最近公司培训,讲到了有关于长连接的负载均衡解决方案,确有体会,故此记录一下。在之前做负载均衡一般针对的是短连接,短连接的场景在实际应用中非常普遍。浏览器中大部分的请求都是短连接,例如用户登录,注册。商城的订单,付款等功能都属于短连接。短连接的特点就是无状态,连接时间短,长则三四秒,短则几毫秒。短连接的负载均衡很容易解决,开源中间件也比较多,例如nginx,F5等。而长连接的负载均衡解决方案则比较少了,主要原因是长连接相对于短连接来说应用面比较窄。一般是定制化需求会使用长连接。而生活中长连接作为普遍的应用就是直播系统了,近几年直播这种娱乐方式也越来越受到年轻人的喜爱,虎牙,斗鱼等直播平台如雨后春笋般涌现。我所在的公司主要从事安防行业,其中最为普遍的业务是摄像头的录像,在城市中每个街头,小区,公交地铁上的摄像头都会接入到公安体系中,其中录像不但能实时播放而且还会保存到服务器中,方便公安人员破案时可以随时查看录像。由于摄像机是24小时录像的,所以在这种场景下摄像机是使用长连接,而且一旦摄像机和某个服务器节点建立连接,就会长期和这个服务器保持着连接。一个城市的摄像头成千上万,后台不但需要考虑并发,还要考虑负载均衡。传统的负载均衡算法如轮询,哈希,随机等算法并不适用于长连接的一些业务场景。这里长连接可比作一个持续进行的任务,那么长连接的负载均衡就是每个任务的资源调度,最终使每个节点上的资源,均匀的分布在这些任务上。
1.长连接的特点
由于业务场景不同,长连接的特点也不一样。不同的业务场景会有各种各样的特点,需要做定制化需求的开发,这里例举的摄像机长连接特点:
1.每个长连接任务的时间长,短则几天,长则几个月。并且长期占用服务器的资源。
2.每个长连接任务消耗的资源不一样。以摄像机为例,不同规格的摄像机像素不一样。有标清,高清,超清之分。对应的就是流量带宽的区别,有2M,4M,8M之分。因此每个长连接任务占用的资源大小不一样的。
3.长连接任务启动时,初始化较慢,例如需要做认证,或是请求一些接口来获取数据。这样会导致做负载均衡时,并不能实时获取到节点的负载情况,出现几秒钟的延时。
在这些特点下如何做负载均衡呢?短连接的负载均衡算法轮询,哈希,随机,平均负载。如果这些算法能不能直接应用于长连接的业务场景,会出现哪些问题呢?我们先从最简单的特点开始,逐渐递进的去思考这个问题,从无到有的推导出一个针对这些特点的负载均衡算法。上面三个特点以下简称特点一,特点二,特点三。
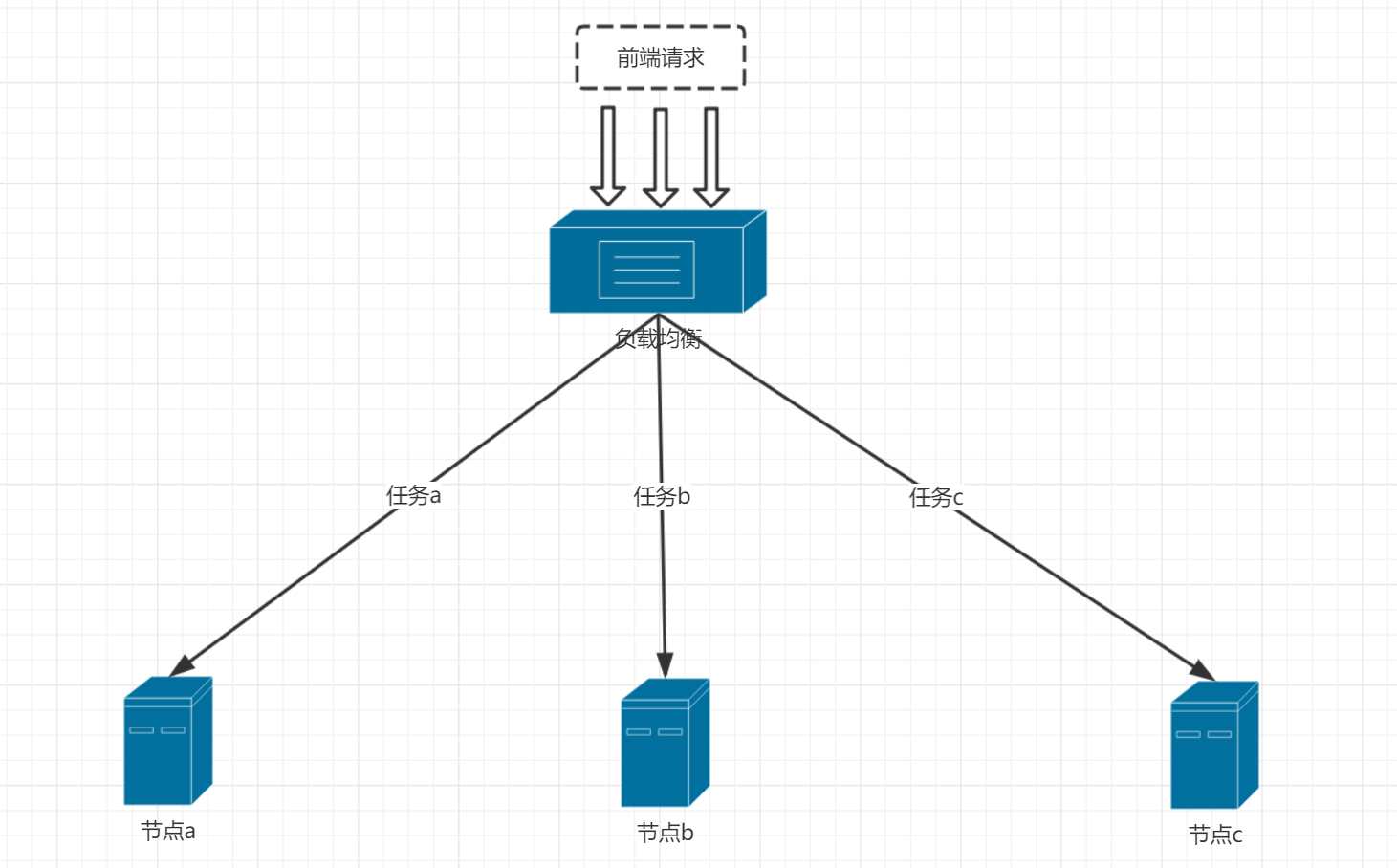
1,满足特点一,不考虑特点二,三。
这种情景下长连接任务只是时间长,但每个长连接任务消耗资源大小一样,启动时无延时。这种场景是最为简单也是最理想的场景,在这种场景下轮询,哈希,随机算法都适用。因为每个任务大小一样,当任务数量够多时就能保证任务是平均分配到节点上的,从而保证了每个节点的负载基本一致,这些算法都能使服务器节点达到较为均匀的负载状态,这种情况根短连接的情况差不多,只是任务时间长一些。如下图
2,满足特点一,二,不考虑特点三
这种场景下任务启动时没有延时。但由于每个任务大小不一样轮询,哈希,随机就也就不再适应了。因为这几种算法适用于请求数量很大,任务大小差别不大的情况。也就是样本数足够大,样本基本一致才能保证这些样本均匀的分布在节点上。但也仅仅只是保证了每个节点上的样本数量均匀分布,倘若每个样本的所占用的资源不一样。那么这种均匀分配实际并不会使服务器的节点能够均匀的负载,达不到负载均衡的效果。那么这样的场景下,只平均负载的算法能够适用与这种场景。平均负载算法是在每次派发任务时,会收到节点反馈过来的负载情况,然后根据每个节点的负载情况,选择负载最小的节点派发任务。下面以图来说明这两种情况,如下图
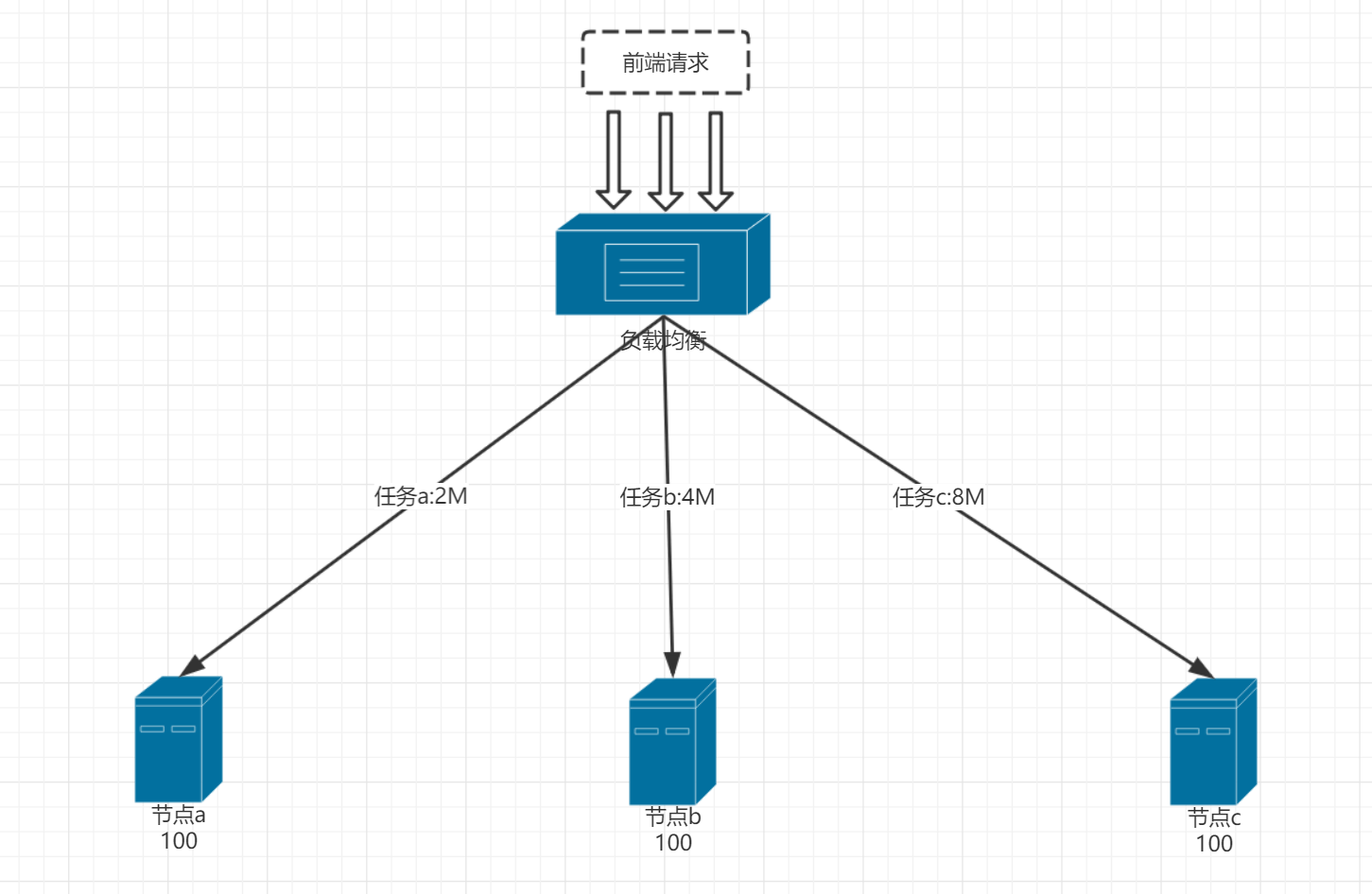
从图上可知,有任务a,b,c分别对应三个摄像机。任务a是2M流量,任务b是4M流量,任务c是8M流量,假设每个节点配置都一样,满载时为100。很明显如果使用轮询节点c的负载肯定会大,这样实际上集群负载并不均衡。但如果使用平均负载,那么负载均衡器在派发任务时会根据节点的负载情况去分发任务,这样最终效果肯定是要比轮询好的
3,满足特点一,二,三
其实在前面两个特点下,我们忽略了一个重要问题。就是可信度问题,也就是特点三带来的问题。在分布式环境中,节点之间通信是不可靠。如果由于网络波动,或是业务场景导致负载均衡器在得到节点反馈过来的负载信息时,这个负载信息可能是存在几秒钟的延时。实际上得到的并不是当前的实时负载情况,而是几秒钟之前的负载情况。如下图:
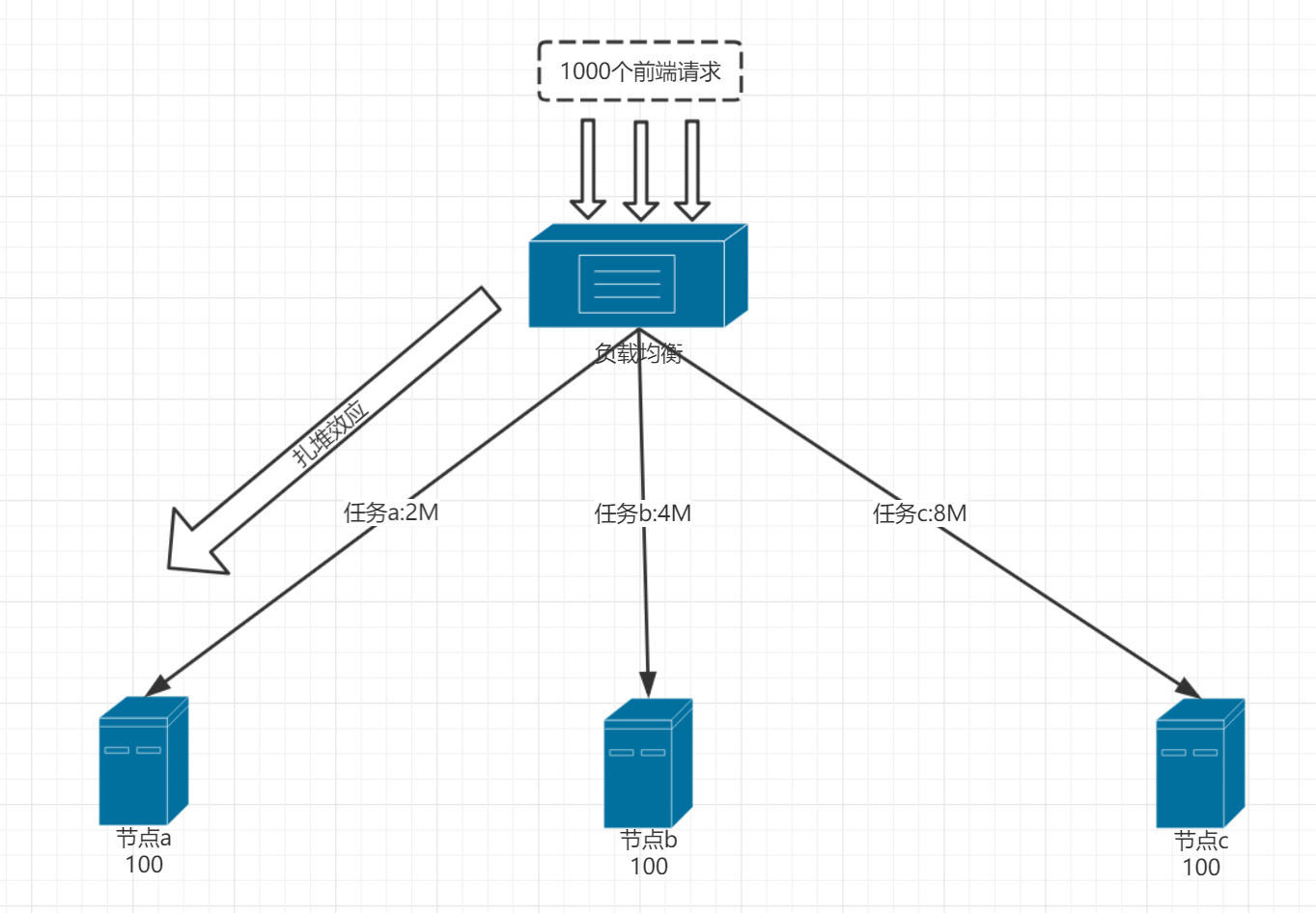
这样会存在一个极大的隐患。假设有1000个请求过来了。根据平均负载的算法得到节点a的负载最低。那么请求理应分发到节点a上,但是由于反馈过来的负载信息是存在延时的,于是在两三秒内得到的结果都是节点a负载最低,那么这1000个请求可能会全部被分发到节点a上。这种现象被称为扎堆效应。这种情况的结果就是节点a扛不住压力宕机。那么由此可见平均负载算法也不适用了。
2.平均负载算法的改进(一)
从上面几种场景可以看出,平均负载算法还是适用性是非常强的,而在第三种场景下如果能得到一个可信度较高的节点当前负载情况,那么就可以继续沿用平均负载算法。那么该如何得到可信的节点负载呢,由前面的分析可知得到的节点负载之所以不可信是因为存在延时,那么我们可以记录节点前三秒,或者是前五秒的每秒节点负载,在
把这些节点负载取平均值作为节点的当前负载。公式如下
$$
m=(m4+m3+m2+m1+m0)/5
$$
m表示当前负载 ,m4,m3,m2,m1,m0分别表示4,3,2,1,0秒前的负载,对于存在延时的系统,这样做法就能在一定程度上得到较为可靠节点的负载情况。但仍然不够准确,在实际生产环境中仍然会出现不均衡的情况,究其原因是因为对前5秒的数据取平均,但实际上,这样计算是不合理的,难道5秒以前的数据和1秒以前的数据对当前结果的影响还是一样的吗?显然不是,应该认为越靠近当前时间的负载值可信度就越高,越远离当前时间的负载值可信度就越低。这样才会越接近于实际。所以上面的公式应该是这样的
$$
m= 0.36m0+0.28m1+0.20m2+0.12m3+0.04*m4
$$
其中m0离当前时间最近,认为m0的可信度最高,所以给了36%的权重,而m4离当前时间最远,可信度最低,所以给了4%的权重。当然这里的权重应根据实际情况或经验设置值,根据这个公式算出的当前节点的负载值更能反应出节点的真实负载情况
3.平均负载算法的改进(二)
上面两个公式是在得到几秒内的负载值然后计算出加权平均值确能在一定程度上反应节点的负载情况,但是这个种方法需要多次记录节点的负载信息,还比较麻烦。那有没有更好的方法呢,答案是有的,其实只需记录上一秒的节点负载情况,然后再获取当前节点负载,在这段时间段内对节点内,节点负载对时间取积分即可。这个方法是根据自动控制原理中的PID算法得到的那么上面节点负载的计算公式可得如下
$$
m=m0+\frac{\int_0^t{(m0-m1)*t},{\rm d}t}{D}
$$
公式中m表示计算得到的负载值,m0表示当前获取到的节点负载,m1表示上一秒获取到的节点负载,参数D是可信度系数,表示上一秒的节点负载值对当前负载值的影响程度,越大表示影响越小,这个值可根据实际情况设置。这样既只需要维护上一秒的节点负载值,减小了成本,又能得到相对准确的当前节点负载值。
4.负载均衡健康状态
负载均衡的健康状态如何定义呢?如果任务均匀的分布在各个节点上,就称集群的负载均衡状态是健康的,否则就是亚健康或者说是不健康的。在前面,我们衡量集群各个节点的负载情况时,总是以节点已经负载的量去评定的,例如集群有3个节点,每个节点的满载量为100,当前每个节点放负载为40,那么就可以认为集群达到了比较均匀的负载均衡状态。但这是理想状态,实际生活中,集群的节点配置是不可能完全相同的,有些节点可能是后加入的那配置可能会高一些,有些节点是之前用了好几年的,为了节省成本继续利用起来配置自然会点一些,所以集群各个节点是完全不一样的。如下图所示a,b,c三个节点,a节点放满载量为60,b节点的满载量为140,c节点的满载量为100,这样如继续以节点已负载的量去衡量的话,假设当前每个节点放负载仍为40,就会得到如下的情况
| 节点 | 节点a | 节点b | 节点c |
|---|---|---|---|
| 负载状态 | 40/60 | 40/140 | 40/100 |
这样明显可以看出节点b还有很大的富余,因此通过节点当前的负载量,去判断集群的负载均衡状态是不科学的,这里可以换一种思路,以每个节点的剩余量作为衡量标准,这样上面那个例子中,节点a的富余是20,节点b的富余是100,节点c的富余是60,这样得到的就是如下的情况
| 节点 | 节点a | 节点b | 节点c |
|---|---|---|---|
| 富余量 | 20 | 100 | 60 |
在负载均衡服务器派发任务时,不再是以节点负载最小的节点作为派发对象,而是以节点富余最大的节点作为派发对象,这样就能使节点的负载尽可能的均衡。这里衍生出一个公式可计算集群负载均衡的状态,首先计算出集群各个节点的负载富余的平均值
$$
n=\frac{(n0+n1+n2)}3
$$
然后求方差
$$
y=(n0-n)^2+(n1-n)^2+(n2-n)^2
$$
这样计算得到的方差结果,如果结果越小则说明集群负载越均衡,状态越健康,越大则说明越不均衡,集群的负载均衡处于一个相对不健康的状态



