我们需要从历史数据推演出下一个结果(因为归纳法就是从前面的数据推导下一个数据结果)
- 状态转移方程:所谓状态转移方程就是能通过前几项推出下一项的关系式,当我们要计算 dp[n] 时,是可以利用 dp[n-1],dp[n-2]…..dp[1],来推出 dp[n] 的,也就是可以利用历史数据来推出新的元素值,所以我们要找出数组元素之间的关系式,例如 dp[n] = dp[n-1] + dp[n-2],这个就是他们的关系式了。而这一步,也是最难的一步,后面我会讲几种类型的题来说。
- 找出初始值:学过数学归纳法的都知道,虽然我们知道了数组元素之间的关系式,例如 dp[n] = dp[n-1] + dp[n-2],我们可以通过 dp[n-1] 和 dp[n-2] 来计算 dp[n],但是,我们得知道初始值啊,例如一直推下去的话,会由 dp[3] = dp[2] + dp[1]。而 dp[2] 和 dp[1] 是不能再分解的了,所以我们必须要能够直接获得 dp[2] 和 dp[1] 的值,而这,就是所谓的初始值。
- 定义DP数组元素:我们会用一个数组,来保存历史数组,假设用一维数组 dp[] 吧。这个时候有一个非常非常重要的点,就是规定你这个数组元素的含义,例如你的 dp[i] 是代表什么意思
动态规划有两种不同的解决问题的思路
自上而下:你从最顶端开始不断地分解问题,直到你看到问题已经分解到最小并已得到解决,之后只用返回保存的答案即可。这叫做记忆存储(Memoization)。自下而上:你可以直接开始解决较小的子问题,从而获得最好的解决方案。在此过程中,你需要保证在解决问题之前先解决子问题。这可以称为表格填充算法(Tabulation,table-filling algorithm)。
算法原理
通过前面的表述,或许对动态规划算法仍然难以理解其过程。下面通过斐波那契数列问题来详解动态规划的基本原理,不要嫌弃这个例子简单,只有简单的例子才能让你把精力充分集中在算法背后的通用思想和技巧上,而不会被那些隐晦的细节问题搞的莫名其妙。大多复杂的算法都是在简单的算法思想上加以演变优化的。斐波那契数列对于任何一个开发者应该都不陌生,相信大家在初学语言时,或多或少都碰到过这样一道题,用程序实现求斐波那契数列的任意一项的值。
暴力求解斐波那契
斐波那契数列(Fibonacci sequence),又称黄金分割数列、因数学家莱昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”,指的是这样一个数列。斐波那契数列指的是这样一个数列:
1、1、2、3、5、8、13、21、34、55、...这个数列从第3项开始,每一项都等于前两项之和。我们尝试用动态规划的算法来解决这个问题,根据前面的总结的动态规范三步走,首先找出状态转移方程,这个很简单了题干中已经说明,斐波那契数列从第3项开始,每一项都等于前两项之和,那么很容易得出关系式 F(n) = F(n-1)+F(n-2),第二步找出初始值,也很容易数列的前两项是不满足关系式的,因此得出初始值分别为 F(1)=1,F(2)=1。第三步是动态规划优化的过程,我们暂时不用,继而可以得到代码实现
int fib(int n) {
if (n == 1 || n == 2) return 1;
return fib(n - 1) + fib(n - 2);
}这样写代码虽然简洁易懂,但是十分低效,低效在哪里?但凡遇到需要递归的问题,最好都画出递归树,这对你分析算法的复杂度,寻找算法低效的原因都有巨大帮助。
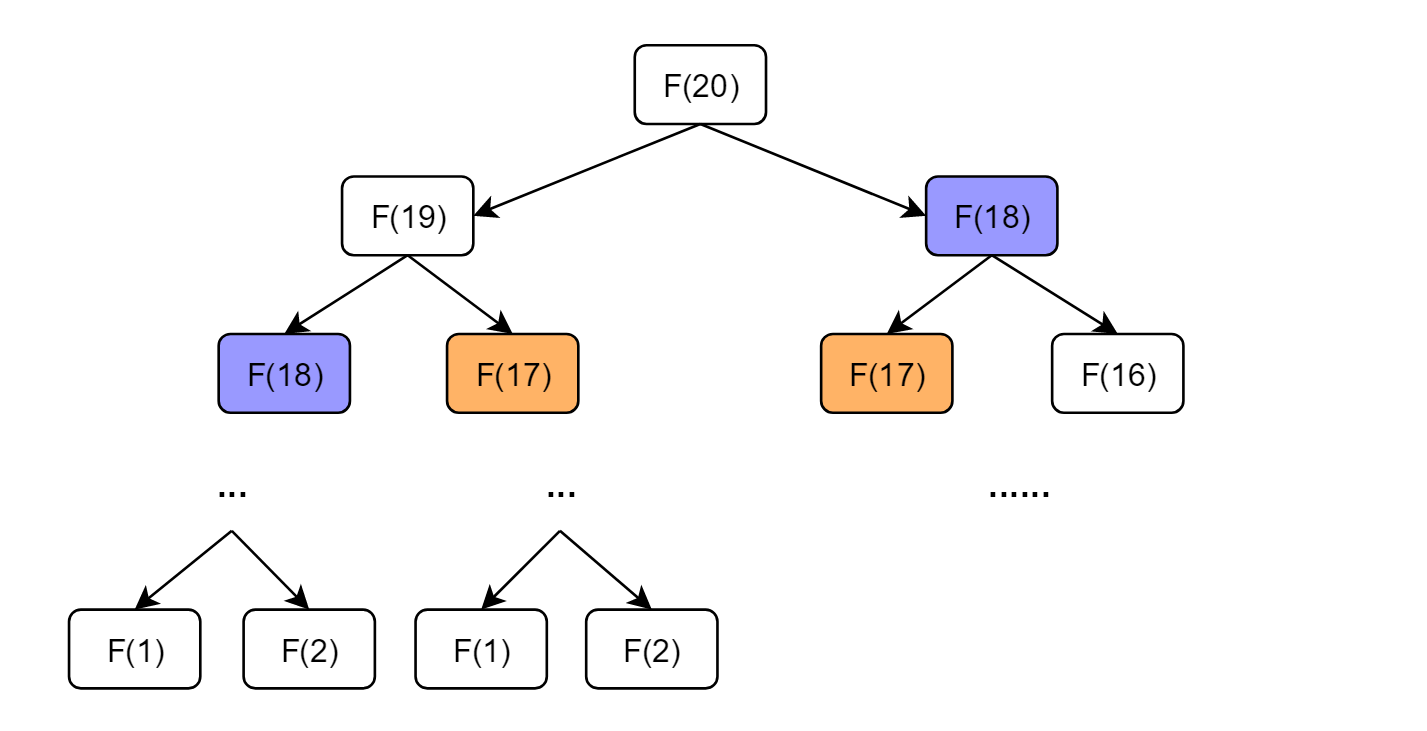
这个递归树怎么理解?就是说想要计算原问题 f(20),我就得先计算出子问题 f(19) 和 f(18),然后要计算 f(19),我就要先算出子问题 f(18) 和 f(17),以此类推。最后遇到 f(1) 或者 f(2) 的时候,结果已知,就能直接返回结果,递归树不再向下生长了。子问题个数,即递归树中节点的总数。显然二叉树节点总数为指数级别,所以子问题个数为 O(2^n)。解决一个子问题的时间,在本算法中,没有循环,只有 f(n - 1) + f(n - 2) 一个加法操作,时间为 O(1)。所以,这个算法的时间复杂度为 O(2^n),指数级别,爆炸。观察递归树,我们可以明显发现,存在大量重复计算,比如 f(18) 被计算了两次,而且你可以看到,以 f(18) 为根的这个递归树体量巨大,多算一遍,会耗费巨大的时间。更何况,还不止 f(18) 这一个节点被重复计算,所以这个算法及其低效。这就是动态规划问题的第一个性质:重叠子问题。下面,我们想办法解决这个问题。我想聪明的你应该想到了,我在用动态规划时,只使用了前面两步,现在我们把第三步用上。
剪枝求解斐波那契
明确了问题,其实就已经把问题解决了一半。即然耗时的原因是重复计算,那么我们可以造一个「备忘录」,每次算出某个子问题的答案后别急着返回,先记到「备忘录」里再返回;每次遇到一个子问题先去「备忘录」里查一查,如果发现之前已经解决过这个问题了,直接把答案拿出来用,不要再耗时去计算了。因此我们定义一个DP数组用来保存中间结果。代码如下
public class Test {
private static Map<Integer,Integer> dpMap = new HashMap<>();
public static void main(String[] args){
// 初始化前两项
dpMap.put(1,1);
dpMap.put(2,1);
System.out.println(fib(7));
}
static int fib(int n) {
if (n == 1 || n == 2) return 1;
// 如果计算过了就直接取值返回
if (dpMap.get(n) != null) return dpMap.get(n);
int m = fib(n-1)+fib(n-2);
//保存中间结果
dpMap.put(n,m);
return m;
}
}实际上,带「备忘录」的递归算法,把一棵存在巨量冗余的递归树通过「剪枝」,改造成了一幅不存在冗余的递归图,极大减少了子问题(即递归图中节点)的个数。剪枝后的递归算法的时间复杂度怎么算?子问题个数乘以解决一个子问题需要的时间。子问题个数,即图中节点的总数,由于本算法不存在冗余计算,子问题就是 f(1), f(2), f(3) … f(20),数量和输入规模 n = 20 成正比,所以子问题个数为 O(n)。解决一个子问题的时间,同上,没有什么循环,时间为 O(1)。所以,本算法的时间复杂度是 O(n)。比起暴力算法,是降维打击。
至此,带备忘录的递归解法的效率已经和迭代的动态规划解法一样了。实际上,这种解法和迭代的动态规划已经差不多了,只不过这种方法叫做「自顶向下」,动态规划一般是「自底向上」。啥叫「自顶向下」?注意我们刚才画的递归树(或者说图),是从上向下延伸,都是从一个规模较大的原问题比如说 f(20),向下逐渐分解规模,直到 f(1) 和 f(2) 触底,然后逐层返回答案,这就叫「自顶向下」。啥叫「自底向上」?反过来,我们直接从最底下,最简单,问题规模最小的 f(1) 和 f(2) 开始往上推,直到推到我们想要的答案 f(20),这就是动态规划的思路,这也是为什么动态规划一般都脱离了递归,而是由循环迭代完成计算。那么我们可以把刚刚自顶向下的斐波那契数列解法,用自底向上实现吗?当然是可以的,而且思路更加简单了
自底向上解斐波那契数列
上一步「备忘录」的启发,我们可以把这个「备忘录」独立出来成为一张表,就叫做 DP table ,在这张表上完成「自底向上」的推算岂不美哉!代码实现如下
public class Test {
private static Map<Integer,Integer> dpMap = new HashMap<>();
public static void main(String[] args){
// 初始化前两项
dpMap.put(1,1);
dpMap.put(2,1);
System.out.println(fibs(7));
}
static int fibs(int n) {
for (int i = 3; i <= n; i++){
int m = dpMap.get(i-1)+dpMap.get(i-2);
//保存中间结果
dpMap.put(i,m);
}
return dpMap.get(n);
}
}迭代实现和剪枝后的递归实现算法复杂度是一样的,所以说这两种解法其实是差不多的,大部分情况下,效率也基本相同,时间复杂度都是O(n)。这里,引出「状态转移方程」这个名词,实际上就是描述问题结构的数学形式:
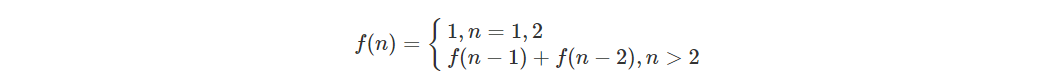
「状态转移方程」听起来高端。实际上就是你想求 f(n) ,这个状态 n 是由状态 n - 1 和状态 n - 2 相加转移而来,这就叫状态转移,仅此而已。
总结
通过数学归纳法和斐波那契数列的求解例子,对动态规划应该能理解透彻了。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多。那么动态规划适合解决哪类问题呢?一般是最值问题,比如说让你求最长递增子序列呀,最小编辑距离呀,两个字符串的最长公共子序列呀等等,其实动态规划本质上求的是最优解。一般碰到题目中包含最长,最短等字眼的算法题,实际上就是在求最优解,因为题目的解不止一个,所以才要求最长,最短解。所以碰到最字眼时,首先就可用考虑使用动态规划去进行分析。动态规划三步走,1.求状态转移方程(这一步往往是最难的)。2。求初始最。3.使用DP表,降低时间复杂度。



