Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。 是 加州大学伯克利分校的AMP实验室所开发的类似Hadoop MapReduce的通用并行框架 。拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。 Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。 尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等 。本文主要记录使用CentOS搭建Spark集群。

1 . 准备
1.准备三台Centos虚拟机,信息如下
| ip | OS | 说明 |
|---|---|---|
| 192.168.31.135 | CentOS 7 | Master |
| 192.168.31.136 | CentOS 7 | Worker |
| 192.168.31.137 | CentOS 7 | Worker |
2 . Java,去Oracle下载,注意Hadoop所要求的JAVA版本(java环境配置可参考之前zookeper集群搭建博客,这里不赘述)
3 . Hadoop,参考上一篇Hadoop集群搭建博文
4 . Scala ,去官网下载。下载地址:scala官网
5 . Spark,去官网下载。下载地址:
2 . 安装scala
进入官网来到下载页面
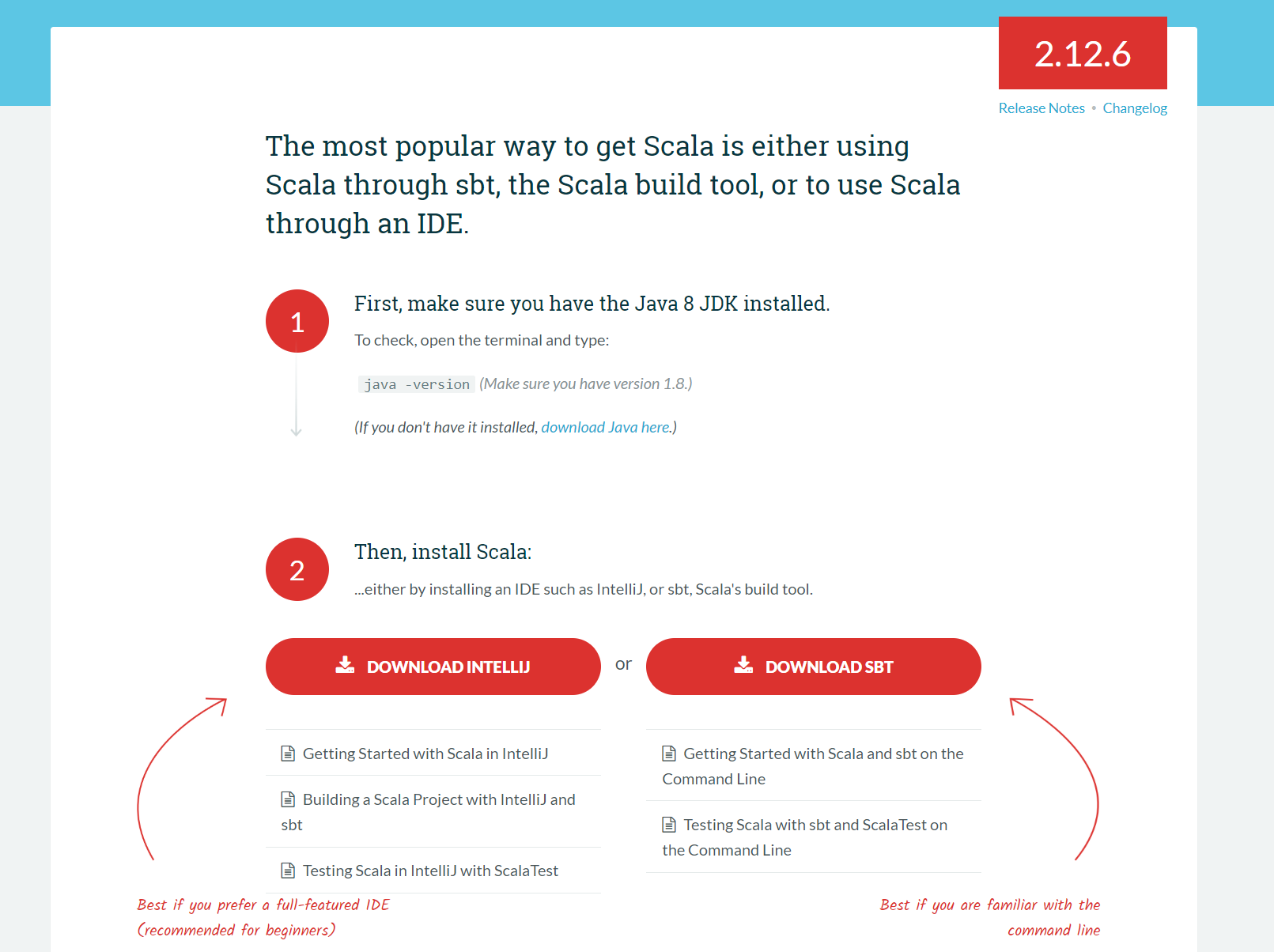
注意scala是运行于java虚拟机之上的,因此安装scala之前必须先配置好java环境。同时下载时注意对java的版本要求,例如上图中可得scala.2.12.6版本必须要求 java 8以上的版本。到此页面后拉至底部
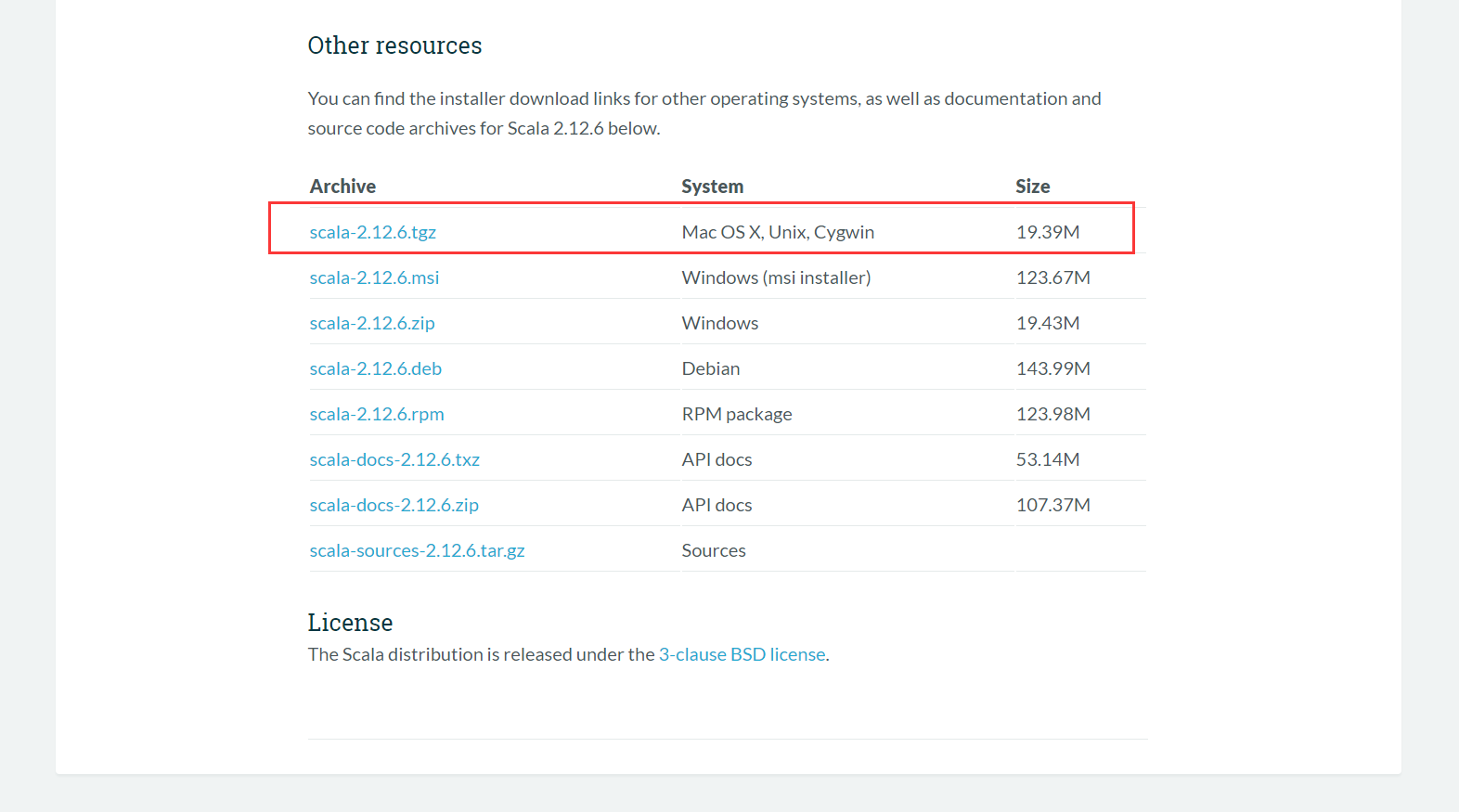
我们需要的是Linux版本,所以选择第一个支持Unix系统的下载即可。在服务器创建好文件夹
[root@centos1 ~]# cd /user
[root@centos1 user]# ll
drwxr-xr-x. 6 root root 59 8月 8 22:54 hadoop
drwxr-xr-x. 3 root root 25 4月 12 08:00 java
drwxr-xr-x. 3 root root 26 8月 7 22:21 scala
drwxr-xr-x. 3 root root 39 8月 10 23:15 spark
drwxr-xr-x. 5 root root 60 4月 12 20:50 zookeeper将压缩包上传至 /user/scala目录下,使用解压命令解压。待解压完成后需要配置环境变量,使用如下命令编辑系统配置文件
vi /etc/profile在最后加入scala的环境变量
export SCALA_HOME=/user/scala/scala-2.12.6
export PATH=$PATH:$SCALA_HOME/bin配置完成后,使用下面的命令使配置生效
source /etc/profile然后能通过命令查看的scala版本,能进入scala shell表示配置成功
[root@centos1 user]# scala -version
Scala code runner version 2.12.6 -- Copyright 2002-2018, LAMP/EPFL and Lightbend, Inc.
[root@centos1 user]# scala
Welcome to Scala 2.12.6 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_45).
Type in expressions for evaluation. Or try :help.
scala> 3 . 下载Spark
进入官网来到下载页面
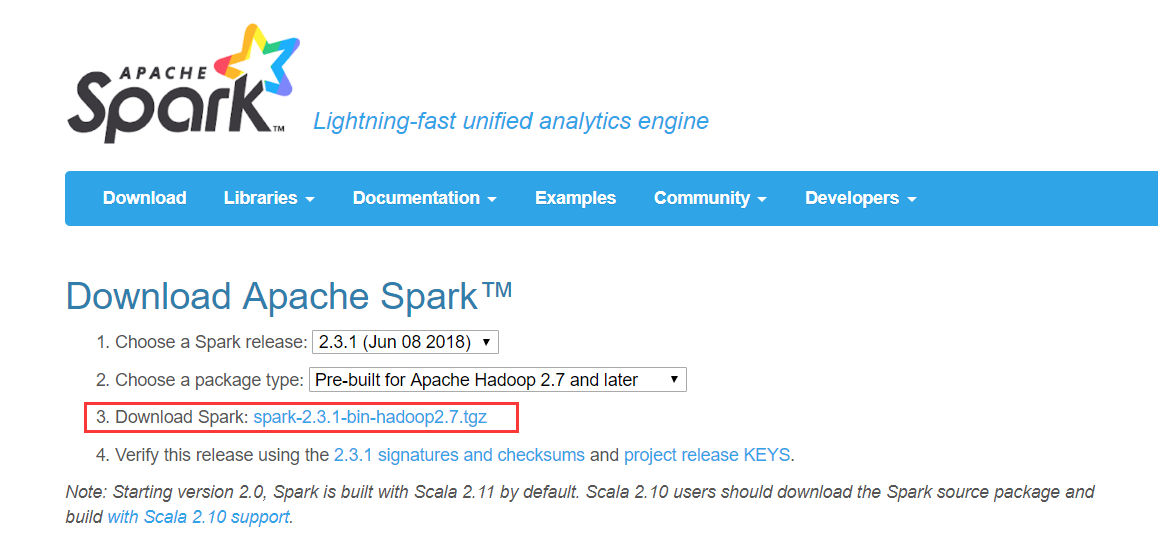
注意Spark依赖Hadoop,在选择Spark版本时,要注意它对Hadoop的版本要求。例如上图中Spark-2.3.1对Hadoop的版本要求是2.7以上。选择完合适的版本后即可下载压缩包。下载完成把压缩包上传至服务器目录解压。
tar zxvf spark-2.3.1-bin-hadoop2.7.tgz4 . 配置环境变量
编辑系统配置文件
vi /etc/profile在底部加入spark的安装目录,如下
export SPARK_HOME=/user/spark/spark-2.3.1-bin-hadoop2.7
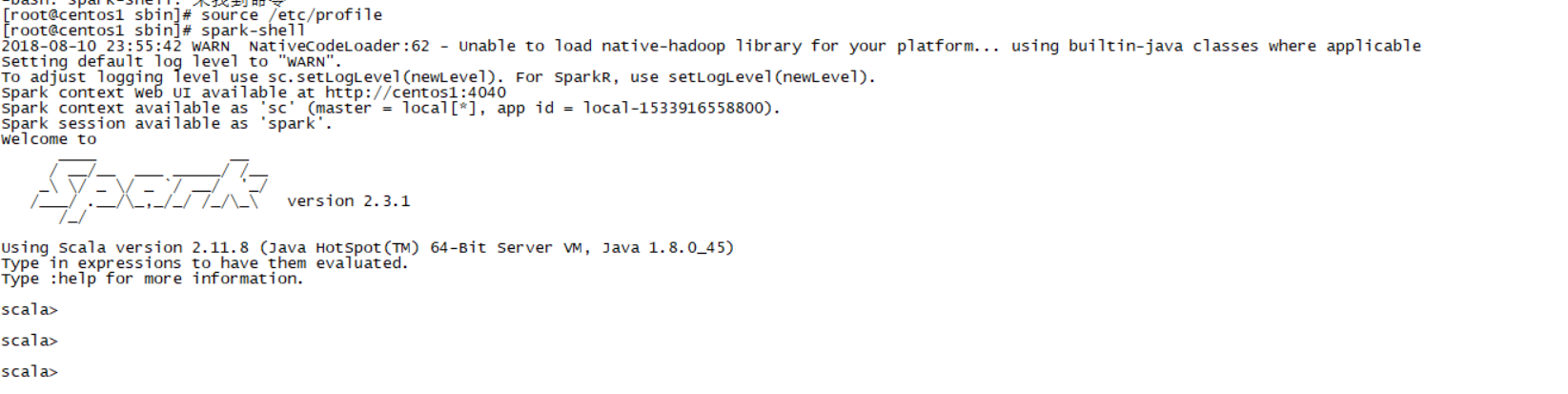
export PATH=$PATH:$SPARK_HOME/bin保存退出后使用source命令使配置生效,同时通过spark-shell查看是否配置成功。如果出现如下界面表示已配置成功
5 . 配置Spark环境
进入spark安装目录,编辑spark-env.sh文件。没有该文件则新建一份
[root@node1 ~]# cd /user/spark/spark-2.3.1-bin-hadoop2.7/conf
[root@node1 ~]# cp spark-env.sh.template spark-env.sh
[root@node1 ~]# vim spark-env.sh
export JAVA_HOME=/user/java/jdk1.8.0_45
export SCALA_HOME=/user/scala/scala-2.12.6
export HADOOP_HOME=/user/hadoop/hadoop-2.8.4
export HADOOP_CONF_DIR=/user/hadoop/hadoop-2.8.4/etc/hadoop
export SPARK_MASTER_IP=192.168.31.135
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
属性解释
| 属性名 | 说明 |
|---|---|
| JAVA_HOME | Java安装目录 |
| SCALA_HOME | Scala安装目录 |
| HADOOP_HOME | hadoop安装目录 |
| HADOOP_CONF_DIR | hadoop集群的配置文件的目录 |
| SPARK_MASTER_IP | spark集群的Master节点的ip地址 |
| SPARK_WORKER_MEMORY | 每个worker节点能够最大分配给exectors的内存大小 |
| SPARK_WORKER_CORES | 每个worker节点所占有的CPU核数目 |
| SPARK_WORKER_INSTANCES | 每台机器上开启的worker节点的数目 |
配置slaves文件,在文件底部加入work节点的Ip吗,内容如下
# A Spark Worker will be started on each of the machines listed below.
# localhost
192.168.31.136
192.168.31.137上述SCALA_HOME,SPARK_HOME,spark-env.sh,slaves文件的配置,可复制一份发送给所有Worker节点。不需更改,与Master节点保持完全一致。
6 . 启动Spark
先启动Hadoop,进入 /user/hadoop/hadoop-2.8.4/sbin 目录执行 start-all.sh 脚本

再启动Spark,进入 /user/spark/spark/spark-2.3.1-bin-hadoop2.7/sbin 目录执行 start-all.sh 脚本

spark已经成功启动完成,可通过jps命令查看状态
[root@centos1 sbin]# jps
1632 ResourceManager
1321 NameNode
1916 Master
1996 Jps可看到有Master进程,同时可访问Web UI网址:http://192.168.31.135:8080/
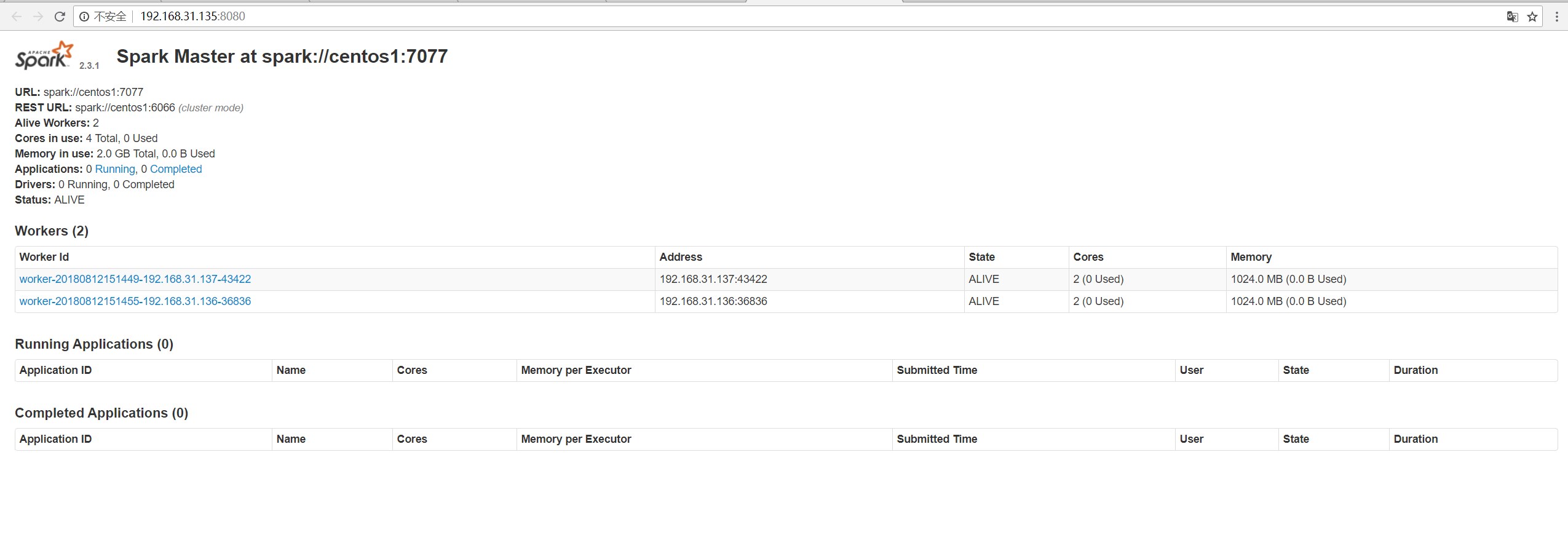
至此Spark集群搭建已经全部完成,下篇博客,将使用官方的单词计数例子,在自己搭建的集群上跑一跑



