在公司做新一个项目的开发时,又接触到了RPC。虽然我以前做过WebService的相关开发,不过那时只是照葫芦画瓢的实现功能开发,没有深入研究它的实现原理。RPC的概念由来已久,最早是由互联网大师 Jon Postel在1974年冬发表了RFC674:“Procedure Call Protocol Documents,Version 2”,尝试定义一种在包含70个节点的网络中共享资源的通用方法。在大师一生中编辑过的无数个RFC文档中,674属于并不突出的一个,但却拉开了RPC的序幕。在随后80年代Bruce Jay Nelson在他的论文“Implementing Remote Procedure Calls” 正式提出RPC 这个概念术语,并定义了RPC的调用标准。后面所有RPC框架,都是按照这个标准模式来的。RPC是Remote Procedure Call的缩写,即远程过程调用。

什么是RPC
首先要纠正一个观点,RPC是一种技术思想或者编程模型而不是一种技术的具体实现。也就是说RPC只是一种理论模型,它是一种进程间通信方式。允许像调用本地服务一样调用远程服务,它的具体实现方式可以不同,例如Spring的 HTTP Invoker,Facebook的 Thrift二进制私有协议通信。,在Nelson 的论文中提到了RPC应具备的特性
- 简单:RPC 概念的语义十分清晰和简单,这样建立分布式计算就更容易。
- 高效:过程调用看起来十分简单而且高效。
- 通用:在单机计算中过程往往是不同算法和APl,跨进程调用最重要的是通用的通信机制。
RPC框架的目标就是让远程过程(服务)调用更加简单、透明,RPC框架负责屏蔽底层的传输方式(TCP或者UDP)、序列化方式( XML/JSON/二进制)和通信细节。框架使用者只需要了解谁在什么位置提供了什么样的远程服务接口即可,开发者不需要关心底层通信细节和调用过程。
为什么使用RPC
其实这是应用开发到一定的阶段的强烈需求驱动的。
- 如果我们开发简单的单一应用,逻辑简单、用户不多、流量不大,那我们用不着,这个时候的服务一般为单体服务;
- 当我们的系统访问量增大、业务增多时,我们会发现一台单机运行此系统已经无法承受。此时,我们可以将业务拆分成几个互不关联的应用,分别部署在各自机器上,以划清逻辑并减小压力。此时,我们也可以不需要RPC,因为应用之间是互不关联的
- 当我们的业务越来越多、应用也越来越多时,自然的,我们会发现有些功能已经不能简单划分开来或者划分不出来。此时,可以将公共业务逻辑抽离出来,将之组成独立的服务Service应用 。而原有的、新增的应用都可以与那些独立的Service应用 交互,以此来完成完整的业务功能。所以此时,我们急需一种高效的应用程序之间的通讯手段来完成这种需求,所以你看,RPC大显身手的时候来了!
其实三描述的场景也是服务化 、微服务 和分布式系统架构 的基础场景。即RPC框架就是实现以上结构的有力方式。为什么有了HTTP,我们还需要RPC呢。如果产生这个疑问那只能说明对RPC的概念理解不透彻,因为HTTP只是一个通信协议,它跟RPC不是一个层级的概念,HTTP本身也可以作为RPC的传输层协议。但HTTP请求是非常浪费资源的。虽然其实本质上,HTTP也是走在TCP上面的,但是HTTP请求自己增加了很多自己的信息,因此会消耗带宽资源。因此很多RPC框架为了效率都是基于Socket通信。
RPC 的结构
Nelson 的论文中指出实现 RPC 的程序包括 5 个部分:1. User;2.User-Stub;3.RPCRuntime;4.Server-stub;5.Server。他们调用原理图如下:
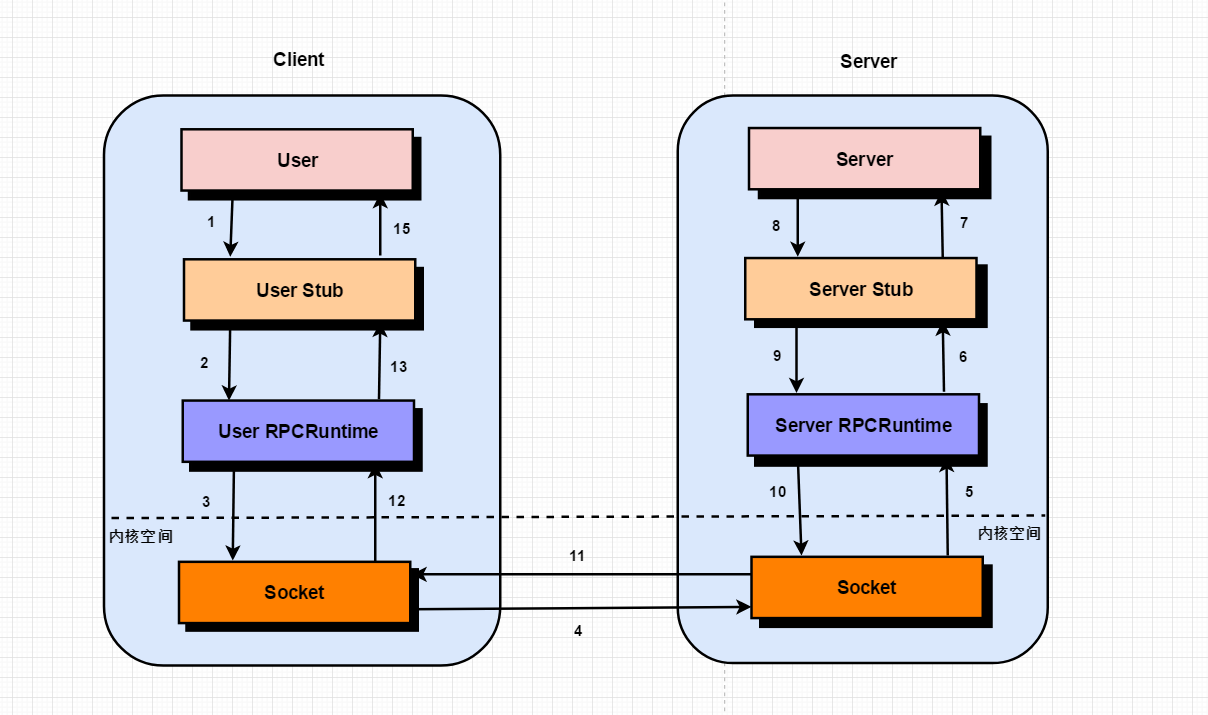
以左边的Client端为例,User就是RPC的调用方,User-Stub就是User的代理实例,其实内部是通过RPC方式来进行远程调用的代理对象。至于RPCRuntime 则是实现远程调用的工具包,比如jdk的Socket,最后通过底层网络实现实现数据的传输。这个过程中最重要的就是序列化和反序列化了,因为数据传输的数据包必须是二进制的,Java对象是没法直接进行网络传输的,你必须把Java对象序列化为二进制格式,传给Server端,Server端接收到之后,再反序列化为Java对象。
Java中常用的RPC框架
Thrift:thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++, Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, and OCaml 这些编程语言间无缝结合的、高效的服务。
Dubbo:Dubbo是一个分布式服务框架,以及SOA治理方案。其功能主要包括:高性能NIO通讯及多协议集成,服务动态寻址与路由,软负载均衡与容错,依赖分析与降级等。 Dubbo是阿里巴巴内部的SOA服务化治理方案的核心框架,Dubbo自2011年开源后,已被许多非阿里系公司使用。 是国内较早开源的服务治理的Java RPC框架,虽然在阿里巴巴内部竞争中落败于HSF,沉寂了几年,但是在国内得到了广泛的应用,目前dubbo项目又获得了支持,并且dubbo 3.0也开始开发
Spring Cloud:Spring Cloud由众多子项目组成,如Spring Cloud Config、Spring Cloud Netflix、Spring Cloud Consul 等,提供了搭建分布式系统及微服务常用的工具,如配置管理、服务发现、断路器、智能路由、微代理、控制总线、一次性token、全局锁、选主、分布式会话和集群状态等,满足了构建微服务所需的所有解决方案。Spring Cloud基于Spring Boot, 使得开发部署极其简单。
实现一个简单的RPC
要实现一个RPC不算难,这里我自己动手写了一个非常简单RPC服务,思路也很简单服务端开启一个Scoket监听,然后读取从客户端传输过来的二进制数据,转换成Java对象。通过对象中的参数调用服务端对应Service对象的方法。仔细一想,你会发现这个过程和HTTP请求大体相似,只不过HTTP不需要自己手动序列化和传输参数了,它站在了更高的地方。下面开始贴代码吧,先是客户端的代码
public class RpcClient {
private static final String ADDRESS="127.0.0.1";
private static final int PORT=8090;
public static void main(String[] args){
runObject();
}
private static void runObject(){
try {
Socket socket = new Socket(ADDRESS, PORT);
// 将请求参数序列化
RequestDto requestDto = new RequestDto(30, 20, "getArea");
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
// 将请求发给服务提供方
objectOutputStream.writeObject(requestDto);
// 将响应体反序列化
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
Object response = objectInputStream.readObject();
if(response instanceof ResponseDto)
System.out.println("-------- RPC-Response ----------"+response.toString());
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}这里实现的功能就是计算一个长方形的面积,其中RequestDto是一个普通的JavaBean,里面有wide,high和method三个属性。wide,high代表的就是长方形的长和宽。而method就是我要调用的服务端的方法。为了简单易懂,客户端调用服务端时,这里写死的IP和端口。下面是服务端的代码
public class RpcServer {
public static void main(String[] args){
run();
}
private static void run(){
ServerSocket listener = null;
try {
listener = new ServerSocket(8090);
Socket socket = listener.accept();
// 将请求反序列化
System.out.println("--------------收到请求------------------");
ObjectInputStream objectInputStream = new ObjectInputStream(socket.getInputStream());
Object object = objectInputStream.readObject();
int result = 0;
if(object instanceof RequestDto){
RequestDto requestDto = (RequestDto)object;
AreaCalculateService calculateService = new AreaCalculateService();
if ("getArea".equals(requestDto.getMethod())) {
result = calculateService.getArea(requestDto.getWide(), requestDto.getHigh());
} else {
throw new UnsupportedOperationException();
}
}
// 返回结果
ObjectOutputStream objectOutputStream = new ObjectOutputStream(socket.getOutputStream());
objectOutputStream.writeObject(new ResponseDto(200,result,"计算结果返回"));
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}服务端开启了一个端口为8090的Socket监听,收到客户端的数据后,将数据直接转成Object对象再强转为具体的业务Bean。其中AreaCalculateService是服务的Service层的类,用于计算长方形的面积。这里还有个要注意的地方,客户端和服务端序列化Bean时,要使用同一版本的类。否则会抛出如下异常:
java.io.InvalidClassException: com.lsj.dto.ResponseDto; local class incompatible: stream classdesc serialVersionUID = 7775905651334527585, local class serialVersionUID = 1637265455040962658上面的例子中我使用的是请求类是自己定义的RequestDto,响应类是ResponseDto。那么在客户端和服务端,这两个类的定义中要保证 serialVersionUID 一致,即
public class RequestDto implements Serializable {
// 这个值客户端和服务端要一致
private static final long serialVersionUID = 7775905651334527585L;
private int wide;
private int high;
private String method;
public int getWide() {
return wide;
}
public void setWide(int wide) {
this.wide = wide;
}
public int getHigh() {
return high;
}
public void setHigh(int high) {
this.high = high;
}
public String getMethod() {
return method;
}
public void setMethod(String method) {
this.method = method;
}
}
通过上面的代码我们就实现了一个简单的RPC,但是这个RPC非常简陋,只是为了理解RPC实际的调用过程。如果要用于商业环境那要优化事情还有很多很多很多。。。
RPC没那么简单
要实现一个RPC不算难,难的是实现一个高性能高可靠的RPC框架。既然是分布式了,那么一个服务可能有多个实例,你在调用时,要如何获取这些实例的地址呢?这时候就需要一个服务注册中心,比如在Dubbo里头,就可以使用Zookeeper作为注册中心,在调用时,从Zookeeper获取服务的实例列表,再从中选择一个进行调用。而在Spring Cloud中则使用Eureka作为服务的注册中心。Zookeepe和Eureka两个注册中心,其实现原理是有侧重的,这又扯出了分布式理论中著名的CAP理论了。在从注册中心获取到服务列表后,那么选哪个调用好呢?这时候就需要负载均衡了,于是你又得考虑如何实现复杂均衡,比如Dubbo就提供了好几种负载均衡策略。这还没完,总不能每次调用时都去注册中心查询实例列表吧,这样效率多低呀,于是又有了缓存,有了缓存,就要考虑缓存的更新问题。还有呢,当需要修改一个服务的配置文件时,由于这个服务有多个实例,一个一个改完再重启也太麻烦了,于是又出现了配置中心。你以为就这样结束了吗,没呢,还有这些:
- 客户端总不能每次调用完都干等着服务端返回数据吧,于是就要支持异步调用。
- 当服务端某个接口一直报错,不可用时总不能让客户端一直傻傻的请求吧,这样可能会把服务搞挂的,于是就有了熔断机制。
- 当RPC服务于服务之间调用关系越来越复杂时,怎么样快速定位到是哪个服务出现问题,导致某个请求出现异常的,于是就有了链路追踪。
- blablabla……
RPC 框架一般都有注册中心,有丰富的 监控管理;发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作。因此成熟的 RPC 框架是一个强力的支撑。系统做大了,都是分开部署,单独上线的。RPC 的核心并不在于使用什么协议。RPC 的目的是让你在本地调用 远程的方法,而对你来说这个调用是透明的,你并不知道这个调用的方法是部署哪里。现在主流的Spring Cloud和Dubbo不只是一个RPC框架,同时还是一个强大的服务治理框架。下面是总结的RPC的优缺点
| 优点 | 缺点 |
|---|---|
| 提升系统可扩展性 | 一个成熟的RPC框架开发难度大 |
| 提升系统可维护性和持续交付能力 | RPC框架调用成功率受限于网络状况(远程通信都有这问题) |
| 实现系统高可用 | 调用远程方法对初学者来说难度大 |
RPC框架的核心技术点
1.服务暴露
远程提供者需要以某种形式提供服务调用相关的信息,包括但不限于服务接口定义、数据结构、或者中间态的服务定义文件。例如Facebook的Thrift的IDL文件,Web service的WSDL文件;服务的调用者需要通过一定的途径获取远程服务调用相关的信息。目前,大部分跨语言平台 RPC 框架采用根据 IDL 定义通过 code generator 去生成 stub 代码,这种方式下实际导入的过程就是通过代码生成器在编译期完成的。代码生成的方式对跨语言平台 RPC 框架而言是必然的选择,而对于同一语言平台的 RPC 则可以通过共享接口定义来实现。这里的导入方式本质也是一种代码生成技术,只不过是在运行时生成,比静态编译期的代码生成看起来更简洁些。
Java 中还有一种比较特殊的调用就是多态,也就是一个接口可能有多个实现,那么远程调用时到底调用哪个?这个本地调用的语义是通过 jvm 提供的引用多态性隐式实现的,那么对于 RPC 来说跨进程的调用就没法隐式实现了。如果前面DemoService 接口有 2 个实现,那么在导出接口时就需要特殊标记不同的实现需要,那么远程调用时也需要传递该标记才能调用到正确的实现类,这样就解决了多态调用的语义问题。
2.远程代理对象
服务调用者用的服务实际是远程服务的本地代理。说白了就是通过动态代理来实现。Java 里至少提供了两种技术来提供动态代码生成,一种是 jdk 动态代理,另外一种是字节码生成。动态代理相比字节码生成使用起来更方便,但动态代理方式在性能上是要逊色于直接的字节码生成的,而字节码生成在代码可读性上要差很多。两者权衡起来,个人认为牺牲一些性能来获得代码可读性和可维护性显得更重要。
3.通信
RPC框架与具体的协议无关。RPC 可基于 HTTP 或 TCP 协议,Web Service 就是基于 HTTP 协议的 RPC,它具有良好的跨平台性,但其性能却不如基于 TCP 协议的 RPC。
- TCP/HTTP:众所周知,TCP 是传输层协议,HTTP 是应用层协议,而传输层较应用层更加底层,在数据传输方面,越底层越快,因此,在一般情况下,TCP 一定比 HTTP 快。
- 消息ID:RPC 的应用场景实质是一种可靠的请求应答消息流,和 HTTP 类似。因此选择长连接方式的 TCP 协议会更高效,与 HTTP 不同的是在协议层面我们定义了每个消息的唯一 id,因此可以更容易的复用连接。
- IO方式:为了支持高并发,传统的阻塞式 IO 显然不太合适,因此我们需要异步的 IO,即 NIO。Java 提供了 NIO 的解决方案,Java 7 也提供了更优秀的 NIO.2 支持。
- 多连接:既然使用长连接,那么第一个问题是到底 client 和 server 之间需要多少根连接?实际上单连接和多连接在使用上没有区别,对于数据传输量较小的应用类型,单连接基本足够。单连接和多连接最大的区别在于,每根连接都有自己私有的发送和接收缓冲区,因此大数据量传输时分散在不同的连接缓冲区会得到更好的吞吐效率。所以,如果你的数据传输量不足以让单连接的缓冲区一直处于饱和状态的话,那么使用多连接并不会产生任何明显的提升,反而会增加连接管理的开销。
- 心跳:连接是由 client 端发起建立并维持。如果 client 和 server 之间是直连的,那么连接一般不会中断(当然物理链路故障除外)。如果 client 和 server 连接经过一些负载中转设备,有可能连接一段时间不活跃时会被这些中间设备中断。为了保持连接有必要定时为每个连接发送心跳数据以维持连接不中断。心跳消息是 RPC 框架库使用的内部消息,在前文协议头结构中也有一个专门的心跳位,就是用来标记心跳消息的,它对业务应用透明。
4.序列化
两方面会直接影响 RPC 的性能,一是传输方式,二是序列化。RPC通信毕竟是远程通信,需要将对象转化成二进制流进行传输。不同的RPC框架应用的场景不同,在序列化上也会采取不同的技术。 就序列化而言,Java 提供了默认的序列化方式,但在高并发的情况下,这种方式将会带来一些性能上的瓶颈,于是市面上出现了一系列优秀的序列化框架,比如:Protobuf、Kryo、Hessian、Jackson 等,它们可以取代 Java 默认的序列化,从而提供更高效的性能。编码内容:出于效率考虑,编码的信息越少越好(传输数据少),编码的规则越简单越好(执行效率高)。
RPC vs Restful
其实这两者并不是一个维度的概念,总得来说RPC涉及的维度更广。如果硬要比较,那么可以从RPC风格的url和Restful风格的url上进行比较。比如你提供一个查询订单的接口,用RPC风格和Restful风格的区别如下表格
| RPC | Restful |
|---|---|
| GET /api/queryOrder | GET /api/queryOrder |
| GET /api/addOrder | POST /api/addOrder |
| GET /api/updateOrder | PUT /api/updateOrder |
| GET /api/deleteOrder | DELETE /api/deleteOrder |
RPC是面向过程,Restful是面向资源,并且使用了Http动词。从这个维度上看,Restful风格的url在表述的精简性、可读性上都要更好。所以REST 通过 URI 暴露资源时,会强调不要在 URI 中出现动词。



