Hadoop是一个由Apache基金会所开发的分布式系统基础架构。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上 。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。 通俗的理解就是我们计算的数据量超过了单机处理的能力,于是使用多台机器并行处理计算数据,但并行处理数据会存在各种问题,例如怎么给每个节点分派任务,怎么使各个节点算力达到均衡,在部分节点任务失败时如何恢复。这些便Hadoop帮我们解决的问题,简而言之,Hadoop是一个计算框架,并行处理计算模型。本文主要记录使用虚拟机搭建Hadoop集群过程。Hadoop有几种部署模式,分别是本地模式,伪分布式模式,完全分布式。其中本地模式和伪分布式模式都是在本地运行,其算力使用的是本机资源,并不是真正的并行计算,完全作体验之用,且过程也相对简单,不做介绍。本文记录的是完全分布式搭建过程。

1 . 准备工作
1.准备三台Centos虚拟机,信息如下
| ip | OS | 说明 |
|---|---|---|
| 192.168.31.135 | CentOS 7 | nameNode |
| 192.168.31.136 | CentOS 7 | dataNode |
| 192.168.31.137 | CentOS 7 | dataNode |
2 . JAVA,去Oracle下载,注意Hadoop所要求的JAVA版本(java环境配置可参考之前zookeper集群搭建博客,这里不赘述)
3 . Hadoop,一般YARN被集成在这里面
2 . 下载Hadoop
进入hadoop官网下载tar包,下载地址:Hadoop官网
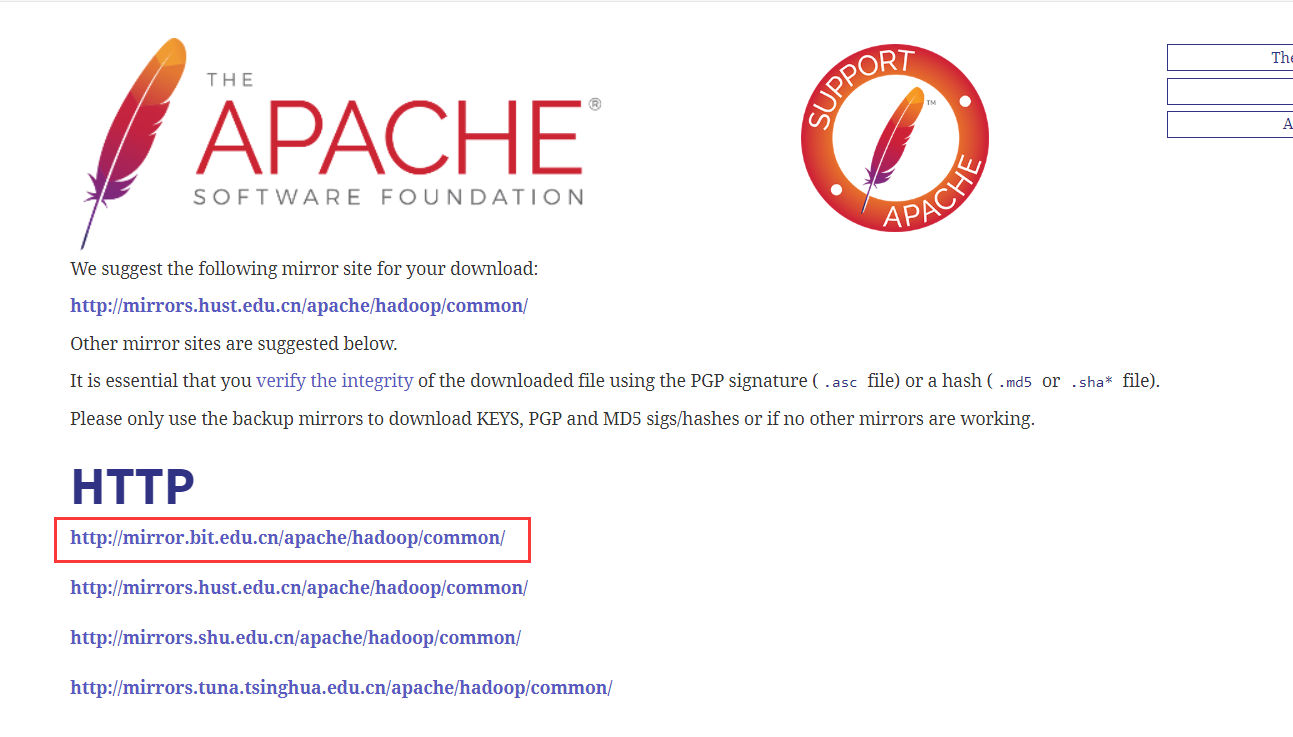
如图,选择http下载
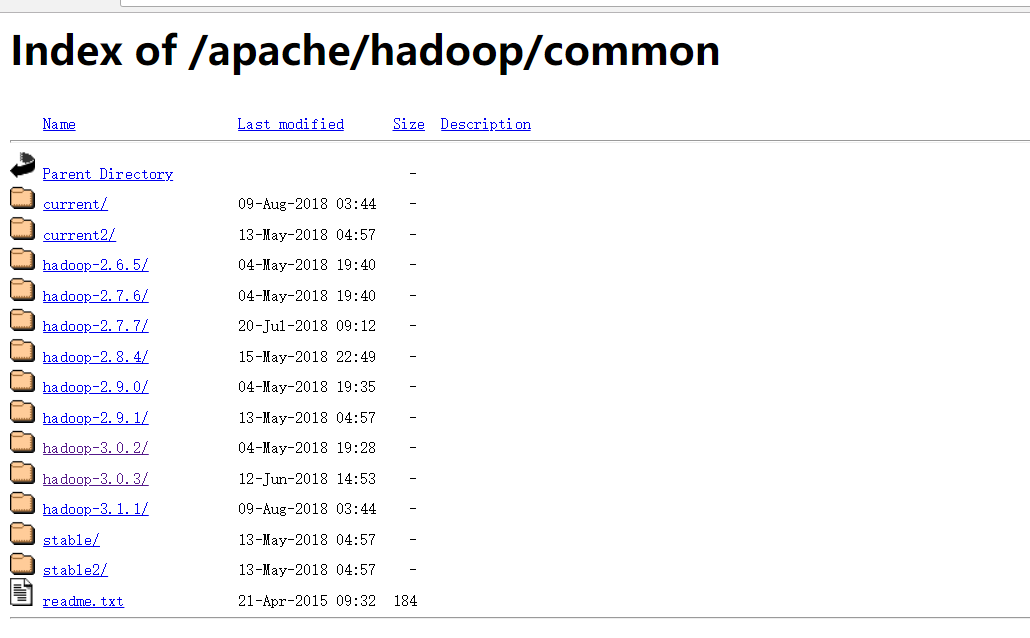
这里有很多hadoop的版本,选择一个下载即可。
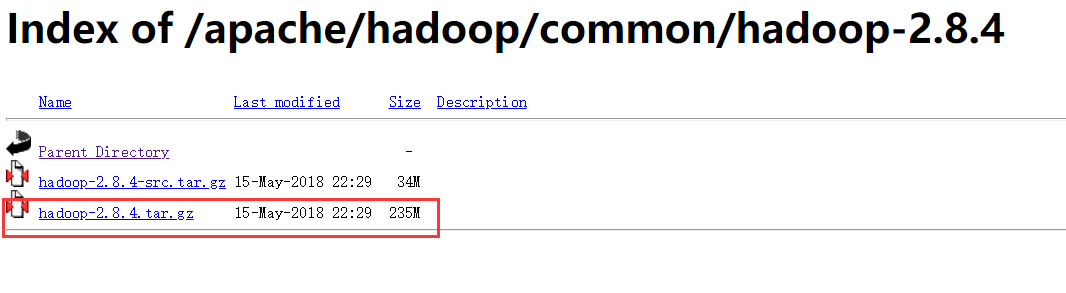
选择tar.gz包下载
3 . 解压&环境变量配置
首先在主节点上创建比要的文件夹
mkdir /user/hadoop
mkdir /user/hadoop/tmp
mkdir /user/hadoop/var
mkdir /user/hadoop/dfs
mkdir /user/hadoop/dfs/name
mkdir /user/hadoop/dfs/data将下载好的tar包上传到 /user/hadoop 目录,并执行解压命令
[root@centos1 hadoop]# tar zxvf hadoop-2.8.4.tar.gz待解压完成后,执行下面命令配置环境变量
[root@centos1 hadoop]# vi /etc/profile在底部加入以下配置
#hadoop
export HADOOP_HOME=/user/hadoop/hadoop-2.8.4
export PATH=$PATH:$HADOOP_HOME/bin保存后,执行以下命令使修改生效
[root@centos1 hadoop]# source /etc/profile然后执行以下命令,如果出现如下提示则说明配置成功
[root@centos1 ~]# hadoop -help
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp copy file or directories recursively
archive -archiveName NAME -p * create a hadoop archive
classpath prints the class path needed to get the
Hadoop jar and the required libraries
credential interact with credential providers
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
Most commands print help when invoked w/o parameters. 4 . Hadoop配置
进入到hadoop安装目录
[root@centos1 ~]# cd /user/hadoop/hadoop-2.8.4/etc/hadoop/一 . hadoop-env.sh
使用vi编辑
[root@centos1 hadoop]# vi hadoop-env.sh配置JAVA_HOME
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/user/java/jdk1.8.0_45
# The jsvc implementation to use. Jsvc is required to run secure datanodes
二 . yarn-env.sh
使用vi编辑
[root@centos1 hadoop]# vi yarn-env.sh配置JAVA_HOME
# some Java parameters
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
export JAVA_HOME=/user/java/jdk1.8.0_45
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi三 . slaves
使用vi编辑
[root@centos1 hadoop]# vi slaves 注释掉文件中原本的localhost,加入dataNode的节点配置。节点配置可以配置ip也可配置主机名。如果配置主机名,则需要在hosts文件中配置主机和ip的映射关系。这里我配置的是ip
#localhost
192.168.31.136
192.168.31.137四 . 配置文件介绍
在hadoop集群中,需要配置的文件主要包括四个,分别是core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml,这四个文件分别是对不同组件的配置参数,主要内容如下表所示:
| 文件名称 | 作用对象 | 配置说明 |
|---|---|---|
| core-site.xml | 集群全局参数 | 定义系统级别的参数 , 如HDFS URL的临时目录等 |
| hdfs-site.xml | HDFS参数 | 定义nameNode存放位置、文件副本的个数、文件读取权限等 |
| mapred-site.xml | Mapreduce参数 | reduce任务的默认个数、任务所能够使用内存的默认上下限等 |
| yarn-site.xml | Yarn参数 | ResourceManager,NodeManager 通信端口,web监控端口等 |
下面详细介绍各个配置文件的配置。
五 . core-site.xml
配置信息如下,其中tmp目录已经在步骤(2)中创建好,如果没有请自行创建
hadoop.tmp.dir
/user/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://192.168.31.135:9000/
属性解释
| 属性名 | 属性值 | 属性说明 |
|---|---|---|
| fs.defaultFS | hdfs://192.168.31.135:9000/ | 文件系统主机和端口,需配置nameNode的IP地址 |
| io.file.buffer.size | 4096 | 流文件的缓冲区大小,不配置则为默认值4096 |
| hadoop.tmp.dir | /user/hadoop/tmp | 临时文件夹,需提前创建好文件夹 |
六 . hdfs-site.xml
配置信息如下,其中tmp目录已经在步骤(2)中创建好,如果没有请自行创建
<configuration>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.31.135:9001</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/user/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/user/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<description>need not permissions</description>
</property>
</configuration>属性解释
| 属性名 | 属性值 | 属性说明 |
|---|---|---|
| yarn.resourcemanager.admin.address | 192.168.31.135:9001 | Hdfs对应的Http服务器地址和端口,需配置nameNode的IP地址 |
| dfs.name.dir | /user/hadoop/dfs/name | nameNode数据在本地文件系统的位置 |
| dfs.data.dir | /user/hadoop/dfs/data | dataNode 储数据块时存储在本地文件系统的位置 |
| dfs.replication | 1 | 数据块副本数量,默认为3 |
| dfs.permissions | false | 是否在HDFS中开启权限检查 |
七 . mapred-site.xml
配置信息如下,其中tmp目录已经在步骤(2)中创建好,如果没有请自行创建
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.31.135:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/user/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>属性解释
| 属性名 | 属性值 | 属性说明 |
|---|---|---|
| mapred.job.tracker | 192.168.31.135:49001 | 指定的是job.tracker的地址,没有设置这个参数的话,默认是local,即job会进行本地运行。 |
| mapreduce.framework.name | yarn | 取值local,classic或yarn其中之一,如果不是yarn,则不会使用YARN集群来实现资源的分配 |
| mapred.local.dir | /user/hadoop/var | mapred做本地计算所使用的文件夹,可以配置多块硬盘,逗号分隔 |
八 . yarn-site.xml
配置信息如下,其中tmp目录已经在步骤(2)中创建好,如果没有请自行创建
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>192.168.31.135:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.31.135:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.31.135:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.31.135:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.31.135:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>every node memery size(MB) default is 8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>属性解释
| 属性名 | 属性值 | 属性说明 |
|---|---|---|
| yarn.resourcemanager.address | 192.168.31.135:8032 | ResourceManager 提供给客户端访问的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等 |
| yarn.resourcemanager.scheduler.address | 192.168.31.135:8030 | ResourceManager提供给ApplicationMaster的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等 |
| yarn.resourcemanager.resource-tracker.address | 192.168.31.135:8031 | ResourceManager 提供给NodeManager的地址。NodeManager通过该地址向RM汇报心跳,领取任务等 |
| yarn.resourcemanager.admin.address | 192.168.31.135:8033 | ResourceManager 提供给管理员的访问地址。管理员通过该地址向RM发送管理命令等 |
| yarn.resourcemanager.webapp.address | 192.168.31.135:8088 | ResourceManager对web 服务提供地址。用户可通过该地址在浏览器中查看集群各类信息 |
| yarn.nodemanager.aux-services | mapreduce_shuffle | 通过此配置项,用户可以自定义一些服务,例如Map-Reduce的shuffle功能就是采用这种方式实现的,这样就可以在NodeManager上扩展自己的服务。 |
| yarn.scheduler.maximum-allocation-mb | 2048 | 每个container向RM申请内存的最大值,单位MB。申请值大于此值,将最多得到此值内存。 |
| yarn.nodemanager.resource.memory-mb | 2048 | NodeManager上可以用于container申请的物理内存大小,单位MB。 |
5 . 配置ssh免密登录
因为Hadoop需要通过SSH登录到各个节点进行操作,以免以后集群运算时,频繁提示输入密码。在三个节点上输入如下命令生成秘钥
[root@centos1 ~]# ssh-keygen -t rsa
[root@centos2 ~]# ssh-keygen -t rsa
[root@centos3 ~]# ssh-keygen -t rsa然后一直按回车,直到生成完成。如下图
将两个从节点slave1与slave2上的id_rsa.pub用scp命令发送给master
[root@centos2 ~]# scp ~/.ssh/id_rsa.pub root@192.168.31.135:~/.ssh/id_rsa.pub.slave1
[root@centos3 ~]# scp ~/.ssh/id_rsa.pub root@192.168.31.135:~/.ssh/id_rsa.pub.slave2在master上,将所有公钥加到用于认证的公钥文件authorized_keys中
[root@centos1 ~]# cat ~/.ssh/id_rsa.pub* >> ~/.ssh/authorized_keys 然后将公钥文件authorized_keys分发给每台slave
[root@centos1 ~]# scp ~/.ssh/authorized_keys root@192.168.31.135:~/.ssh/
[root@centos1 ~]# scp ~/.ssh/authorized_keys root@192.168.31.136:~/.ssh/最后在每台主机上,用SSH命令,检验下是否能免密码登录
6 . 从节点配置
从节点配置文件跟主节点保持一致,不需要修改。在步骤(3)中配置了hadoop-env.sh ,yarn-env.sh ,slaves ,core-site.xml ,hdfs-site.xml ,mapred-site.xml ,yarn-site.xml 。把这些配置文件原封不动的复制到从节点的 /user/hadoop/hadoop-2.8.4/etc/hadoop/ 目录下即可
7 . 启动Hadoop
启动操作都在nameNode上完成,启动之前首先将nameNode格式化,执行下面的命令,格式化nameNode
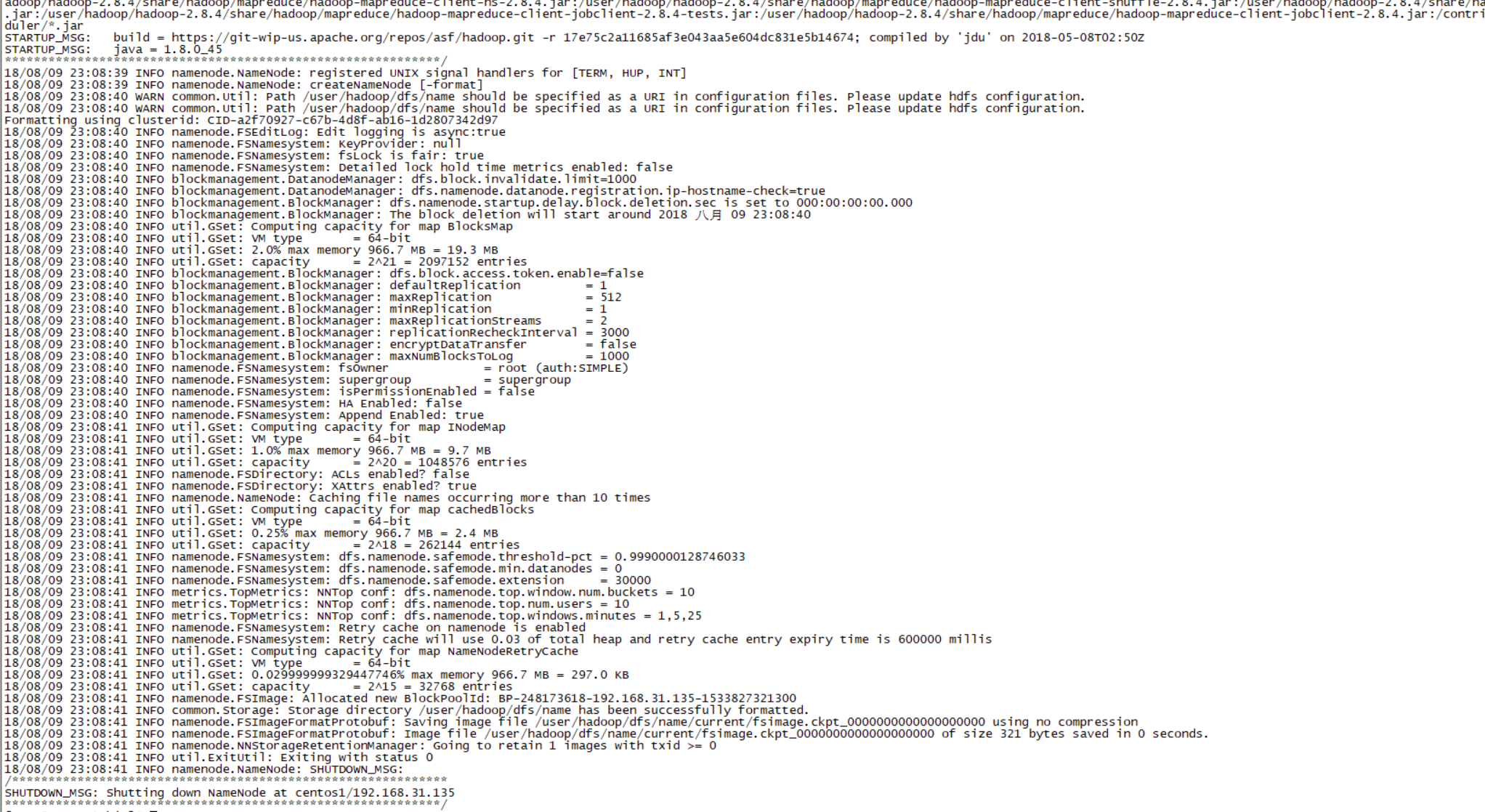
[root@centos1 hadoop]# cd hadoop-2.8.4/bin/
[root@centos1 bin]# ./hadoop namenode –format结果如下,则表示格式化成功
再进入sbin目录,启动Hadoop
[root@centos1 sbin]# ./start-all.sh出现如下结果表示启动成功
[root@centos1 ~]# cd /user/hadoop/hadoop-2.8.4/sbin/
[root@centos1 sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [centos1]
centos1: starting namenode, logging to /user/hadoop/hadoop-2.8.4/logs/hadoop-root-namenode-centos1.out
192.168.31.136: starting datanode, logging to /user/hadoop/hadoop-2.8.4/logs/hadoop-root-datanode-centos2.out
192.168.31.137: starting datanode, logging to /user/hadoop/hadoop-2.8.4/logs/hadoop-root-datanode-centos3.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /user/hadoop/hadoop-2.8.4/logs/hadoop-root-secondarynamenode-centos1.out
starting yarn daemons
starting resourcemanager, logging to /user/hadoop/hadoop-2.8.4/logs/yarn-root-resourcemanager-centos1.out
192.168.31.137: starting nodemanager, logging to /user/hadoop/hadoop-2.8.4/logs/yarn-root-nodemanager-centos3.out
192.168.31.136: starting nodemanager, logging to /user/hadoop/hadoop-2.8.4/logs/yarn-root-nodemanager-centos2.out也可通过 jps 命令查询状态 ,nameNode上结果
[root@centos1 sbin]# jps
10902 Jps
10281 NameNode
10478 SecondaryNameNode
10638 ResourceManagerdataNode上结果
[root@centos2 ~]# jps
10437 Jps
10300 NodeManager
10191 DataNode本地打开 http://192.168.31.135:50070
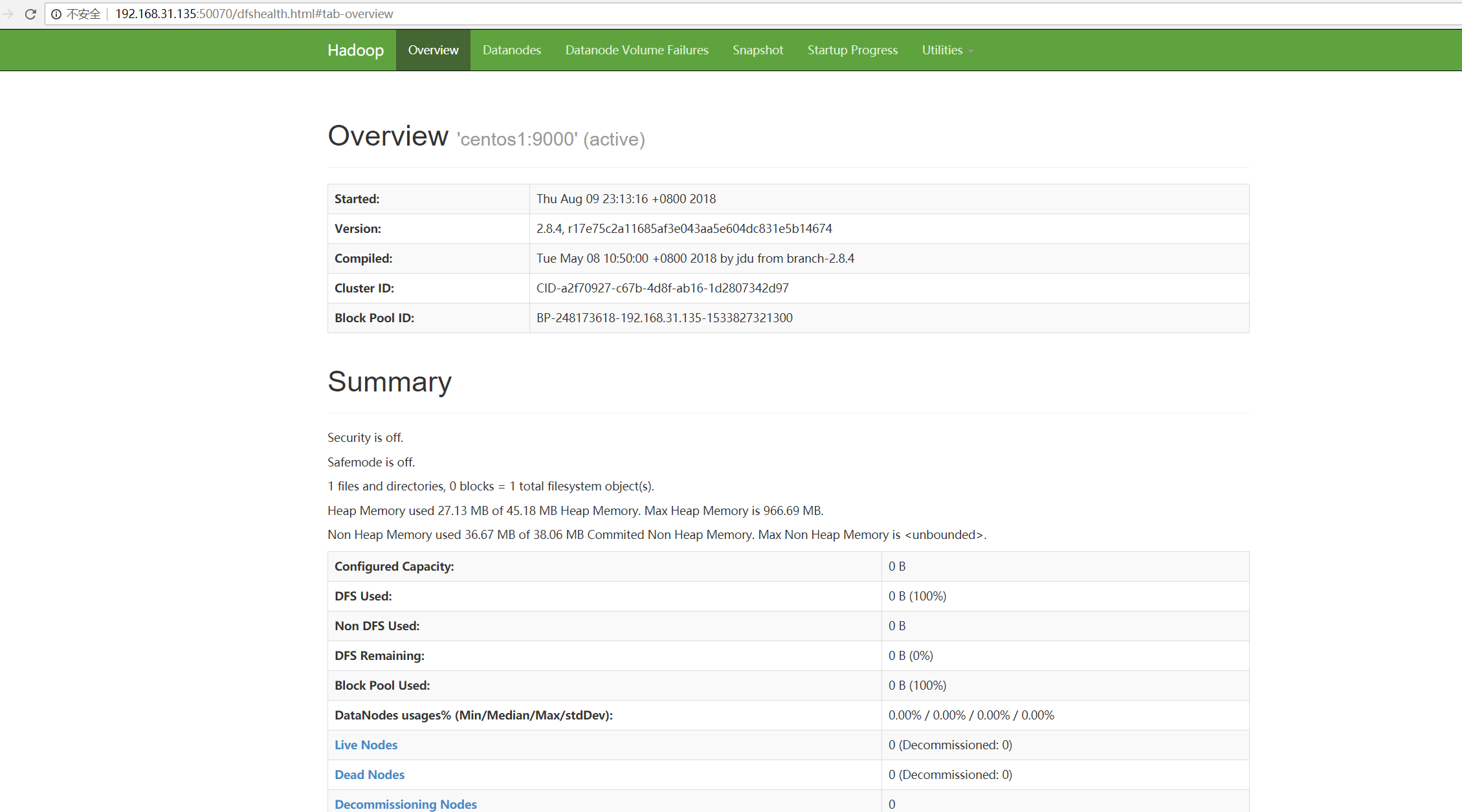
本地打开 http://192.168.31.135:8088/cluster
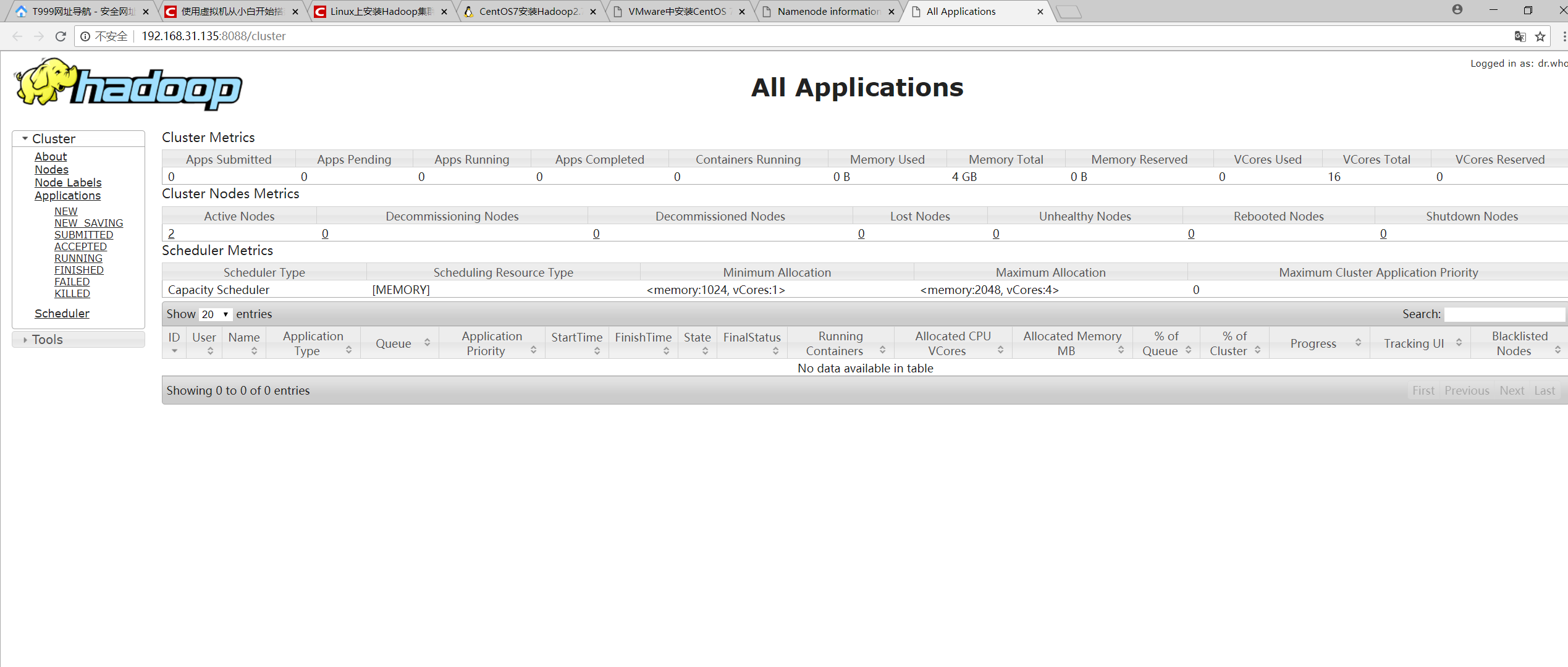
至此,Hadoop集群搭建完毕,并且成功启动。



