随着系统规模的不断增加,数据量和并发量不断增大,整个系统架构中最先受到冲击而形成瓶颈的,定然是数据库。一般的Web服务基本上都是IO密集型服务,因此系统架构的性能重点就在于数据库的架构设计,任何一家互联网公司(比如淘宝、京东、新浪)它的交易TPS可以轻松突破几十万。他们使用了规模更大的服务集群和缓存来提升TPS,但最终所有的数据都来源于DB,因此数据库的TPS实际上就决定了系统性能的上限。数据库优化法则
- 减少数据访问(减少磁盘访问,如select * 改成指定字段查询,同时更少的数据也减少了网络传输需要的带宽)
- 减少交互次数(减少网络传输和IO次数,如使用缓存降低数据库访问次数)
- 减少服务器CPU开销(减少CPU及内存开销,如使用比较、排序、函数或逻辑运算会增加CPU开销)
- 利用更多资源(增加资源,水平扩展CPU,内存和磁盘)
几乎任何规模的互联网公司,都有自己的系统架构迭代和更新,大致的演化路径都大同小异。这里就从架构演化的角度来谈论每个阶段数据库优化的手段
单体应用
最早一般为了业务快速上线,所有功能都会放到一个应用里,这个架构是最原始也是最简单的设计,项目建构初期几乎不用有太多的顾虑
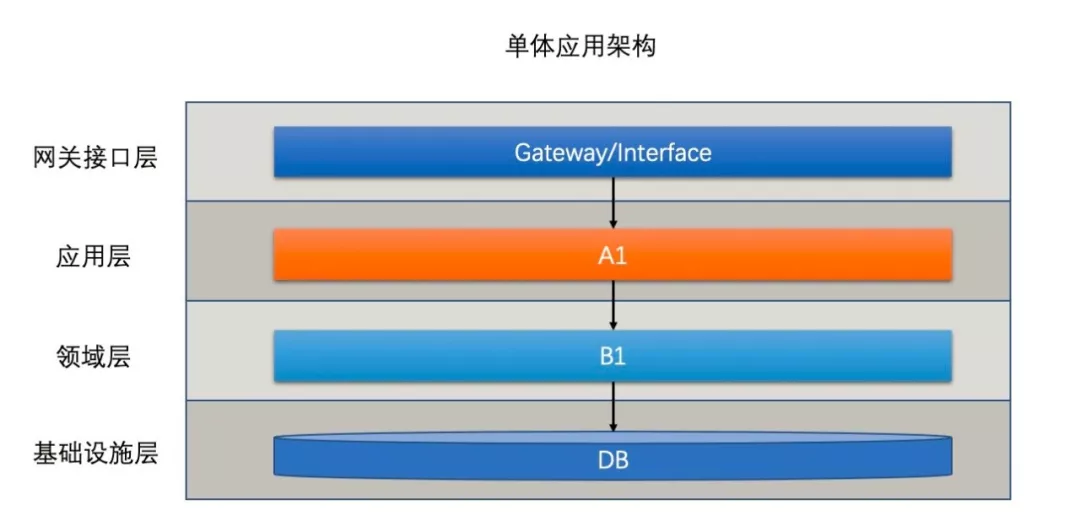
在这种架构下,所有的业务集中在一个服务里,所有业务数据放在一个数据库中。这种情况下的优化手段也很有限一般就是SQL优化,或者在应用和DB之间加一个缓存(一般使用Redis),SQL优化手段
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引
应尽量避免在 where 子句中对字段进行 null 值判断,null判断会导致全表扫描
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
任何地方都不要使用 select * from t ,用具体的字段列表代替 ‘’ * ‘’,不要返回用不到的任何字段。
很多时候用 exists 代替 in 是一个好的选择,如
select num from a where num in(select num from b) -- 替换为exists select num from a where exists(select 1 from b where num=a.num)索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了
insert及update的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如
select id from t where substr(name,1,3)='abc' -- 查询name以abc开头的id ,改为 select id from t where name like 'abc%'注意
like查询,当使用%abc%会走全表扫描,而使用abc%会走索引尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理
如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
设置Fetch Size,当我们采用select从数据库查询数据时,数据默认并不是一条一条返回给客户端的,也不是一次全部返回客户端的,而是根据客户端fetch_size参数处理,每次只返回fetch_size条记录,当客户端游标遍历到尾部时再从服务端取数据,直到最后全部传送完成。所以如果我们要从服务端一次取大量数据时,可以加大fetch_size,这样可以减少结果数据传输的交互次数及服务器数据准备时间,提高性能。jdbc测试的代码,采用本地数据库
String vsql ="select * from t_employee"; PreparedStatement pstmt = conn.prepareStatement(vsql,ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY); pstmt.setFetchSize(1000); ResultSet rs = pstmt.executeQuery(vsql); int cnt = rs.getMetaData().getColumnCount(); Object o; while (rs.next()) { for (int i = 1; i <= cnt; i++) { o = rs.getObject(i); } }数据库并行处理,数据库并行处理是指客户端一条SQL的请求,数据库内部自动分解成多个进程并行处理,并不是所有的SQL都可以使用并行处理,一般只有对表或索引进行全部访问时才可以使用并行。数据库表默认是不打开并行访问,所以需要指定SQL并行的提示,如下Oracle数据库并行sql
select /*+parallel(a,4)*/ a.* from employee a;其中a是表的别名,4是并行度。一般查询中使用parallel的情景如下:需要大量的表的扫描、连接或者分区索引扫描。聚合操作(计数),使用多进程处理,充分利用数据库主机资源(CPU和IO),提高性能。注意
- 行处理在联机事务处理(OLTP)类系统中慎用,使用不当会导致一个会话把主机资源全部占用,而正常事务得不到及时响应,所以一般只是用于数据仓库平台。
- 一般对于百万级记录以下的小表采用并行访问性能并不能提高,反而可能会让性能更差。
- 并行查询只能采用直接IO访问,不能利用缓存数据,所以执行前会触发将脏缓存数据写入磁盘操作
表分区应用
数据分区是一种物理数据库的设计技术,它的目的是为了在特定的SQL操作中减少数据读写的总量以缩减响应时间。分区并不是生成新的数据表,而是将表的数据均衡分摊到不同的硬盘,实际上还是一张表。另外,分区可以做到将表的数据均衡到不同的地方,提高数据检索的效率,降低数据库的频繁IO压力值
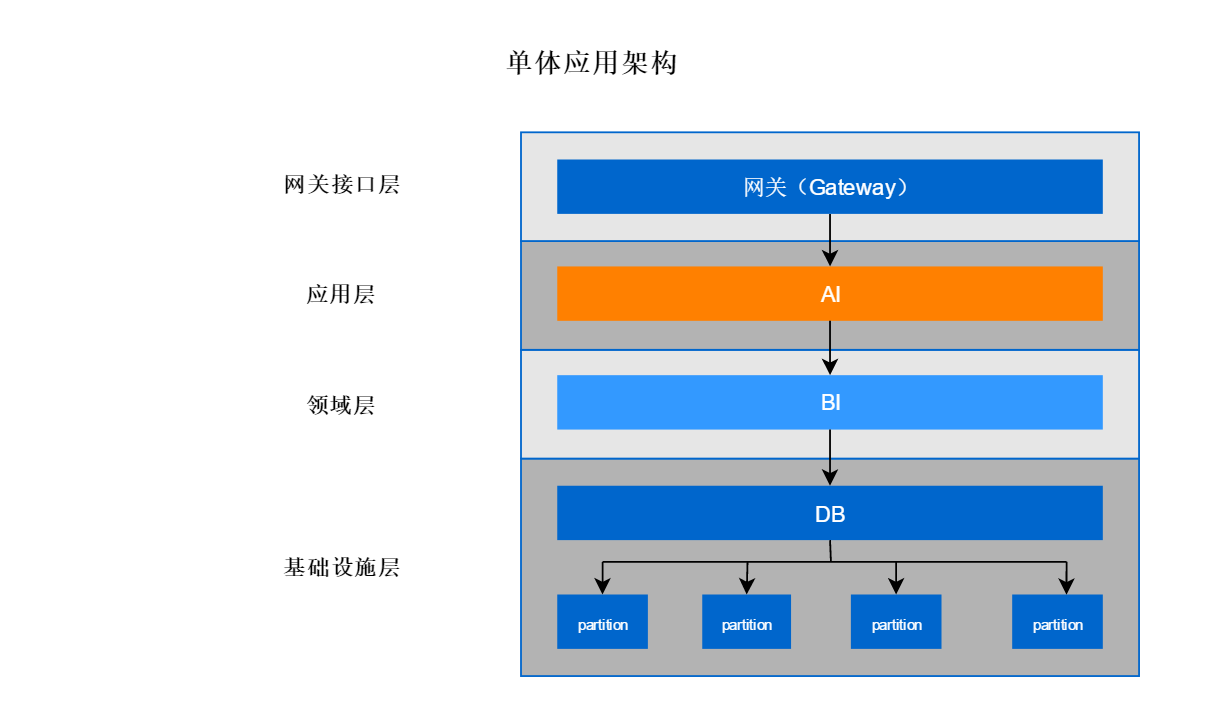
简而言之,就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的。表的分区可以分摊到不同的硬盘,系统或是不同服务器存储介子中,分区的优点如下:
- 相对于单个文件系统或是硬盘,分区可以存储更多的数据;
- 数据管理比较方便,比如要清理或废弃某年的数据,就可以直接删除该日期的分区数据即可
- 精准定位分区查询数据,不需要全表扫描查询,大大提高数据检索效率
- 可跨多个分区磁盘查询,来提高查询的吞吐量
- 在涉及聚合函数查询时,可以很容易进行数据的合并
Mysql5 开始支持分区功能,创建分区表sql如下
---根据年份分区
CREATE TABLE sales (
id INT AUTO_INCREMENT,
amount DOUBLE NOT NULL,
order_day DATETIME NOT NULL,
PRIMARY KEY(id, order_day)
) ENGINE=Innodb
PARTITION BY RANGE(YEAR(order_day)) (
PARTITION p_2010 VALUES LESS THAN (2010),
PARTITION p_2011 VALUES LESS THAN (2011),
PARTITION p_2012 VALUES LESS THAN (2012),
PARTITION p_catchall VALUES LESS THAN MAXVALUE);
---根据数值范围分区
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null default 0,
store_id int not null default 0
)engine=myisam default charset=utf8
partition by range(store_id)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21)
);Mysql支持的分区策略:
- RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区
- LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择
- HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
- KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值
读写分离
随着数据量的不断增大,对于上述单体应用架构,显然是有问题的,单机有着明显的单点效应,单机的容量和性能都是很局限的,而使用中小型机会带来大量的浪费。于是就着手于应用的水平扩展,它将多个微机的计算能力团结了起来,可以完胜同等价格的中小型机器。在实际生产过程中发现,80%的业务场景是在读数据,只有20%是在写数据,而写数据会导致锁表,由于是单点数据库,会产生因为20%的写数据操作导致大量读数据操作只能等待的情况,这个就是单点数据库带来的性能瓶颈。程序员们决定使用主从结构的数据库集群,如下图所示
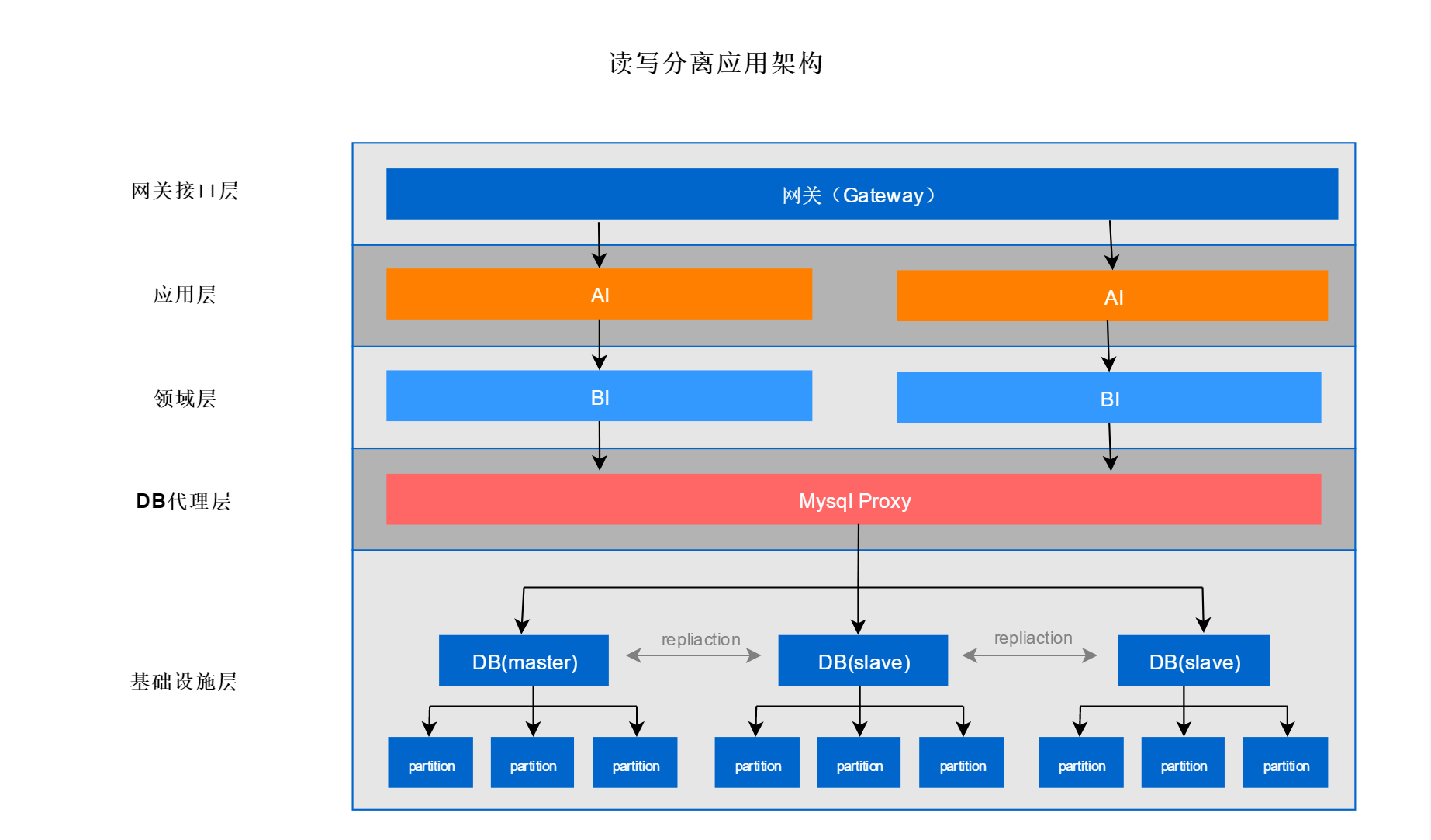
其中大部分读操作可以直接访问从库,写操作只访问主库,从而减轻主库的压力。所有从库的数据需要实时从主库同步,这种架构下master只有一个,这样会产生另外一个问题,就是master库的单点问题,master宕机后整个系统就瘫痪了,解决这个问题的方式有两种
- DB集群通过Paxos一致性算法,当主库宕机时,在从库中选举一个DB作为新的主库,实现起来成本较高,需要引入新的中间件如zookeeper。
- 双机热备,主机和从机通过TCP/IP网络连接,正常情况下主机处于工作状态,从机处于监视状态,一旦从机发现主机异常,从机将会在很短的时间之内代替主机,完全实现主机的功能。
下面是spring boot + mybatis实现读写分离的配置实现
application.yml
spring:
datasource:
master:
jdbc-url: jdbc:mysql://192.168.102.31:3306/test
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
slave1:
jdbc-url: jdbc:mysql://192.168.102.56:3306/test
username: pig # 只读账户
password: 123456
driver-class-name: com.mysql.jdbc.Driver
slave2:
jdbc-url: jdbc:mysql://192.168.102.36:3306/test
username: pig # 只读账户
password: 123456
driver-class-name: com.mysql.jdbc.Driver多数据源配置
这里,我配置了4个数据源,1个master,2两个slave,1个路由数据源。前3个数据源都是为了生成第4个数据源,而且后续我们只用这最后一个路由数据源。
package com.cjs.example.config;
import com.cjs.example.bean.MyRoutingDataSource;
import com.cjs.example.enums.DBTypeEnum;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* 关于数据源配置,参考SpringBoot官方文档第79章《Data Access》
* 79. Data Access
* 79.1 Configure a Custom DataSource
* 79.2 Configure Two DataSources
*/
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.slave1")
public DataSource slave1DataSource() {
return DataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.slave2")
public DataSource slave2DataSource() {
return DataSourceBuilder.create().build();
}
@Bean
public DataSource myRoutingDataSource(@Qualifier("masterDataSource") DataSource masterDataSource,
@Qualifier("slave1DataSource") DataSource slave1DataSource,
@Qualifier("slave2DataSource") DataSource slave2DataSource) {
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DBTypeEnum.MASTER, masterDataSource);
targetDataSources.put(DBTypeEnum.SLAVE1, slave1DataSource);
targetDataSources.put(DBTypeEnum.SLAVE2, slave2DataSource);
MyRoutingDataSource myRoutingDataSource = new MyRoutingDataSource();
myRoutingDataSource.setDefaultTargetDataSource(masterDataSource);
myRoutingDataSource.setTargetDataSources(targetDataSources);
return myRoutingDataSource;
}
}分表分库虽然能短暂的解决系统性能问题,然而这种方式还是无法解决写瓶颈,写依旧需要主库来处理,当业务量量级再次增高时,写已经变成刻不容缓的待处理瓶
分表分库
分库分表不仅可以对相同的库进行拆分,还可以对相同的表进行拆分,对表进行拆分的方式叫做水平拆分。读写分离是把读写操作分摊到不同机器,分表分库也是实现了类似的功能,那么读写分离和分表分库的区别是什么,分写分离中主库和从库的数据是一模一样的,它只是把IO请求分摊了,数据并没有分摊。而分表分库不但分摊了请求,也分摊了数据,例如原来的一张用户表,分表分库后,会被拆成几张表分散在不同的库不同的机器存储。除此之外还可以把不同功能的表放到不同的库里,一般对应的是垂直拆分(按照业务功能进行拆分),此时一般还对应了微服务化。分库分表有垂直切分和水平切分两种。
垂直(纵向)切分
何谓垂直切分,即将表按照功能模块、关系密切程度划分出来,部署到不同的库上。例如,我们会建立定义数据库workDB、商品数据库payDB、用户数据库userDB、日志数据库logDB等,分别用于存储项目数据定义表、商品定义表、用户数据表、日志数据表等。
垂直分库
就是根据业务耦合性,将关联度低的不同表存储在不同的数据库。做法与大系统拆分为多个小系统类似,按业务分类进行独立划分。与”微服务治理”的做法相似,每个微服务使用单独的一个数据库。
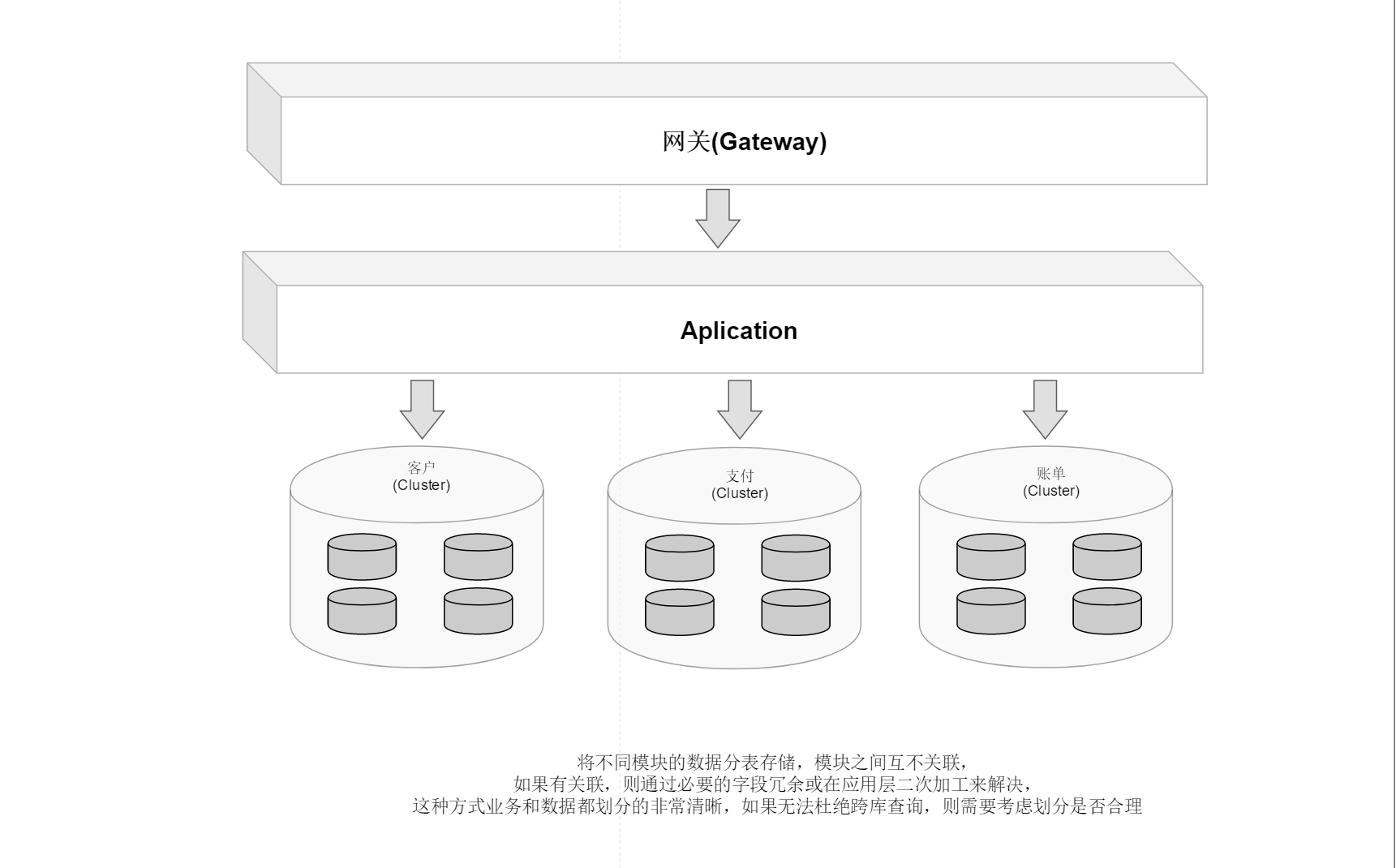
垂直分表
基于数据库中的列进行,某个表字段较多,可以新建一张扩展表,将不经常用或字段长度较大的字段拆分出去到扩展表中。在字段很多的情况下(例如一个大表有100多个字段),通过”大表拆小表”,更便于开发与维护,也能避免跨页问题,MySQL底层是通过数据页存储的,一条记录占用空间过大会导致跨页,造成额外的性能开销。另外数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
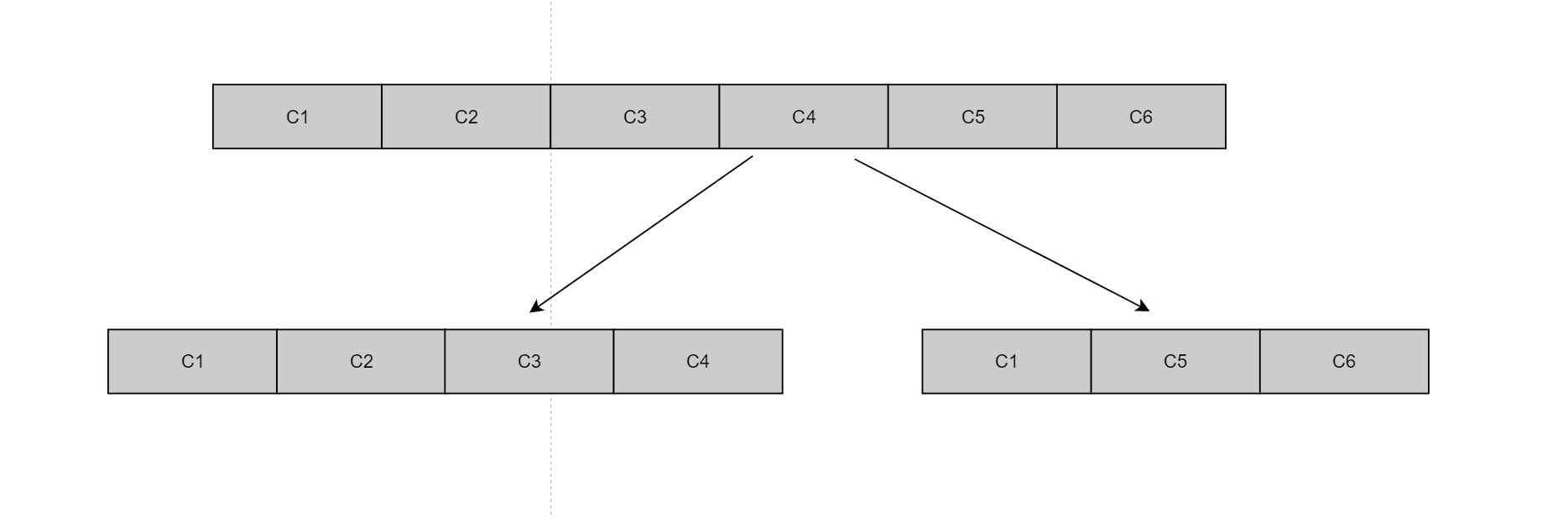
水平(横向)切分
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平切分了。水平切分分为库内分表和分库分表,是根据表内数据内在的逻辑关系,将同一个表按不同的条件分散到多个数据库或多个表中,每个表中只包含一部分数据,从而使得单个表的数据量变小,达到分布式的效果。
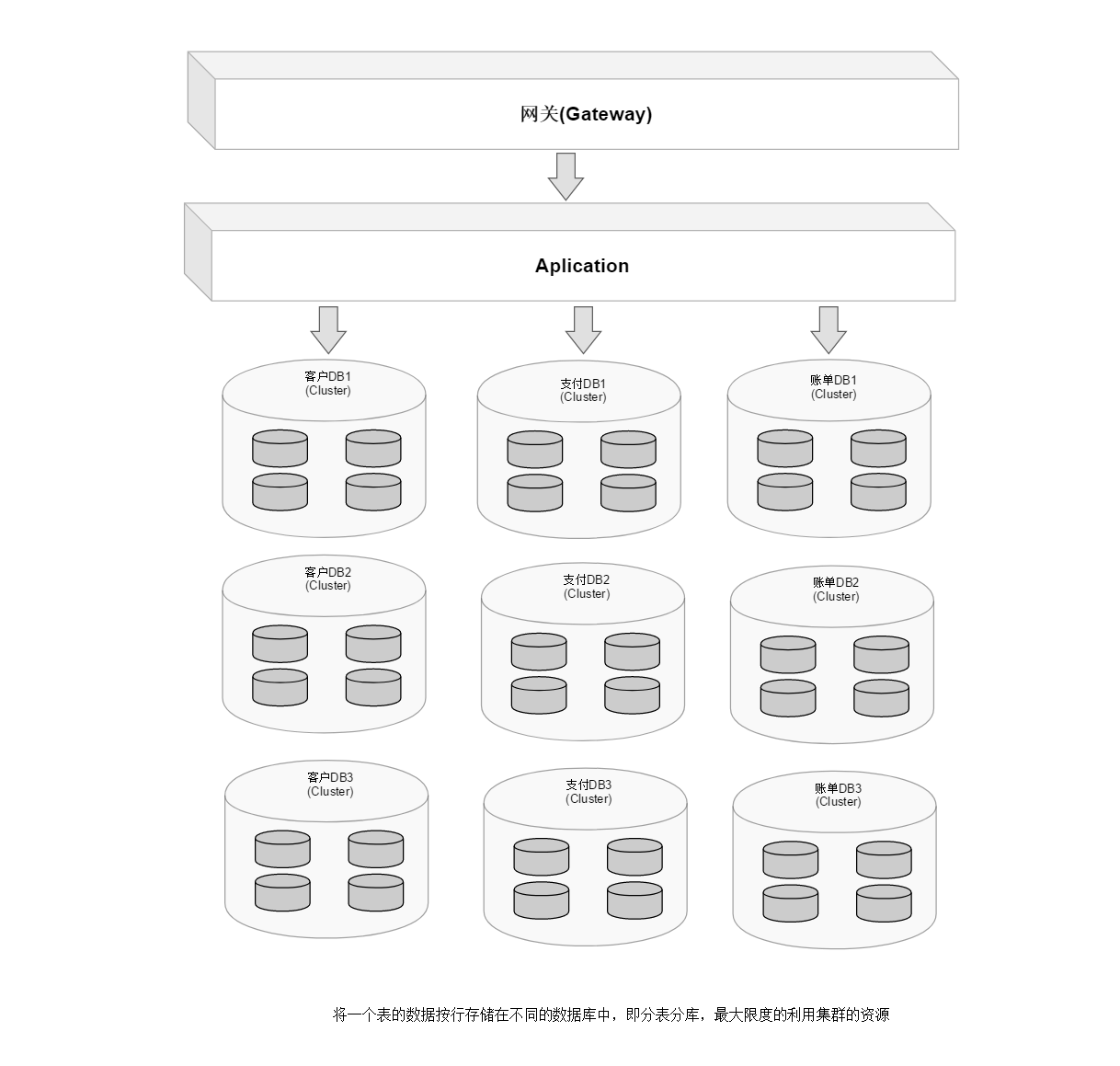
分表分库的缺点
- 事务问题:在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
- 关联查询:在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
单元化
单元化是蚂蚁金服的做法,蚂蚁支付宝是国内最大的支付工具,其在双 11 等活动日当日的支付 TPS 可达几十万级,未来这个数字可能会更大。看了单元化的方式时,我觉得跟微服务化有异曲同工之妙,分表分库极致基本能支撑 TPS 在万级甚至更高的访问量了。然而随着相同应用扩展的越多,每个数据库的链接数也巨量增长,这让数据库本身的资源成为了瓶颈。这个问题产生的本质是全量数据无差别的分享了所有的应用资源,比如 A 用户的请求在负载均衡的分配下可能分配到任意一个应用服务器上,因而所有应用全部都要链接 A 用户所在的分库,数据库连接数就变成笛卡尔乘积了。可能有人会疑惑都分表分库了,不同的用户请求的库肯定是不一样的,请求和数据都被分摊到不同服务器上了,为什么说请求是无差别的分享了应用资源呢?对于服务层到DB层的请求来说,数据确实已经被隔离了,当服务请求特定的数据时,肯定会请求到特定的服务器。
举个例子:假如用户A的数据全都保存在DB-A库中,当用户A请求服务A时,服务A必然请求DB-A,当用户A请求服务B时,服务B必然也请求DB-A。如果用户B的数据保存在DB-B中,这时也会产生同样的结果,这样一来对于应用来说,数据库连接数就变成笛卡尔乘积了,原因就是因为DB共享了所有应用资源,这种场景下性能瓶颈就不在IO了,而在于DB的可用连接数,每个DB的连接数是有限的。如下图,按这种方式产生了很多不必要的连接,试想一下如果查询用户A的请求始终到服务A上,那么服务B请求DB-A的连接就可用不需要了,而服务A可用复用原来的连接,这样就节省了一部分DB连接,下图中可以想象当应用继续增加时请求连接是怎么样的场景了
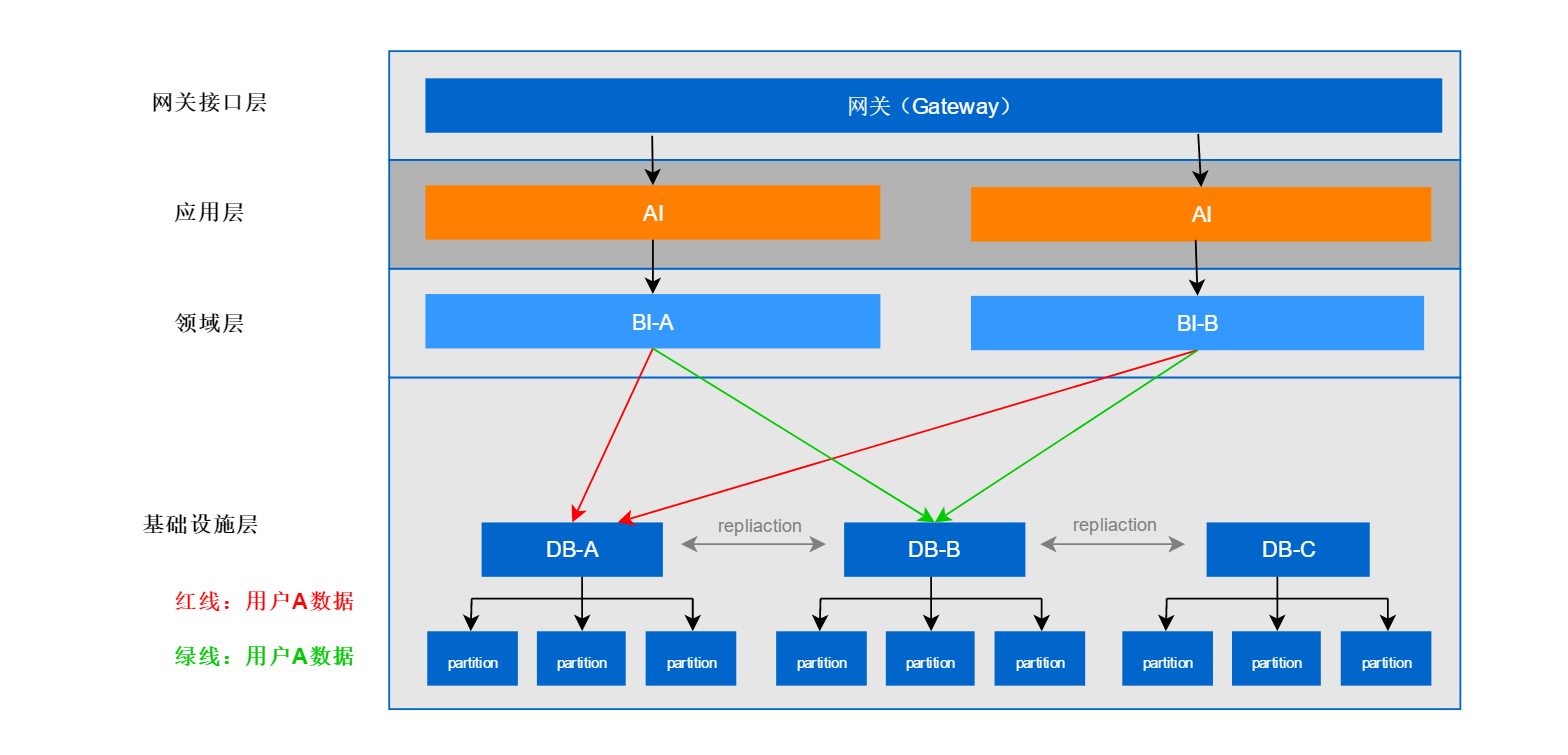
本质点说,这种模式的资源隔离性还不够彻底。要解决这个问题,就需要把识别用户分库的逻辑往上层移动,从数据库层移动到路由网关层。这样一来,从应用服务器 a 进来的来自 A 客户的所有请求必然落库到 DB-A,因此 a 也不用链接其他的数据库实例了,这样一个单元化的雏形就诞生了。(我理解这里和微服务非常相似了,只不过微服务是按照业务功能划分服务边界,而单元化则是按的DB中的数据划分请求边界)。思考一下,应用间其实也存在交互(比如 A 转账给 B),也就意味着,应用不需要链接其他的数据库了,但是还需要链接其他应用。如果是常见的 RPC 框架如 Dubbo 等,使用的是 TCP/IP 协议,那么等同于把之前与数据库建立的链接,换成与其应用之间的链接了。而服务内部之间的连接可用使用更高效的TCP连接,而非HTTP。为啥这样就消除瓶颈了呢?首先由于合理的设计,应用间的数据交互并不巨量,其次应用间的交互可以共享 TCP 链接,比如 A->B 之间的 Socket 链接可以被 A 中的多个线程复用。而一般的数据库如 MySQL 则不行,所以 MySQL 才需要数据库链接池。
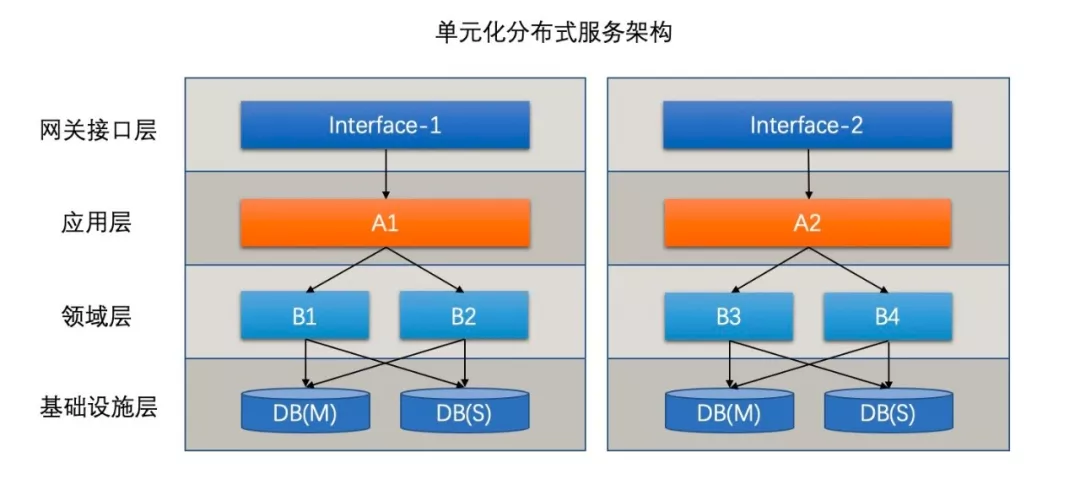
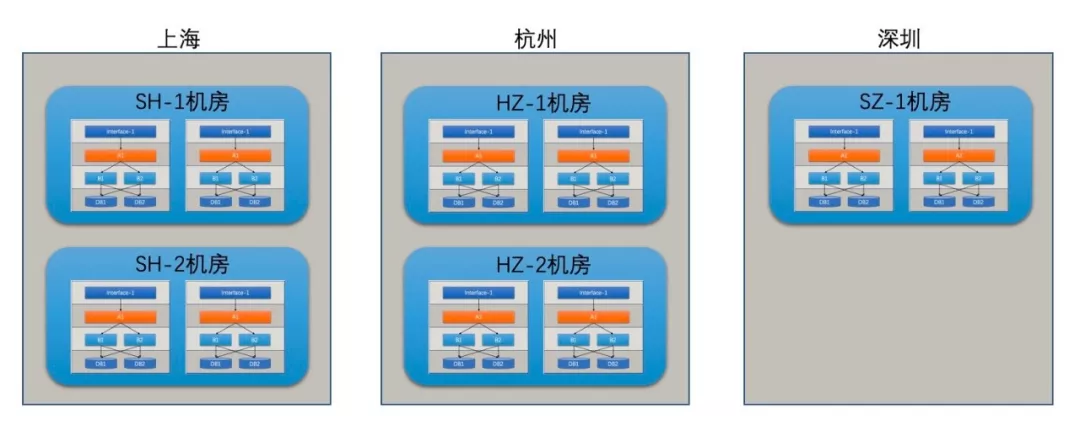
如上图所示,但我们把整套系统打包为单元化时,每一类的数据从进单元开始就注定在这个单元被消化,由于这种彻底的隔离性,整个单元可以轻松的部署到任意机房而依然能保证逻辑上的统一。下图为一个三地五机房的部署方式:
写在最后
Mysql单表性能在千万级别,千万以前可用随便玩,超过千万性能就会变得很差,我们知道Mysql如果走索引的话是根据B+树或其变种去搜索数据的,增删查操作的时间复杂度应该根据B+树的时间复杂度一样,大致呈线性增加。那么单表数据量达到千万上亿的时候应该不会比百万级别时差很多才对,为什么Mysql单表到千万级别后,性能会呈现雪崩式的下降呢。作为商业数据库的Oracle也好不到哪里去,在单表上亿后,会感觉到查询数据明显下降。推测两点可能的原因
- 缓存命中率问题:存储引擎不是每次查询都有走磁盘io,中间有内存的缓存区。如果没有命中缓存,走磁盘io会非常慢。假设你硬件物理内存没变,数据量超过内存的时候,缓存命中率会不断降低。缓存未命中情况下的时间花费估计也不可能是对数时间复杂度问题。
- 可能与并发数有关系:负载超过处理能力或者需要加锁的时候,任务可能要排队等待,一些涉及到dml的操作会导致锁表,由于数据量巨大,操作时间很长,导致socket超时,甚至线程假死等情况,而锁表操作却没有得到释放。于是越堵越慢,越慢越堵,可能就不是对数时间复杂度了



