最近几天研究了下一致性哈希算法,总算是搞明白它是怎么一回事了,这里记录一下自己的理解。一致性哈希算法主要是针对分布式缓存系统的算法。要想搞清楚一致性哈希的的优缺点,那就必须从它的发应用场景说起,也就是为什么分布式缓存中要使用一致性哈希算法,传统的做法有什么缺点,会带来什么问题。首先来看一下传统的做法,我们知道缓存在大型的应用系统中的地位是很重要的,它能有效的减少数据库的访问次数,从而减少IO提高系统的反应速度,得到较好的用户体验。因此一般应用系统都会使用Redis或者Memcached等中间件做缓存。而在数据量比较大的情况下,一台缓存服务器往往是不足以扛住大数据量的压力,所以会搭建一个缓存服务器的集群。缓存数据就会由原来在一台服务器上变为分布在一个缓存集群上,那数据怎么才能均匀的分布在集群中的节点上呢。又该怎么快速去定位待查询的数据在哪台缓存服务器上呢。

1 . 实际场景
现在假设有三台缓存服务器节点,当有查询请求来时,首先会去缓存中查找数据,最简单的做法就是轮询三个节点,然后找到待查询的数据,如果数据没找到就到数据库中去查询,这种做法是大多数人最直观的做法。但这种做法的效率很低,需要去轮询服务器,不利于横向拓展。因此就出现了哈希算法去定位服务器,假设有4条数据,那么这4条数据是怎么分布在缓存中的呢?传统的取模哈希算法相对简单,就是用数据的key对服务器的个数取模,在这个例子中再假设4条数据的key分别是1,2,3,4。服务器的编号分别是A,B,C。那么数据1,数据4是在节点B上,数据2在节点C上,数据3在节点A上。如下图所示:
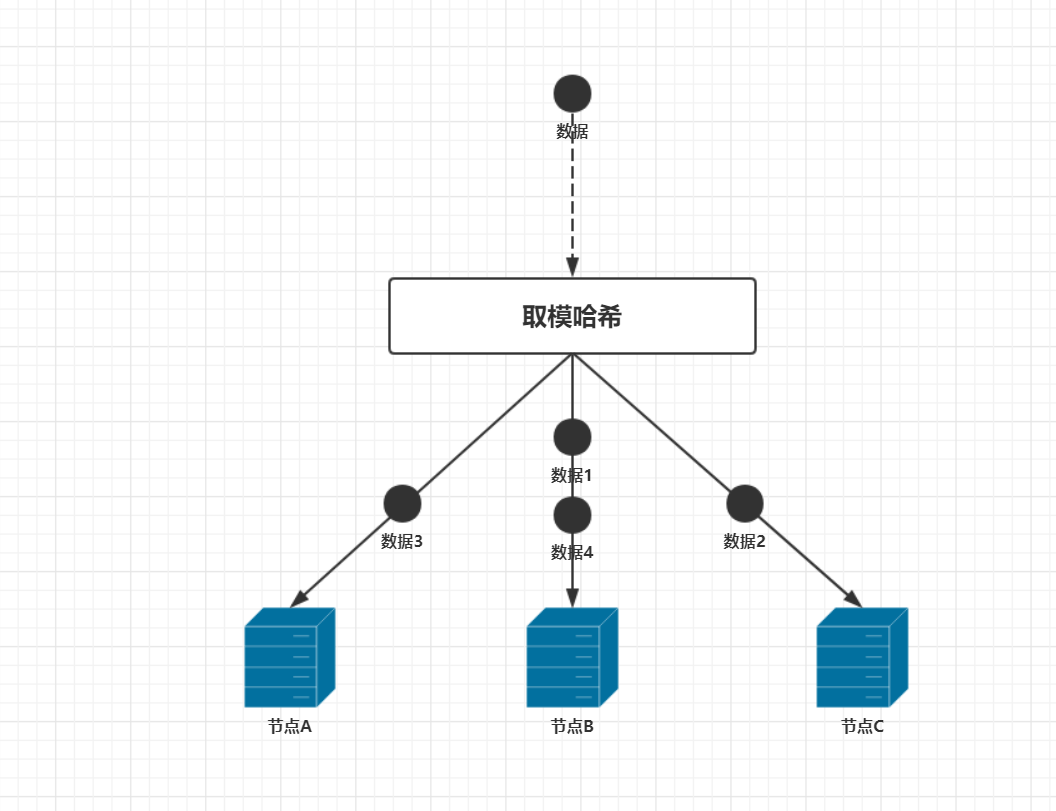
这里数据取模后的值为0,1,2对应于服务器A,B,C。在查询数据的时候,就能快速的得到这条数据所在的服务器编号,从而大大提高了查询速度。这种方式比起前一种方式优势明显,但在实际环境中却有很大的问题,因为我们忽略了一个问题,那就是这是一个分布式环境。分布式环境中最让人头疼的问题就是环境是不稳定的,随时都有可能会有节点宕机,在刚刚那个例子中,如果有一个节点挂机,数据分布会是怎么样的,假设节点C宕机,还剩下节点A,B在正常运行。此时服务器数量是2,那么数据的分布应该是这样的,数据2和数据4在节点A上,数据1和数据3在节点B上,如下图
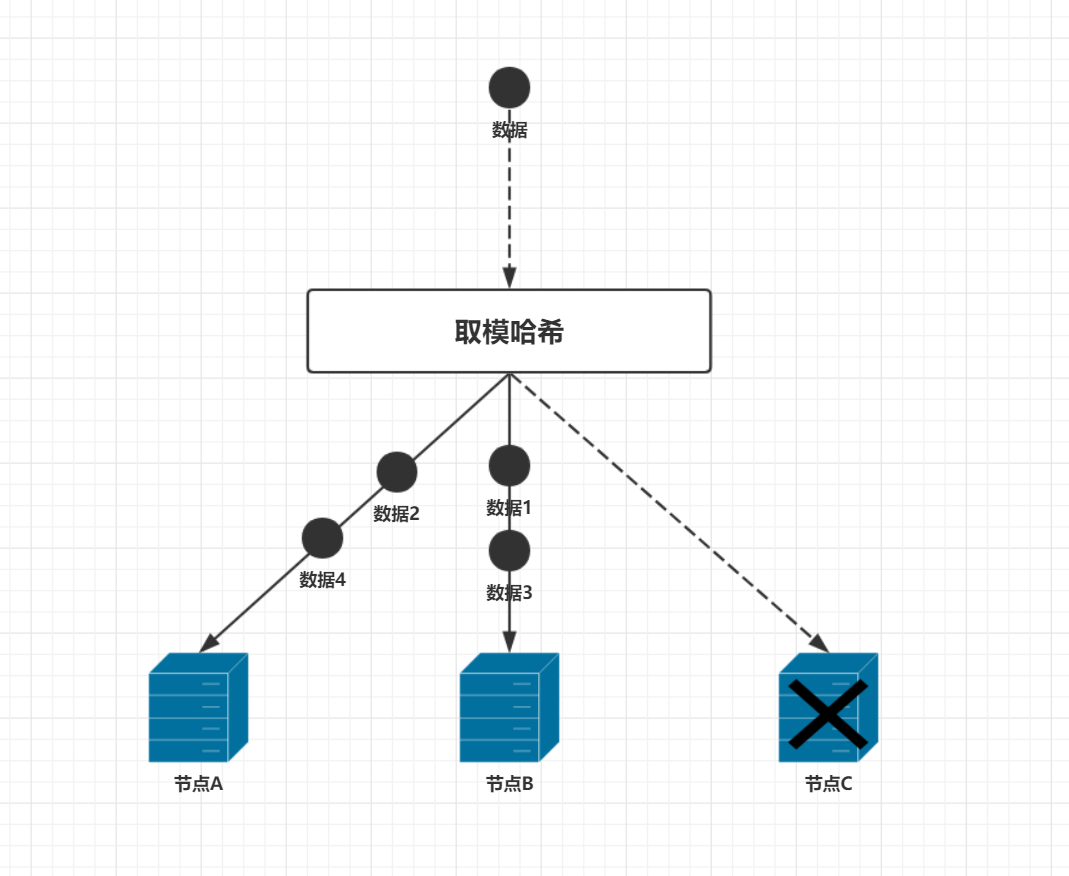
由此可见,大部分数据都被重新定位到新的服务器上了。这种情况会带来一个很大的隐患,就是当系统运行时,某个缓存节点突然宕机,查询数据时,首先会去缓存中查找这条数据,如果这些数据刚好在这个宕机的节点上,导致没有查到数据,故只能去数据库查询数据。由于短时间内大量的数据缓存在同一时间失效,数据库将面临大量的IO请求,此时应用系统和数据库都面临着巨大的压力。如果由于大量请求导致应用服务器的某个节点宕机,这些请求又会负载到其他服务节点,巨大的请求量同样会导致其他服务节点宕机,。最终导致雪崩式的宕机,拖垮整个系统。如果发生这种情况,那可能是灾难性的。因此要尽量避免这种情况的发生。这种情况在架构设计时应该考虑到采取一定的方式应对。这里就不做深入讨论了,同样在应用系统用户量增加的时候,缓存集群可能不足以支撑查询压力,因而需要增加缓存节点来提高系统的性能。如果往缓存集群中动态的增加一个节点同样会导致类似的情况,大部分的数据需要重新定位。因此需要一种更好的算法去解决这个问题,一致性哈希算法就应运而生了。
2 . 一致性Hash概述
一致性哈希把数据映射到0到2^32次方个哈希桶的空间,形成一个哈希环。通俗的理解,就是在一个圆环有很多个整数点,这些点从0开始,一直到2的32次方结束,然后通过哈希算法将缓存服务器映射到这个环上。那么在刚刚那个例子中服务器A,B,C映射到哈希环上会是什么样子呢?一般我们使用服务器的ip地址,作为哈希的key值,(这个key值可以自己定义,前面的例子中是使用的服务器编号),通过 Hash(服务器ip)%2^32 得到哈希值,那么3个服务器节点通过哈希算法计算后,在哈希环上是这样分布的
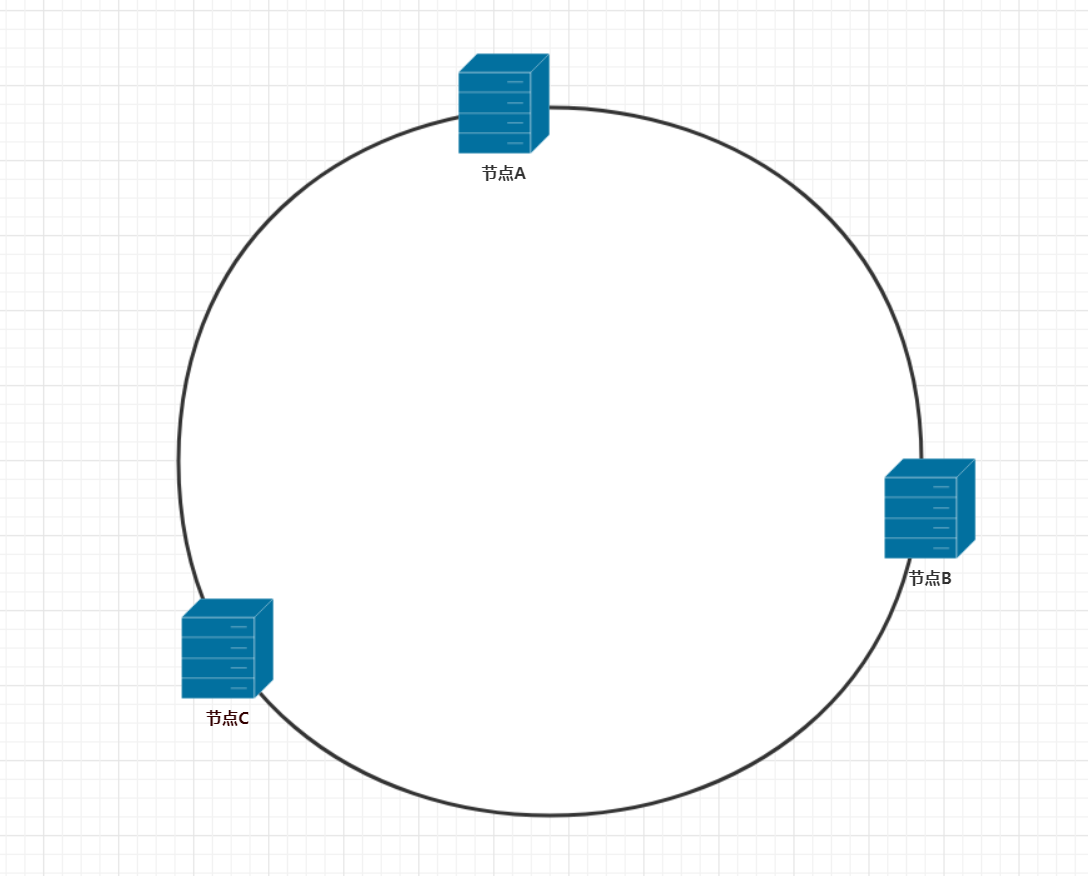
当有数据请求时,一致性哈希是怎么存储数据的呢?这需要在数据存储的时候,把数据的id作为哈希的key值,以同样的公式计算出哈希值,即通过 Hash(数据id)%2^32 公式得到哈希值,这里假设有6条数据,在哈希环得到如下的数据分布图。
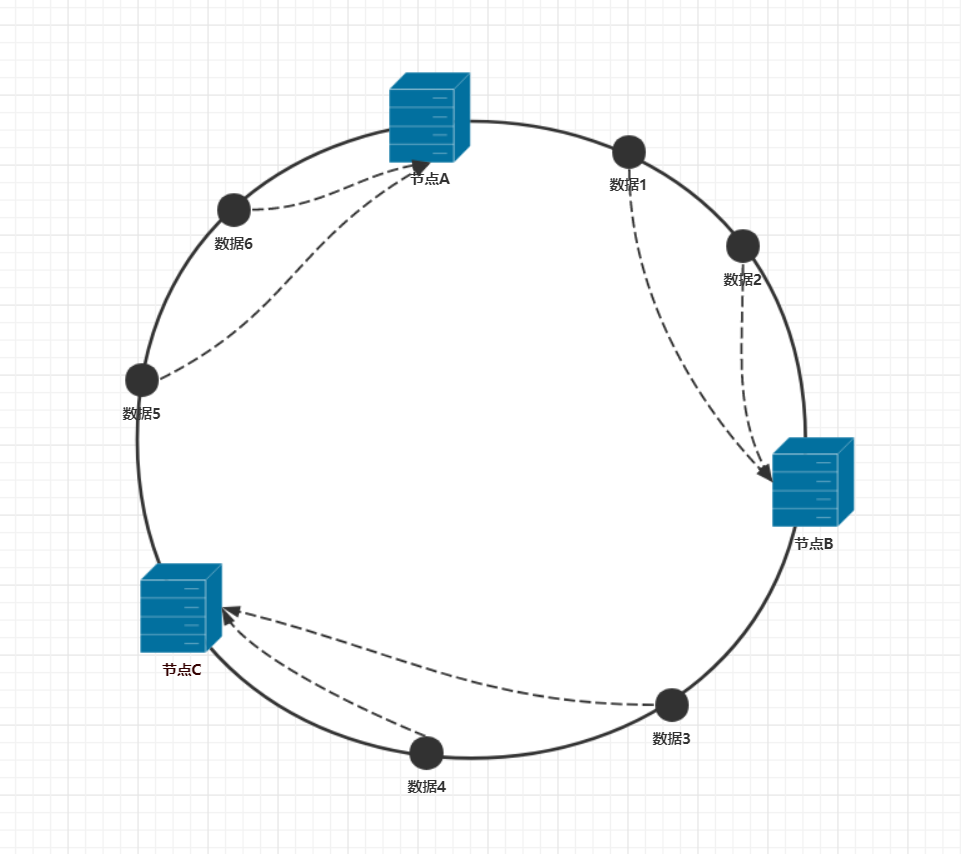
这里数据的分布和前面通过取模方式区别比较大,前面的方式数据id取模后,会直接得到服务器节点的编号(因为取模后的值就是服务器的编号),于是便确定到这条数据在哪个节点上。而一致性哈希计算出哈希值后,数据离散的分布在整个哈希环上,通过哈希值还不能确认这条数据分布在哪个节点上。这里还需要一个约定,就是沿顺时针或是逆时针方向,数据会被存储到这个方向上遇到的第一个节点中。例如上图中,沿顺时针方向走,数据1,2遇到的第一个节点是节点B,所以数据1,2会被存储在节点B上,同理数据3,4存储在节点C上,数据5,6存储在节点A上。一致性哈希就是通过这种方式定位数据的。
3 . 一致性哈希的优点
在前面的阐述中通过简单的取模方式,如果服务器数量发生变化,容易引发集群的雪崩。那么一致性哈希能很好的解决这个问题吗?再来模拟一遍服务节点数量发生变化的情况下,一致性哈希会是怎样的结果。
(1) . 节点宕机
上图中假设节点C宕机了,那么数据的分布是变成什么样的呢。由于哈希算法跟节点数量没有关系,那么数据在哈希环上的位置不会改变。于是可得的如下图的数据分布图
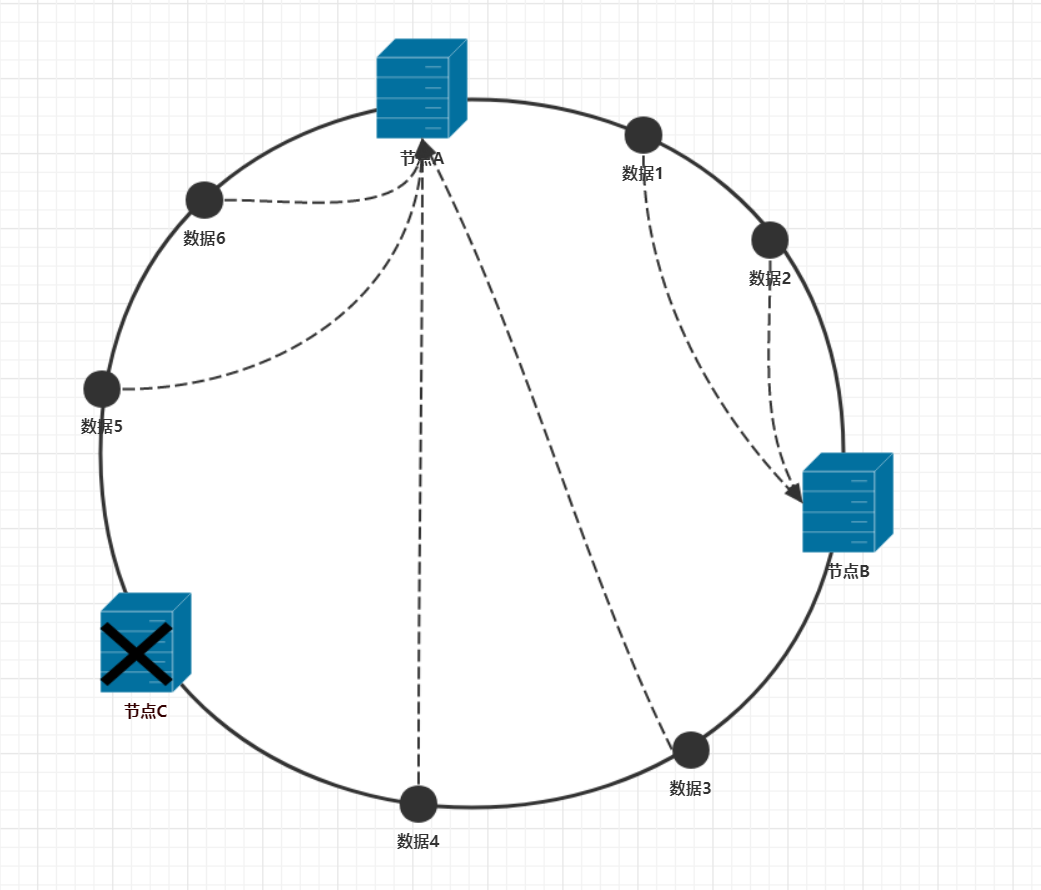
沿顺时针方向走,可得数据1,2存储在节点B上,而数据3,4,5,6都存储在节点A上。通过和正常情况下的数据分布比较,可以看出来,在节点C宕机的情况下,只有节点C上的数据需要迁移。而其他数据都不会受到影响。
(2) . 节点加入
如果集群想动态的增加一个缓存节点,以提升性能,那么在一致性哈希下,集群会受到什么影响呢?现在假设在数据3和数据4之间增加一个节点x,数据分布会得到如下图的效果。
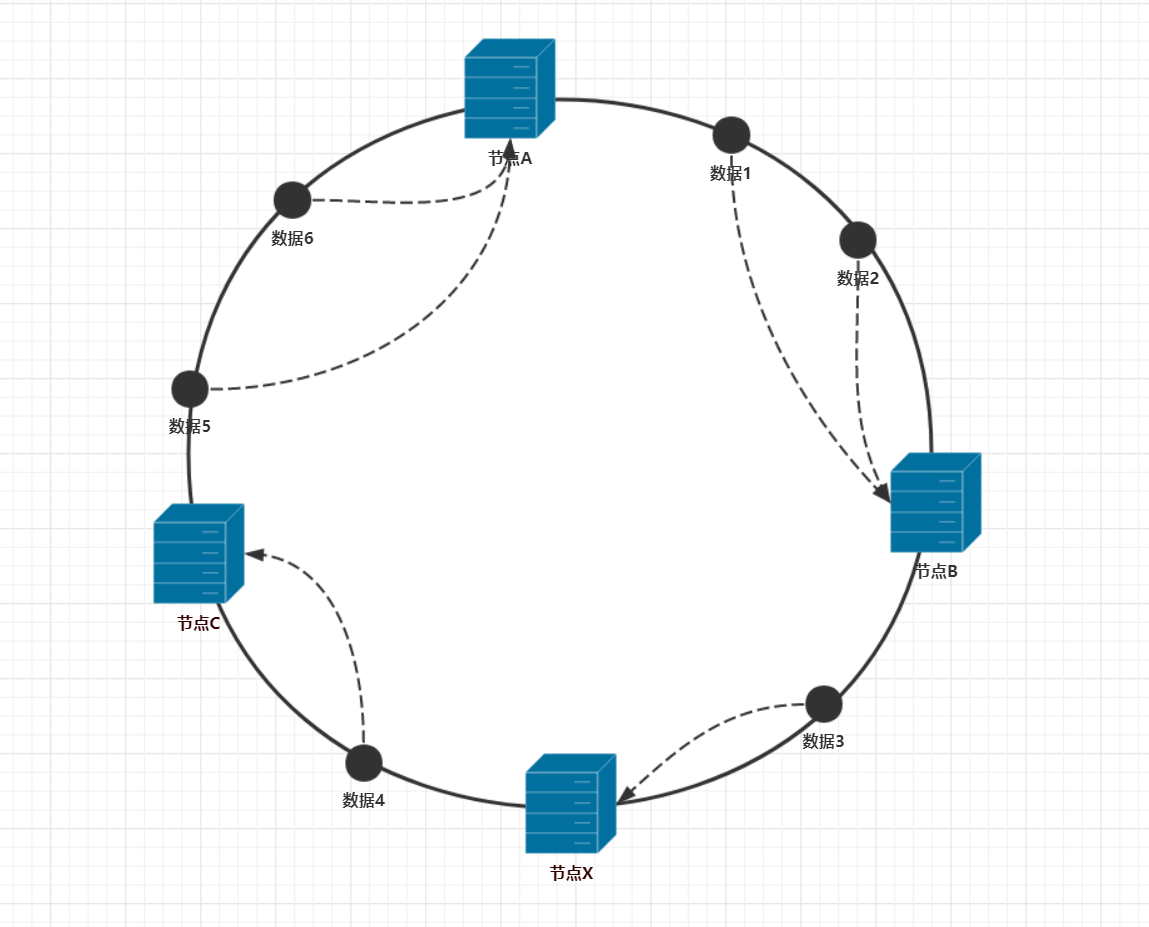
从图中可以看出,除了数据3会被迁移到节点x以外,其他数据都不会受到影响。通过和节点宕机的情况下比较还可以知道,增加节点时,需要迁移的数据比节点宕机时要少。而且集群节点越多,受影响的数据占比就越少,这说明一致性哈希比较适用于集群的横向扩展。
3 . 数据倾斜
在前面的讨论中,服务器是被均匀的映射在哈希环上了,但是理想很丰满,现实很骨感。实际映射到哈希环上的节点并不如我们想象的那么美好,而往往是下面这般模样
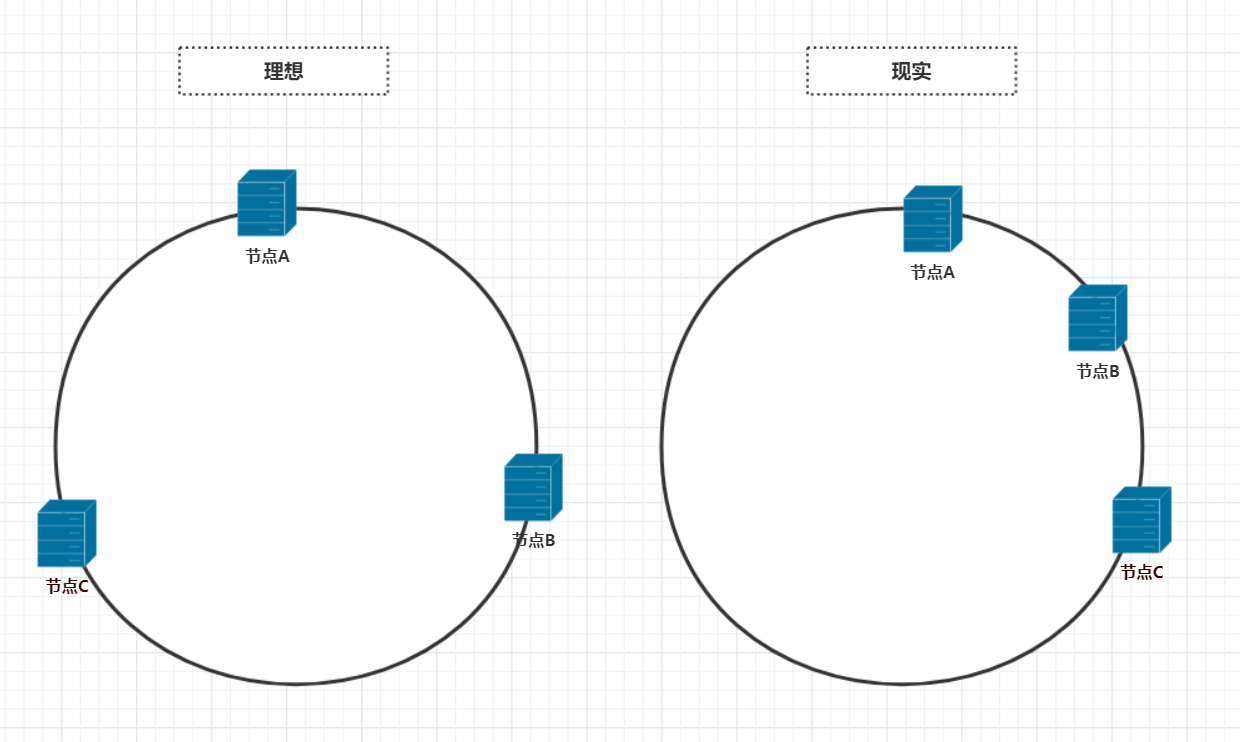
很明显,如果节点在哈希环上分配不均匀,那么节点A负载的数据量将远远大于节点B,节点C。这可能导致节点A由于承受较大的负载而宕机,如果节点A宕机,那么数据量会积压到节点B上,然后节点B宕机,然后节点C,然后雪崩了。这种情况叫做哈希环的倾斜,这些专业名称总会不明白的人望而生畏,其实不过是给一件简单的事情起了个名字。那么哈希环倾斜的问题该怎么解决呢?
4 . 虚拟节点
从上面的图可以看出,如果哈希函数本身没问题的话,出现哈希环倾斜的原因,是因为节点。如果节点数足够多的话,就可以让节点尽可能离散的分布在哈希环上。但实际情况中,就只有3个节点怎么办呢?一致性哈希算法种使用虚拟节点解决了这个问题。理解起来也简单,就是节点数不够多嘛,那么通过虚拟出足够多的节点,不就能让节点均匀的分布在哈希环上了吗。那么虚拟节点是怎么得到的呢,既然是虚拟节点,那说白了就是个假节点,是通过实际节点复制而来的。说专业点就叫做虚拟,比如把节点A虚拟出两个节点叫节点A-1,节点A-2。同样节点B和节点C也各虚拟两个节点那么就会得到如下的分布图了
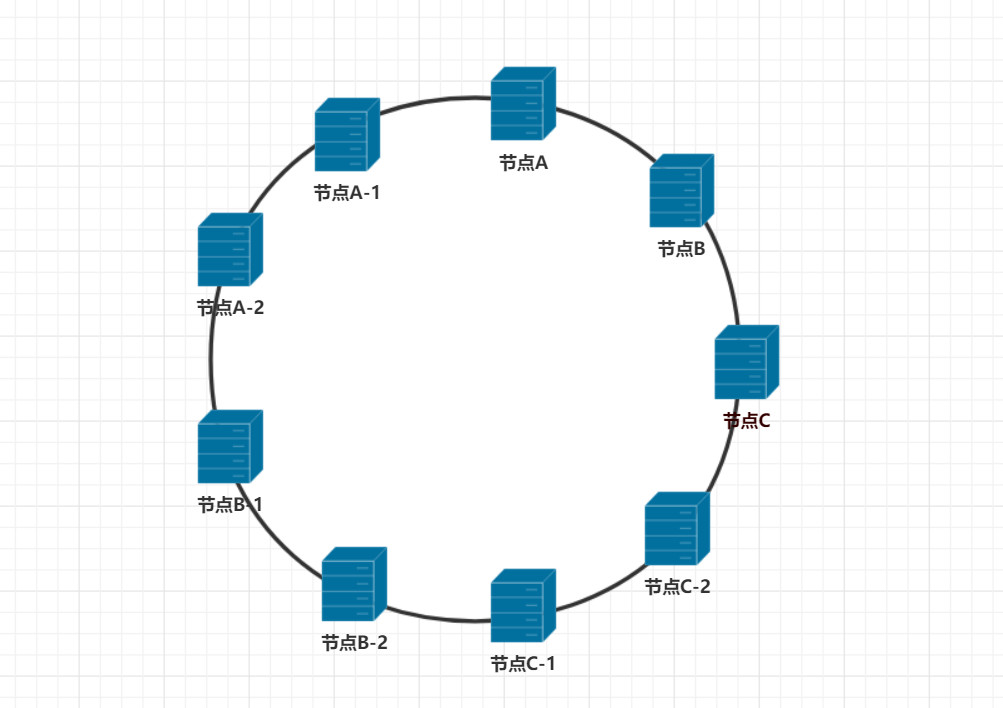
这样在哈希环上,节点就是均匀分布的,很好的解决了由于节点分布不均匀而带来的数据倾斜问题。这里节点A-1和节点A-2是节点A虚拟出的两个节点,那么实际上存储在节点A-1和节点A-2上的数据是存储在物理节点A上的。如果虚拟节点在哈希环上分布还是不均匀,可以继续虚拟出更多的节点。虚拟节点越多,节点在哈希环上就会分布的越均匀,哈希环倾斜带来的影响也会越小。
一致性哈希基本解决了在P2P环境中最为关键的问题——如何在动态的网络拓扑中分布存储和路由。每个节点仅需维护少量相邻节点的信息,并且在节点加入/退出集群时,仅有相关的少量节点参与到拓扑的维护中。所有这一切使得一致性哈希成为第一个实用的DHT算法。



