V8引擎是前端开发工程师进阶的必经之路,它是JS的解释器。对于CPU硬件是无法直接运行高级语言的,需要把高级语言翻译成机器码,而V8引擎是专门作为JavaScript而创造的解释器。在Java中JVM也有类似的作用,但与JVM不同的是。V8引擎是把JavaScript语言直接翻译成机器码,而JVM并不是直接翻译Java语言,而是把字节码翻译成机器码。Google V8 引擎使用 C++ 代码编写,实现了 ECMAScript 规范的第五版,可以运行在所有的主流操作系统中,甚至可以运行在移动终端 ( 基于 ARM 的处理器,如 HTC G7 等 )。V8开发小组是一群程序语言专家。核心工程师Lars Bak之前研发了HotSpot,因此V8引擎的实现原理中有一部分借鉴JVM。V8 会编译 / 执行 JavaScript 代码,管理内存,负责垃圾回收,与宿主语言的交互等。V8 的垃圾回收器采用了众多技术,使得其运行效率大大提高。通过暴露宿主对象 ( 变量,函数等 ) 到 JavaScript,JavaScript 可以访问宿主环境中的对象,并在脚本中完成对宿主对象的操作。

V8引擎的历史
2006 年秋,Google 聘请 Lars Bak 为 Chrome 浏览器构建了一个新的 JavaScript 引擎,当时它仍然是一个 Google 内部秘密的项目。后来,Lars 想留在丹麦,他从硅谷搬回了丹麦的奥胡斯。但那里没有谷歌办公室,Lars和该项目最早的几个工程师开始在他的农场里工作。新的 JavaScript 引擎被命名为“V8”,隐喻肌肉车里的强大引擎[注:肌肉车装备有大马力 V8 发动机]。随着 V8 团队壮大,开发人员从他们的农场搬到了奥胡斯的现代化办公大楼,团队带着他们特有的驱动力,专注于构建地球上最快的 JavaScript 引擎。Google开始研发V8,部分的原因是Google对JavaScript引擎的执行速度不满意。JavaScript存在至少10年了。在1995年,它出现在网景(Netscape Communications)公司所研发的网页浏览器Netscape Navigator 2.0中。然而有段时间人们对于性能的要求不高,因为它只用在网页上少数的动画、交互操作或其它类似的动作上。浏览器的显示速度视网络传输速度以及渲染引擎(rendering engine)解析HTML、CSS(cascading style sheets, CSS)及其他代码的速度而定。浏览器的开发工作优先提升渲染引擎的速度,而JavaScript的处理速度不是太重要。同时出现的Java有相当大的进步,它被做得愈来愈快,以便和C++竞争。但随着Web相关技术的发展,JavaScript所要承担的工作也越来越多,早就超越了“表单验证”的范畴,例如桌面应用的软件(其中包括Office套件等),现已成为可以在浏览器中执行的软件。Google本身就推出了好几款JavaScript网络应用,其中包括它的Gmail电子邮件服务、Google Maps地图数据服务、以及Google Docs office套件。这些应用表现出的速度不仅受到服务器、网络、渲染引擎以及其他诸多因素的影响,同时也受到JavaScript本身执行速度的影响。这就更需要快速的解析和执行JavaScript脚本。V8引擎就是为解决这一问题而生,在node中也是采用该引擎来解析JavaScript。
浏览器的结构
浏览器是使用最广的软件之一,我们平时在打开浏览器输出网址回车后,浏览器做了哪些事情呢,这就涉及到浏览器的工作原理了,首先来看一下浏览器的结构,浏览器的核心是两部分:渲染引擎和JavaScript解释器(JavaScript引擎),如果细分的话,可分为8个子系统
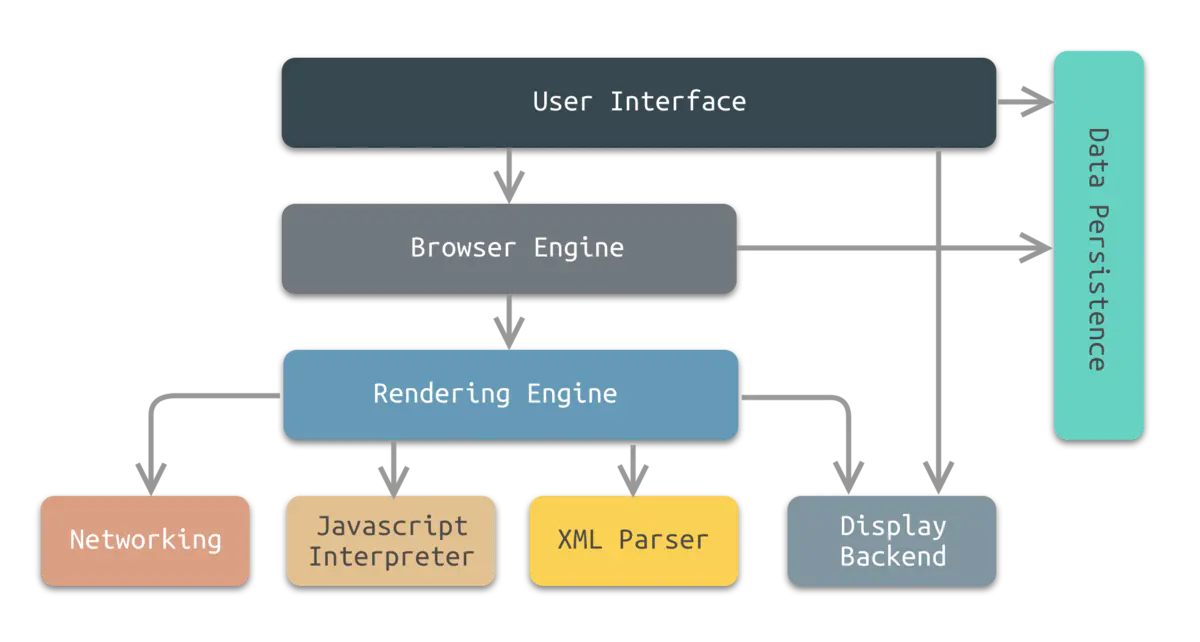
用户界面(User Interface)
用户界面主要包括工具栏、地址栏、前进/后退按钮、书签菜单、可视化页面加载进度、智能下载处理、首选项、打印等。除了浏览器主窗口显示请求的页面之外,其他显示的部分都属于用户界面。用户界面还可以与桌面环境集成,以提供浏览器会话管理或与其他桌面应用程序的通信。
浏览器引擎(Browser Engine)
浏览器引擎是一个可嵌入的组件,其为渲染引擎提供高级接口。浏览器引擎可以加载一个给定的URI,并支持诸如:前进/后退/重新加载等浏览操作。浏览器引擎提供查看浏览会话的各个方面的挂钩,例如:当前页面加载进度、JavaScript alert。浏览器引擎还允许查询/修改渲染引擎设置。
网络(Networking)
网络系统实现HTTP和FTP等文件传输协议。 网络系统可以在不同的字符集之间进行转换,为文件解析MIME媒体类型。 网络系统可以实现最近检索资源的缓存功能。
JavaScript解释器(JavaScript Interpreter)
又名JS引擎,JavaScript解释器能够解释并执行嵌入在网页中的JavaScript(又称ECMAScript)代码。 为了安全起见,浏览器引擎或渲染引擎可能会禁用某些JavaScript功能,如弹出窗口的打开。
XML解析器(XML Parser)
XML解析器可以将XML文档解析成文档对象模型(Document Object Model,DOM)树。 XML解析器是浏览器架构中复用最多的子系统之一,几乎所有的浏览器实现都利用现有的XML解析器,而不是从头开始创建自己的XML解析器。与其功能相似的HTML解析器为什么划分在渲染引擎中,后者作为独立的子系统?XML解析器对于系统来说,其功能并不是关键性的,但是从复用角度来说,XML解析器是一个通用的,可重用的组件,具有标准的,定义明确的接口。相比之下,HTML解析器通常与渲染引擎紧耦合。
Data Persistence(数据持久层)
数据持久层将与浏览会话相关联的各种数据存储在硬盘上。 这些数据可能是诸如:书签、工具栏设置等这样的高级数据,也可能是诸如:Cookie,安全证书、缓存等这样的低级数据
显示后端(Display Backend)
显示后端提供绘图和窗口原语,包括:用户界面控件集合、字体集合。
渲染引擎
渲染引擎是浏览器的核心,也可以叫做浏览器的内核(这种说法并不是很严谨)。他的功能是渲染,即在浏览器窗口中显示所请求的内容。默认情况下,渲染引擎可显示 HTML 和 XML 文档及图片。目前,常见的渲染引擎有Trident、Gecko、WebKit等。渲染引擎一开始会从网络层获取请求文档的内容(以8k分块)。解析HTML文档,并将文档中的标签转化为dom节点树,即”内容树”。同时,它也会解析外部CSS文件以及style标签中的样式数据。这些样式信息连同HTML中的”可见内容”一道,被用于构建另一棵树——”渲染树(Render树)”。渲染树由一些带有视觉属性(如颜色、大小等)的矩形组成,这些矩形将按照正确的顺序显示在频幕上。渲染树构建完毕之后,将会进入”布局”处理阶段,即为每一个节点分配一个屏幕坐标。再下一步就是绘制(painting),即遍历render树,并使用UI后端层绘制每个节点。这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。下图所示为渲染引擎工作流程中各个步骤所对应的模块,其中第1步和第2步涉及到多个模块,并且耦合程度较高。这样的设计会为了达到更好的用户体验,渲染引擎尽快将内容显示在屏幕上。
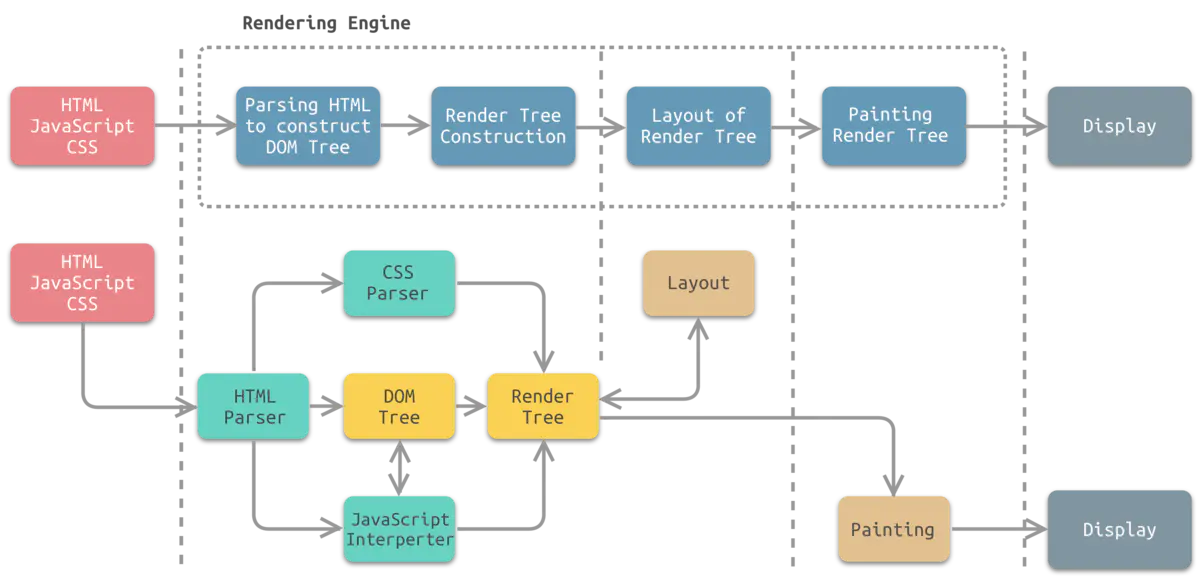
看完这图是不是让人头大,不管是HTML,CSS还是JS解释渲染。其实现原理都涉及编译原理,所以如果想再深究实现细节,就得先明白编译原理了。(大佬就是这么无情啊,一言不合就创造一门语言)回到主题,继续JS引擎吧
JS引擎
JS引擎是一个专门处理JS脚本的虚拟机,专门设计来解释和执行的 JavaScript 代码。 JS引擎会加载你的源代码,把它分解成字符串,把这些字符串转换成编译器可以理解的字节码,然后执行这些字节码。不同浏览器有不同的JS引擎,下面是一些常用浏览器的JS引擎
| 浏览器(或JS运行环境) | JavaScript引擎 |
|---|---|
| Firefox(火狐浏览器) | SpiderMonkey |
| Chorme(谷歌浏览器) | V8 |
| Safari(macOS中的浏览器) | JavaScriptCore |
| IE / Edge | Chakra |
| Node | V8 |
从性能的角度来看,V8具有4个主要特性。首先,它在执行时以称为及时(just-in-time, JIT)的编译方法,来产生机器语言。这是个普遍用来改善解释速度的方法,在Java和.NET等语言中也可以发现此方法。V8比Firefox中的SpiderMonkey JavaScript引擎,或Safari的JavaScriptCore等竞争引擎还要早的实践了这一技术。V8 JIT编译器在产生机器语言时,不会产生中间码。而在Java编译器先将原始码转换成一个以虚拟中间语言(称为字节码,bytecode)JAVA中称之为类文件 (class file)。Java编译器和字节码编译器产生字节码,而非机器语言。Java VM按顺序地在执行中解释字节码。此执行模式称为字节码解释器(bytecode interpreter)。 Firefox的SpiderMonkey具有一个内部的字节码编译器和字节解释器,将JavaScript原始码转换成它自家特色的字节代码,以便执行。V8不是将原始程序转换成中间语言,而是将抽象语法直接产生机器语言并加以执行。没有虚拟机,且因为不需要中间表示式,程序处理会更早开始了。然而,另一方面,它也丧失了虚拟机的好处,例如透过字节码解释器和混合模式等
垃圾回收
JavaScript使用垃圾回收机制来自动管理内存。垃圾回收是一把双刃剑,其好处是可以大幅简化程序的内存管理代码,降低程序员的负担,减少因长时间运转而带来的内存泄露问题。但使用了垃圾回收即意味着程序员将无法掌控内存。ECMAScript没有暴露任何垃圾回收器的接口。我们无法强迫其进行垃圾回收,更无法干预内存管理。V8的垃圾回收策略基于分代回收机制,该机制又基于 世代假说。该假说有两个特点:
- 大部分新生对象倾向于早死;
- 不死的对象,会活得更久。
基于这个理论,现代垃圾回收算法根据对象的存活时间将内存进行了分代,并对不同分代的内存采用不同的高效算法进行垃圾回收。和Java的JVM垃圾回收相似度非常高,JVM同样是采用分代垃圾回收。
V8的内存限制
Node与其他语言不同的一个地方,就是其限制了JavaScript所能使用的内存(64位为1.4GB,32位为0.7GB),这也就意味着将无法直接操作一些大内存对象。这很令人匪夷所思,因为很少有其他语言会限制内存的使用。V8之所以限制了内存的大小,表面上的原因是V8最初是作为浏览器的JavaScript引擎而设计,不太可能遇到大量内存的场景,而深层次的原因则是由于V8的垃圾回收机制的限制。由于V8需要保证JavaScript应用逻辑与垃圾回收器所看到的不一样,V8在执行垃圾回收时会阻塞JavaScript应用逻辑,直到垃圾回收结束再重新执行JavaScript应用逻辑,这种行为被称为“全停顿”(stop-the-world)。若V8的堆内存为1.5GB,V8做一次小的垃圾回收需要50ms以上,做一次非增量式的垃圾回收甚至要1秒以上。这样浏览器将在1s内失去对用户的响应,造成假死现象。如果有动画效果的话,动画的展现也将显著受到影响。当然这个限制是可以打开的,类似于JVM,我们通过在启动node时可以传递–max-old-space-size或–max-new-space-size来调整内存限制的大小,前者确定老生代的大小,单位为MB,后者确定新生代的大小,单位为KB。这些配置只在V8初始化时生效,一旦生效不能再改变
回收算法
在V8中,将内存分为了新生代(new space)和老生代(old space)。它们特点如下:
- 新生代:对象的存活时间较短。新生对象或只经过一次垃圾回收的对象。
- 老生代:对象存活时间较长。经历过一次或多次垃圾回收的对象。
由于新生代和老生代特点不同,新生代对象基本朝生夕死。针对这两个区域,产生不同的算法回收垃圾对象。
Scavenge 算法
新生代中的对象主要通过 Scavenge 算法进行垃圾回收。Scavenge 的具体实现,主要采用了Cheney算法。Cheney算法采用复制的方式进行垃圾回收。它将堆内存一分为二,每一部分空间称为 semispace。这两个空间,只有一个空间处于使用中,另一个则处于闲置。使用中的 semispace 称为 「From 空间」,闲置的 semispace 称为 「To 空间」。Scavenge 算法的缺点是,它的算法机制决定了只能利用一半的内存空间。但是新生代中的对象生存周期短、存活对象少,进行对象复制的成本不是很高,因而非常适合这种场景。学过Java虚拟机的对此算法应该很熟悉,这个算法主要是为了避免STW时间太长(Stop The World )。
Mark-Sweep
老生代的算法主要有两个Mark-Sweep和Mark-Compact,是标记清除的意思。它主要分为标记和清除两个阶段。
- 标记阶段,它将遍历堆中所有对象,并对存活的对象进行标记;
- 清除阶段,对未标记对象的空间进行回收。
与 Scavenge 算法不同,Mark-Sweep 不会对内存一分为二,因此不会浪费空间。但是,经历过一次 Mark-Sweep 之后,内存的空间将会变得不连续,这样会对后续内存分配造成问题。比如,当需要分配一个比较大的对象时,没有任何一个碎片内支持分配,这将提前触发一次垃圾回收,尽管这次垃圾回收是没有必要的。
Mark-Compact
为了解决内存碎片的问题,提高对内存的利用,引入了 Mark-Compact (标记整理)算法。Mark-Compact 是在 Mark-Sweep 算法上进行了改进,标记阶段与Mark-Sweep相同,但是对未标记的对象处理方式不同。与Mark-Sweep是对未标记的对象立即进行回收,Mark-Compact则是将存活的对象移动到一边,然后再清理端边界外的内存。由于Mark-Compact需要移动对象,所以执行速度上,比Mark-Sweep要慢。所以,V8主要使用Mark-Sweep算法,然后在当空间内存分配不足时,采用Mark-Compact算法。



